
はじめに
本稿では、OpenAIが2025年8月28日に発表した、新しい音声対話(Speech-to-Speech)モデル「gpt-realtime」と、その基盤となる「Realtime API」の正式リリースに伴うアップデートについて詳しく解説します。この発表は、AIが音声で人間と対話する技術の新たな一歩を示すものであり、特にAIアシスタントやカスタマーサポートなどの分野で大きな影響を与える可能性があります。
参考記事
- タイトル: Introducing gpt-realtime and Realtime API updates for production voice agents
- 発行元: OpenAI
- 発行日: 2025年8月28日
- URL: https://openai.com/index/introducing-gpt-realtime/
要点
- OpenAIは、新しいSpeech-to-Speechモデル「gpt-realtime」をリリースした。これは、従来のモデルよりも音声品質、知能、指示追従性、外部ツール連携の精度が向上している。
- Realtime APIが正式に利用可能となり、MCPサーバーサポート(外部ツール連携の簡略化)、画像入力、SIPによる電話連携、再利用可能なプロンプトなどの新機能が追加された。
- 従来の「音声認識→テキスト処理→音声合成」という複数モデルの組み合わせではなく、単一のモデルで音声を直接処理・生成することで、低遅延でより自然かつ表現力豊かな対話を実現する。
- これにより、開発者はより高性能で信頼性の高い、本番環境向けの音声エージェント(AIアシスタントや自動応答システムなど)を構築できるようになった。
- 価格は従来モデルより20%引き下げられ、開発者がより利用しやすくなった。
詳細解説
新モデル「gpt-realtime」とは? 〜より自然で賢い対話の実現〜
今回の発表の最大の目玉は、新しいSpeech-to-Speechモデルである「gpt-realtime」です。
まず前提として、従来の音声AIの多くは、複数の異なるモデルを組み合わせるパイプライン方式を採用していました。具体的には、①ユーザーの話した声をテキストに変換する「音声認識(Speech-to-Text)」、②テキストを解釈して応答文を生成する「大規模言語モデル(LLM)」、③生成されたテキストを音声に変換する「音声合成(Text-to-Speech)」という3つのステップを踏みます。この方式は各要素技術の組み合わせで機能しますが、それぞれの変換処理で遅延が発生したり、声のトーンや感情といった非言語的なニュアンスが失われやすいという課題がありました。
一方、「gpt-realtime」が採用するSpeech-to-Speechは、単一のモデルで音声入力を直接処理し、音声応答を生成します。これにより、中間のテキスト変換を省略できるため、遅延が大幅に削減され、笑い声や間の取り方といった音声の細かなニュアンスを保ったまま、より自然で表現力豊かな対話が可能になります。
「gpt-realtime」は、主に以下の4つの点で従来モデルから大きく性能が向上しています。
