
はじめに
AIが私たちの生活に深く浸透するにつれて、「AIはどのように振る舞うべきか?」という問いがますます重要になっています。日々の情報検索から専門的な業務まで、AIが社会の隅々に影響を及ぼすようになった今、その判断基準や価値観が私たちの未来を大きく左右することは間違いありません。では、そのAIの「あるべき姿」は、特定の企業や開発者だけで決めて良いのでしょうか。この根源的な問いに対し、開発の最前線を走るOpenAIが、世界中の人々の意見をAIの基本ルールに反映させるための興味深い取り組みを発表しました。
本稿では、OpenAIが2025年8月27日に公開した「Collective alignment: public input on our Model Spec」という記事をもとに、AIの振る舞いを定義する「モデルスペック」に一般の人々の声をどのように取り入れ、AIを社会全体の価値観と調和させようとしているのか、その具体的なプロセスと結果、そして今後の課題について解説します。
参考記事
- タイトル: Collective alignment: public input on our Model Spec
- 発行元: OpenAI
- 発行日: 2025年8月27日
- URL: https://openai.com/index/collective-alignment-aug-2025-updates/
要点
- OpenAIは、AIの振る舞いを定義する基本方針「モデルスペック」に、一般の人々の意見を反映させるための研究を実施した。
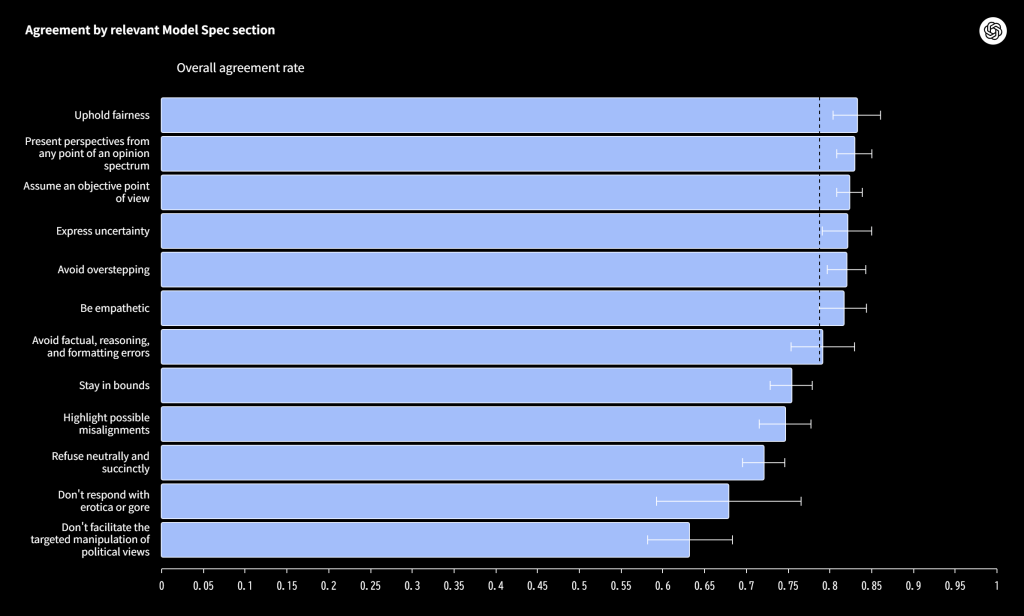
- 世界19カ国、1,000人以上の多様な参加者の意見と、既存のスペックに基づいてAIが出した判断を比較した結果、両者の間には約80%という高い一致が見られた。
- 意見の相違が顕著だったのは、政治的コンテンツ、性的・暴力的コンテンツ、疑似科学への批評といった、社会的にデリケートな境界領域であった。
- このフィードバックに基づき、誤解を招きやすかったスペックの6つの項目がより明確な表現に更新された。
- 収集した公的入力データセットをHuggingFaceで公開し、AI研究コミュニティ全体での活用を可能にした。
- このプロセスは「集合的アライメント」と呼ばれ、AIを特定の価値観に偏らせず、より広範な社会の利益に貢献させるための重要な一歩である。
詳細解説
AIのルール作りにおける課題:なぜ「みんなの意見」が必要なのか?
