はじめに
遠い惑星の地表を自律的に探査する小型ロボット。そんなSFのような未来が、AI技術の進歩によって現実のものになろうとしています。宇宙開発の最前線を走るNASAのジェット推進研究所(JPL)は、より遠く、より多くの天体を探査するため、次世代の小型探査ローバーの開発を進めています。その成功の鍵を握るのが、ロボットの「眼」となる高度な視覚認識能力です。
本稿では、Meta社が発行したブログ記事「Small robots, mighty vision: NASA Jet Propulsion Laboratory’s DINOv2-enabled robot rovers and the future of planetary exploration」を元に、限られた計算資源で高度な自律性を実現するために、JPLがどのようにMetaのAI技術「DINOv2」を活用しているのかを、その技術的なポイントや背景を解説します。
参考記事
- タイトル: Small robots, mighty vision: NASA Jet Propulsion Laboratory’s DINOv2-enabled robot rovers and the future of planetary exploration
- 発行元: Meta AI
- 発行日: 2025年8月14日
- URL: https://ai.meta.com/blog/nasa-jpl-dino-robot-explorers/
GitHub: https://github.com/nasa-jpl/visual-perception-engine
要点
- NASA JPLは、将来の多数の小型探査機による効率的な惑星探査を目指している。
- 小型探査機は搭載できるコンピュータの性能や電力に厳しい制約があるため、効率的な自律航行システムが不可欠である。
- Metaのオープンソース視覚基盤モデル「DINOv2」を共通基盤として利用することで、地形評価や障害物検知など複数の視覚タスクを単一のAIモデルで処理し、計算負荷を大幅に削減することに成功した。
- このアプローチにより、AIモデルのパラメータ数を67%削減し、さらにリアルタイムで地形の危険性を学習する新たな能力も獲得した。
詳細解説
将来の惑星探査が求めるもの:小型・自律・多数
これまでの火星探査では、「キュリオシティ」や「パーサヴィアランス」といった比較的大型の探査ローバーが活躍してきました。しかし、将来、火星だけでなくさらに遠い惑星や衛星へと探査の範囲を広げるためには、より低コストで、かつ多数の探査機を同時に送り込むアプローチが求められます。そこで期待されているのが、小型・軽量な次世代の探査ローバーです。
しかし、機体を小型化すると、搭載できるコンピュータの性能(計算資源)やバッテリー容量にも大きな制約が生まれます。加えて、地球と探査機との距離が数億キロメートルにもなると、通信に数分から数時間の遅延が生じるため、探査機は地球からの指示を待つことなく、自らの判断で障害物を避け、目的地へ進む高度な自律性が不可欠です。
従来のAIアプローチの壁と「視覚基盤モデル」という解決策
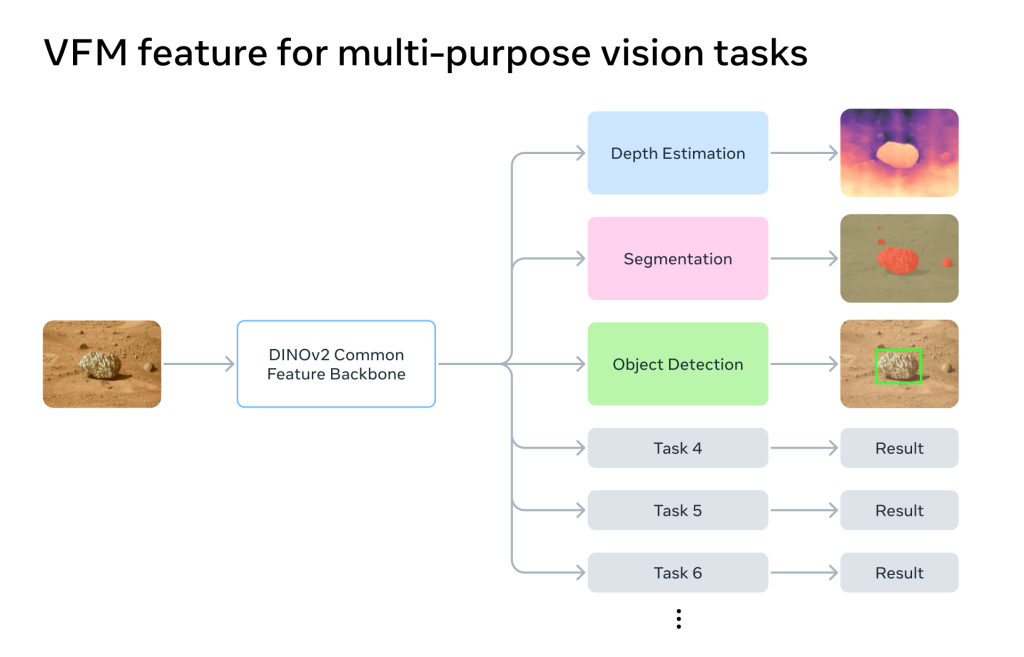
ロボットが自律的に周囲を認識するためには、カメラ映像から様々な情報を読み取る必要があります。例えば、「地形の凹凸を把握する(深度推定)」、「科学的な調査対象を見つける(物体検出)」、「その対象物を正確に掴むために形を認識する(セグメンテーション)」といったタスクです。
従来のアプローチでは、これらのタスク一つひとつに専用のAIモデルが必要でした。しかし、限られた計算資源しかない小型ローバー上で、これらの重いモデルを複数同時に実行することは非常に困難です。
この課題を解決する鍵としてJPLが注目したのが、Metaが開発した「DINOv2」というAIモデルです。DINOv2は「視覚基盤モデル(Vision Foundation Model)」と呼ばれるもので、非常に大規模な画像データを使って事前に訓練された、汎用性の高い視覚認識能力を持っています。特定のタスクに特化しているのではなく、画像から本質的な特徴を捉える能力に長けているのが特徴です。