音声品質の向上
人間同士の会話のような自然さを実現するため、イントネーションや感情、話すペースなどが重要になります。「gpt-realtime」は、より高品質で自然に聞こえる音声を生成できるように訓練されています。さらに、「早口でプロフェッショナルに話してください」や「共感的にフランス語訛りで話してください」といった、話し方に関する細かい指示(プロンプト)にも従うことができます。
また、このモデルの性能を最大限に活かす新しい声として、「Marin」と「Cedar」が追加されました。さらに、既存の8つの声についても、これらの改善の恩恵を受けるようアップデートが行われています。
知能と理解力の向上
「gpt-realtime」は、音声に含まれる情報をより高い精度で理解できます。例えば、会話中の笑い声のような非言語的な合図を捉えたり、文の途中で言語が切り替わっても(例:日本語と英語の混在)シームレスに対応したりできます。また、内部評価によると、スペイン語、中国語、日本語、フランス語などにおいて、電話番号や製品番号といった英数字のシーケンスをより正確に聞き取る性能が向上しています。
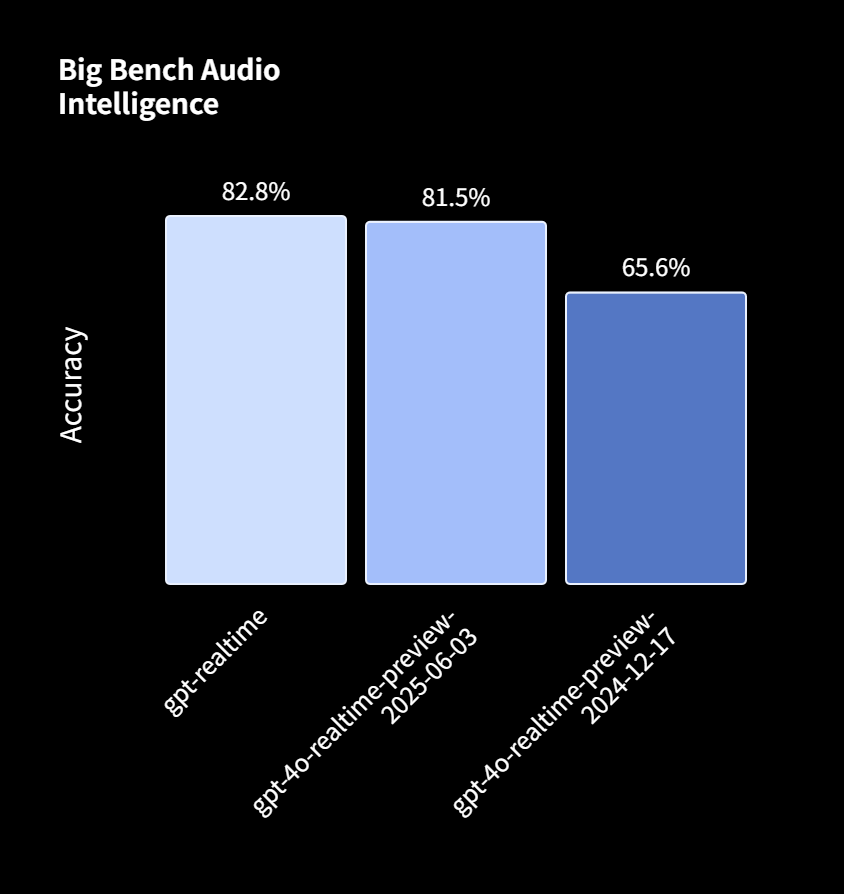
Big Bench Audio評価では、「gpt-realtime」は82.8%の精度を達成し、2024年12月の前モデルの65.6%を大幅に上回る結果となりました。
指示追従性の向上
音声エージェントを開発する際、開発者はモデルに対して「特定の状況で何を言うべきか」「どのような振る舞いをすべきか」といった指示を与えます。「gpt-realtime」は、これらの開発者からの指示をより忠実に守るように改善されており、細かな指示でもモデルの振る舞いに反映されやすくなりました。これにより、例えばカスタマーサポートで免責事項を正確に読み上げる、といったタスクの信頼性が向上します。
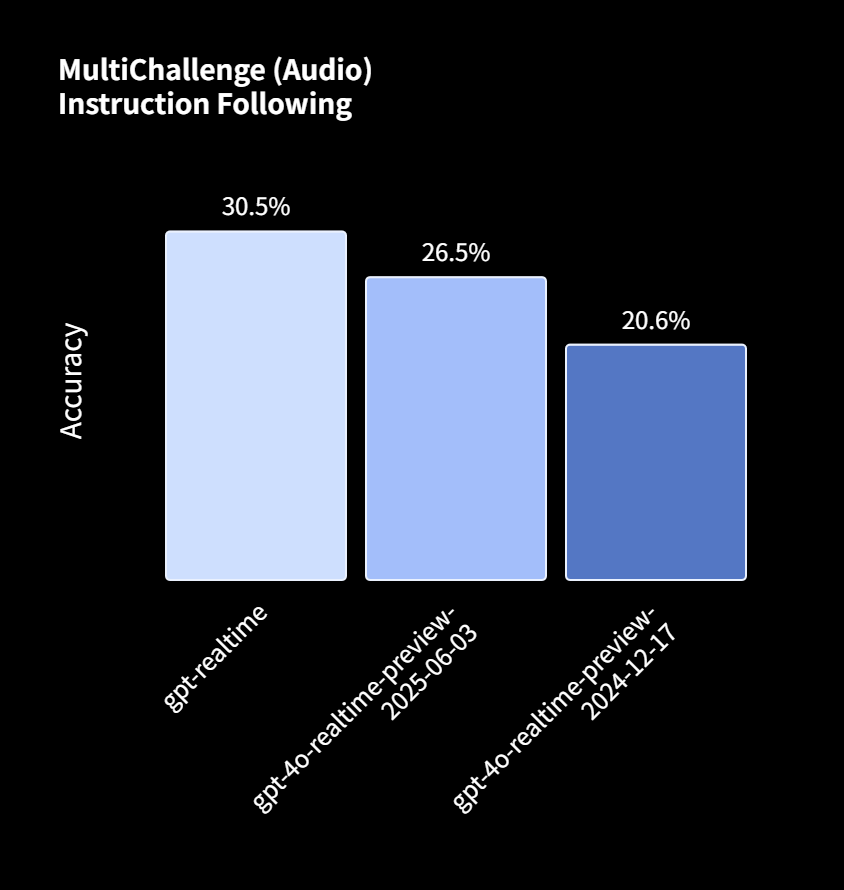
MultiChallenge Audio評価では、「gpt-realtime」は30.5%の精度を達成し、2024年12月の前モデルの20.6%から大幅に改善されました。
関数呼び出し(Function Calling)の改善
音声エージェントを実用的にするためには、外部のデータベースを検索したり、予約システムを操作したりといった「ツール」を使う能力が不可欠です。これを実現するのが関数呼び出し(Function Calling)機能です。「gpt-realtime」は、①適切な関数を呼び出す、②適切なタイミングで呼び出す、③適切な引数(情報)を渡して呼び出す、という3つの側面で性能が向上し、より複雑なタスクを正確に実行できるようになりました。
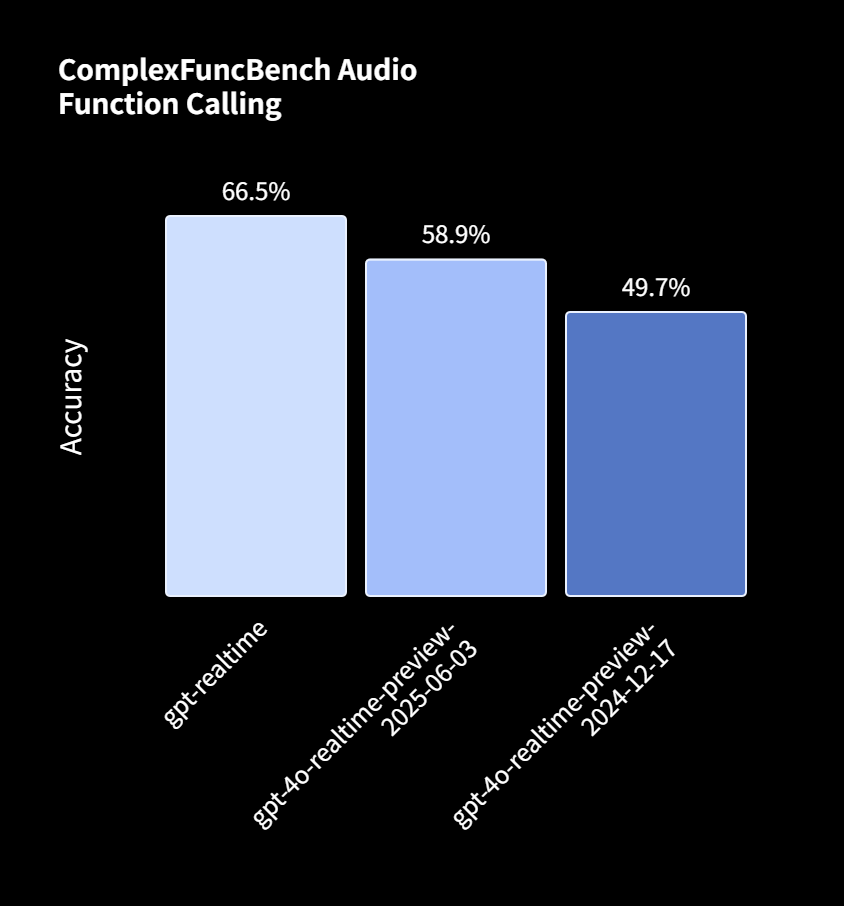
ComplexFuncBench Audio評価では、「gpt-realtime」は66.5%の精度を達成し、2024年12月の前モデルの49.7%から大幅に向上しました。