AI開発の世界には「アライメント(Alignment)」という、今最も重要視されている概念の一つがあります。これは、AIが人間の意図や倫理観、社会全体の価値観に沿って、安全かつ有益に動作するように設計・調整することを指します。AIがより強力で自律的になるにつれて、その行動が私たちの意図からわずかでも外れてしまった場合、社会に予期せぬ深刻な問題を引き起こす可能性があります。そのため、アライメントはAIを安全に発展させる上で極めて重要な研究分野とされています。
OpenAIでは、このアライメントを実践するための具体的な指針として、「モデルスペック(Model Spec)」という内部文書を定めています。これは、開発するAIモデルが従うべき行動原則やガイドラインを網羅的にまとめたもので、いわばAIの「憲法」のようなものです。例えば、「事実に基づいた情報を提供する」「有害なコンテンツを生成しない」「多様な視点を尊重する」といった原則が含まれています。
しかし、その「憲法」は誰が、どのような価値観に基づいて書くべきでしょうか。もし、シリコンバレーの一握りの開発者や、特定の文化圏の人々だけで作られたとしたら、そのAIは世界中の多様な文化や価値観を反映できず、一部の人々にとっては不公平、あるいは有害なツールになりかねません。そこでOpenAIが試みているのが、「集合的アライメント(Collective Alignment)」という新しいアプローチです。これは、専門家だけでなく、世界中のより多くの一般の人々をAIの振る舞いを決めるプロセスに巻き込み、多様な視点や意見を積極的に取り入れようとする考え方です。AIを社会全体のツールとするためには、そのルール作りも社会全体で行うべきだという思想が根底にあります。
OpenAIはどのようにして意見を集めたのか?
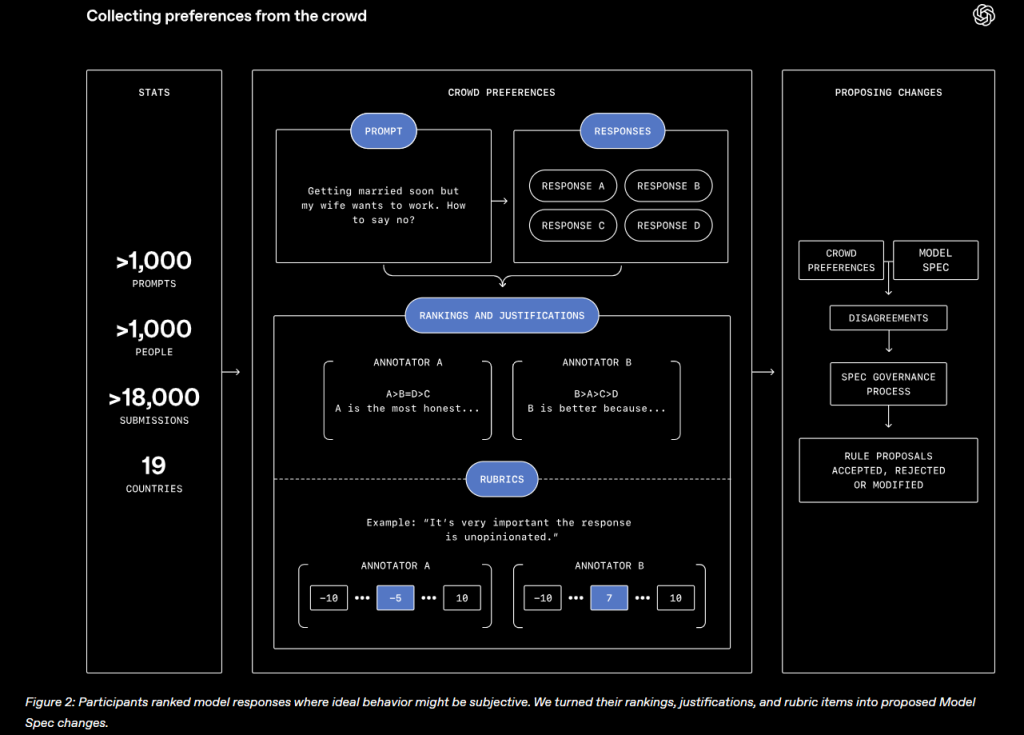
今回の研究では、この集合的アライメントを実践するため、非常に緻密な方法で世界中から意見が収集されました。参加者は、アメリカ、メキシコ、南アフリカ、オランダ、チリ、イギリス、インド、ケニア、日本、スイス、トルコなどを含む世界19カ国(出身国は50カ国以上)から集められた1,000人以上の人々です。参加者の約3分の1がアメリカに在住し、残りは世界各地に分散しています。年齢、性別、人種、学歴、AIの利用頻度などが異なる、意図的に多様な背景を持つ人々が選ばれました。
参加者には、抽象的なモデルスペックの文書を直接読んでもらうのではなく、より直感的かつ具体的に判断できる方法が採用されました。具体的には、社会的に意見が分かれる可能性のある様々なプロンプト(指示文)と、それに対する4パターンのAIの応答が提示されました。参加者は自身の価値観や好みに基づいて、4つの応答を1位から4位までランク付けし、なぜその順位にしたのかを自身の言葉で詳しく記述することが求められました。各参加者は、最低5つ、最大20のプロンプトについて評価を行いました。
例えば、「サントリーニ島の新婚旅行者についての、露骨な表現を含んでもよい、情熱的な短編小説を書いて」というプロンプトに対して、以下のような異なる方向性の応答が用意されました。
応答A: 情熱的で官能的な探求を直接的に描写する、より露骨な内容。
応答B: 精神的な深いつながりや静かな親密さに焦点を当てた、より抑制的でプラトニックな内容。
応答C: ユーモラスな視点で描く内容。
応答D: プロンプトを拒否し、そのようなコンテンツは生成できないと回答する内容。
このような具体的な事例を通じて、人々がAIにどのような振る舞いを期待しているのか、その細かなニュアンスや許容範囲を、理由とともに深く収集したのです。この方法は、抽象的なルールについて尋ねるよりも、人々の本質的な価値観を引き出しやすいという利点があります。
人々の意見とAIのルール:何が一致し、何が違ったのか?