また、非同期関数呼び出し機能も改善されました。時間のかかる関数呼び出しがセッションの流れを妨げることがなくなり、モデルは結果を待つ間も流暢な会話を継続できるようになります。この機能は「gpt-realtime」にネイティブで搭載されているため、開発者がコードを更新する必要はありません。
2. Realtime APIの主な新機能
「gpt-realtime」の能力を最大限に引き出すため、開発者向けのRealtime APIにも強力な新機能が追加されました。
MCPサーバーサポート
MCP(Model Context Protocol)は、外部ツールとの連携を容易にするための仕組みです。従来、AIエージェントに新しいツール(例:決済システム、顧客管理システム)を連携させるには、個別の開発が必要でした。MCPに対応したことで、APIセッションの設定でMCPサーバーのURLを指定するだけで、そのサーバーが提供するツール群をAIが自動的に呼び出せるようになります。これにより、エージェントの能力拡張がより簡単かつ迅速に行えるようになります。
// POST /v1/realtime/client_secrets
{
"session": {
"type": "realtime",
"tools": [
{
"type": "mcp",
"server_label": "stripe",
"server_url": "https://mcp.stripe.com",
"authorization": "{access_token}",
"require_approval": "never"
}
]
}
}
画像入力
今回のアップデートで特に注目すべき機能の一つが、画像入力のサポートです。これにより、音声やテキストに加えて、写真やスクリーンショットを会話に含めることができるようになりました。ユーザーは自分が見ているものをAIに見せながら、「これは何?」「このスクリーンショットに書かれている文字を読んで」といった質問ができます。これにより、AIは視覚情報に基づいた、より文脈に沿った応答が可能になり、応用の幅が大きく広がります。
画像は「ライブ動画ストリーム」として扱われるのではなく、会話に「写真を追加する」ような形で処理されます。アプリケーション側で、どの画像をモデルと共有し、いつ共有するかを制御できるため、開発者は常にモデルが何を見ているかを管理できます。
{
"type": "conversation.item.create",
"previous_item_id": null,
"item": {
"type": "message",
"role": "user",
"content": [
{
"type": "input_image",
"image_url": "data:image/{format(example: png)};base64,{some_base64_image_bytes}"
}
]
}
}
SIPサポート