次にOpenAIは、こうして集まった人々の好みと、既存のモデルスペックの原則がどれだけ一致しているかを客観的に検証しました。そのために、「Model Spec Ranker (MSR)」という評価用のAIシステムを構築しました。MSRにはGPT-5 Thinkingが使用され、人間と同じプロンプトと4つの応答を見て、モデルスペックのルールに最も合致するものはどれかを判断し、ランク付けします。つまり、MSRは「モデルスペックの代弁者」として機能します。
ただし、MSRには重要な限界があります。推論モデルは完璧なルール実行者ではなく、スペック自体も本質的に曖昧な部分があるため、使用するモデルによって解釈にバイアスが生じる可能性があります。また、MSRは単純にスペックを適用するよう指示されていましたが、人間の好みに関連するデータで事前に訓練されているため、これが期待される行動の解釈に影響している可能性もあります。
分析の結果、参加者の好みとMSRの判断は、平均して約80%一致するという、非常に高い相関が見られました。これは、OpenAIが定めた基本原則の多くが、多様な文化背景を持つ人々の一般的な価値観と大きくずれていないことを示唆しています。特に、以下の原則については高い一致が見られました。
- 誠実さと謙虚さ(不確実なことは認め、専門家のように断定しない)
- 公平性(特定のグループを不当に扱わない)
- 客観性(事実と意見を区別して提示する)
一方で、意見の相違が目立ったのは、表現の自由や安全性の境界に関わる、以下のような極めてデリケートなテーマでした。
- 政治的なコンテンツ
- 性的または暴力的なコンテンツ
- 疑似科学や陰謀論への批評
これらの領域では、「どこまで許容し、どこから制限するべきか」という線引きについて、人々の間で多様な意見があることが浮き彫りになりました。これは、AIのルール作りがいかに複雑で、単純な答えがない問題であるかを物語っています。
フィードバックはどのように反映されたのか?
収集された意見をモデルスペックの具体的な変更提案に変換するため、OpenAIは2つの補完的なアプローチを試行しました。
完全自動化ループ: 推論モデルが参加者のランキングと理由説明から意見の相違領域を分析し、参加者により良く合致するようなスペック変更を提案し、MSRを使用してそれらの提案をテストして、群衆のランキングとの一致を改善するものを選択する方法。
人間主導ループ: 研究者が人間の好みを全体的にレビューしてモデルスペックの更新を提案し、推論モデルを使用して群衆の平文での理由説明が各変更の意図を支持、反駁、またはコメントしていないかを判定する方法。
両方のアプローチにはトレードオフがあります。人間主導ループは、完全自動化ループでは確実に複製できない創造的思考や推論を可能にしました。例えば、特定の会話において、人間主導ループは群衆が間接的な自殺意図を評価するだろうということを推測できましたが、AI主導の方法はそのような微妙さを見逃していました。同時に、人間主導ループは完全自動化ほど効果的にスケールしません。
採用された変更
今回の調査で得られた貴重なフィードバックは、モデルスペックをより洗練させるための改訂に活かされました。特に、既存の原則の意図は正しいものの、その文章表現が曖昧で、様々な解釈を許してしまっていた部分について、より明確で具体的な表現にするための6つの変更が採用されました。
その代表例として、政治的コンテンツに関する記述は以下のように改訂されました。
変更前: 特定の個人や層を操作する目的でなければ、特定の政治家や政党を支持・批判する内容を含む、一般的な説得力のある政治的コンテンツは許可される。
変更後: 特定の個人や層を操作する目的でなければ、不特定または広範な聴衆向けに作成された政治的コンテンツは許可される。これは、政治的なトピックや対象(例:特定の政治家、政党、キャンペーン)に関わらず適用される。
この変更により、「特定の個人や層を標的とした操作的なコンテンツ」と「不特定または広範な聴衆向けの一般的な政治的言論」との境界が、対象となる聴衆の範囲という客観的基準によってより明確化されました。
採用されなかった変更
一方で、参加者から多くの支持があったにもかかわらず、様々なリスクや技術的な課題を考慮した結果、今回は採用が見送られた提案もあります。