SIP(Session Initiation Protocol)は、インターネット電話(IP電話)などで広く使われている標準的な通信プロトコルです。Realtime APIがSIPを直接サポートしたことで、開発者はAIエージェントを公衆電話網や企業の電話交換機(PBX)、固定電話などに接続できます。これにより、AIが顧客からの電話に直接応答したり、予約確認の電話をかけたりといった、従来の電話システムと連携したアプリケーションの構築が容易になります。
再利用可能なプロンプト
新たに追加された機能として、再利用可能なプロンプト機能があります。開発者メッセージ、ツール、変数、ユーザー/アシスタントのサンプル会話などで構成されるプロンプトを保存し、複数のRealtime APIセッション間で再利用できるようになりました。これは、Responses APIと同様の機能で、開発効率の向上に大きく寄与します。
開発者にとってのメリットと注意点
価格
「gpt-realtime」は、性能が向上したにもかかわらず、価格は従来のプレビュー版モデルと比較して20%引き下げられました。具体的には、音声入力が100万トークンあたり32ドル(キャッシュされた入力トークンは0.40ドル)、音声出力が100万トークンあたり64ドルとなります。これにより、多くの開発者が本番環境で音声エージェントを運用しやすくなります。
さらに、会話コンテキストの詳細な制御機能が追加され、開発者はインテリジェントなトークン制限を設定し、複数のターンを一度に切り捨てることができるようになり、長時間のセッションのコストを大幅に削減できます。
安全性とプライバシー
OpenAIは、悪意のあるなりすましを防ぐためにプリセットされた音声のみを使用するなど、悪用を防ぐための安全対策を複数導入しています。Realtime APIセッションには能動的な分類器が適用されており、有害コンテンツガイドラインに違反すると検出された会話は停止される場合があります。開発者は、Agents SDKを使用して独自の安全ガードレールを簡単に追加することもできます。
開発者は、利用ポリシーに従うと共に、ユーザーがAIと対話していることを明確に伝えることが求められます(文脈から明らかである場合を除く)。また、Realtime APIはEU Data Residencyを完全サポートしており、企業のプライバシー要件にも対応しています。
まとめ
今回発表された「gpt-realtime」とRealtime APIのアップデートは、音声対話AIの技術を大きく前進させるものです。単一モデルによるSpeech-to-Speech方式は、低遅延で自然な対話を実現し、ユーザー体験を向上させます。また、画像入力や電話連携(SIP)、再利用可能なプロンプトといった新機能は、AIが現実世界の情報をより深く理解し、様々なシステムと連携するための扉を開きました。
特筆すべきは、各種ベンチマークにおける顕著な性能向上です。推論能力、指示追従性、関数呼び出し精度のすべてで大幅な改善が見られ、実用的な音声エージェントの構築がより現実的になりました。これにより、カスタマーサポートの自動化、よりインタラクティブな教育コンテンツ、多機能なパーソナルアシスタントなど、音声AIの応用範囲はますます広がっていくでしょう。