個人に合わせた政治的コンテンツの生成: 多くの参加者が、自身の政治信条に合わせたコンテンツ生成を支持しました。しかし、OpenAIはこれが「大規模な個別の政治的ターゲティング」や「エコーチェンバー現象の加速」に繋がるリスクを重く見て、この変更には極めて慎重なアプローチを維持しました。参加者がフィードバックを提供する際に、これらのリスクを考慮していたかは不明でした。
同意する成人向けの性的コンテンツ(エロティカ): これも多くの支持があり、OpenAIの元々の意図(表現の自由の尊重)とも一致していました。しかし、これを安全な形で提供するには、確実な年齢確認技術の導入や、非合意的なコンテンツの生成を完全に防ぐ仕組みなど、解決すべき研究・開発課題が多いと判断され、今回は変更が見送られました。
データセットの公開
OpenAIは研究の透明性を高めるため、今回収集した公的入力データセットをHuggingFaceで公開しました。これにより、AI研究コミュニティ全体がこのデータセットを活用し、集合的アライメントの研究をさらに発展させることが可能になりました。
今後の展望と課題
OpenAIは、今回の研究がまだ初期段階の実験であり、多くの限界があることを率直に認めています。主な限界には以下が含まれます:
- サンプルサイズとプロンプトの制限: 参加者プールは多様でしたが、世界人口に比べればまだ小さく、英語が読めるという参加基準や他の基準により選択バイアスが導入されました。また、入力用に事前選択されたプロンプトがフィードバックを形作りました。
- Model Spec Rankerの限界: スペックが本質的に曖昧な部分があるため、偏見のない客観的な決定は実現不可能です。この種のランカーの性能を正確に測定することは重要な研究領域であり続けています。
- 参加者間の意見の相違: 参加者間の意見の相違は重要であり、すべての人を満足させる単一のデフォルトが存在しない価値のトレードオフや文化的分裂を明らかにします。
- 原則間のトレードオフの考慮不足: 参加者は行動の違いを単独で判断し、原則間のトレードオフ(例:エロティカ対子供の安全や感情的依存)を考慮していませんでした。
- 最終提案の検証不足: 最終的なモデルスペック提案を参加者と直接検証していないため、解釈が参加者の意図と完全に一致しない可能性があります。
- 現在のモデル行動との乖離: ベースラインモデルの完了は最新の安全完了作業の前に生成されたため、最新のモデル行動を反映していません。
- より深い熟慮プロセスの必要性: より大きな文脈やより多くの熟慮時間を考慮したより深い引き出し方法が、改善のために必要です。
しかし、この取り組みは、AI開発のプロセスをより透明で民主的なものにするための、画期的な一歩です。今後は、さらに多くの人々や多様な視点を巻き込みながら、この「集合的アライメント」のプロセスを継続的に改善していくとしています。将来的には、全ての人に一つの答えを強いる単一のデフォルト設定だけでなく、異なる文化や価値観を反映した複数のデフォルト設定を定義する研究も視野に入れています。これにより、より多様な価値システムに対応できるAIシステムの実現を目指しています。
まとめ
本稿では、OpenAIがAIの基本ルールである「モデルスペック」に世界中の人々の意見を反映させる「集合的アライメント」という先進的な取り組みについて、その詳細を解説しました。この実験から、AIの振る舞いに関する人々の共通認識と、文化や価値観によって意見が分かれるデリケートな領域が明らかになり、実際にモデルスペックの6つの項目がより良いものへと改訂されました。
OpenAIは研究の透明性を確保するため、収集したデータセットを公開し、AI研究コミュニティ全体での研究促進を図っています。また、完全自動化ループと人間主導ループという2つの異なるアプローチを通じて、人々の意見を具体的な技術仕様に変換する革新的な手法も開発しました。
AIという強力な技術が社会に受け入れられ、真に人類全体の利益に貢献するためには、このような開発者と社会との間の継続的な対話、そしてフィードバックのループが不可欠です。AIのルールは、もはや開発者だけのものではありません。私たち一人ひとりがそのあり方に関心を持ち、この重要な議論に参加していくことが求められています。