JPLが開発した「Visual Perception Engine」の仕組み
JPLのチームは、このDINOv2をいわば「共通の眼」として利用する「Visual Perception Engine」というフレームワークを開発しました。
この仕組みの核心は、AIによる処理の効率化にあります。まず、DINOv2がカメラからの画像を受け取り、その画像が持つ汎用的な特徴(物体の輪郭、質感、パターンなど)を抽出します。そして、その抽出された一つの特徴量データを、深度推定や物体検出といった複数の個別タスクを担当する小さなAI(タスクヘッド)が共有して利用するのです。
これにより、タスクごとに一から画像認識を行う必要がなくなり、GPU(画像処理装置)の計算量とメモリ使用量を劇的に削減できます。JPLの報告によれば、このアプローチによってAIモデル全体のパラメータ数を67%も削減することに成功しました。
成果:リソース削減と「オンライン学習」という新たな能力
計算資源を大幅に節約できたことで、JPLはさらに一歩進んだ能力をローバーに与えることができました。それが、地形との相互作用から危険性をリアルタイムで学習する「オンライン学習」機能です。
これは、ローバーが地面を進む際の視覚情報と、モーターにかかる負荷(電力消費量)を組み合わせることで、「見た目は平坦だが、実はタイヤが埋まってしまうような軟弱な砂地」といった、画像だけでは判断が難しい危険な地形を識別し、回避する能力です。
この技術は、2005年に火星探査機「オポチュニティ」が砂丘にはまってしまい、地球からの遠隔操作で脱出するのに5週間もかかったという苦い経験に基づいています。自律的な危険回避能力は、ミッションの成功率を大きく左右する重要な技術なのです。
Visual Perception Engineの使い方
JPLが開発したVisual Perception Engineは、オープンソースとして公開されており、研究者や開発者が実際に試すことができます。以下に、その具体的な使用方法を解説します。
GitHub: https://github.com/nasa-jpl/visual-perception-engine
動作環境とシステム要件
対応ハードウェア:
- NVIDIA Jetson Orin AGX(推奨)
- Jetpack 6.1以上
- その他のJetsonデバイスでも動作可能(未検証)
主要機能:
- 単眼深度推定(DepthAnythingV2ベース)
- セマンティックセグメンテーション
- 物体検出(Pure PyTorch実装)
- リアルタイム処理(50Hz以上)
- C++ ROS2 (Humble) ノード対応
セットアップ手順
1. リポジトリのクローン
git clone https://github.com/nasa-jpl/visual-perception-engine2. Docker環境の構築
環境変数の設定:
# ユーザー情報をDockerにコピー
export _UID=$(id -u)
export _GID=$(id -g)
# ワークスペースのパスを指定
export WORKSPACE="path/to/cloned/repo"
# ROS2を使用する場合
export WORKSPACE="path/to/ros2/workspace"Dockerコンテナの構築と起動:
cd docker/
docker compose -f docker-compose.yml build
docker compose -f docker-compose.yml up -d3. 必要なライブラリのインストール
コンテナ内で以下を実行:
sudo git clone https://github.com/NVIDIA-AI-IOT/torch2trt /opt/torch2trt
cd /opt/torch2trt
sudo pip3 install .
cd -4. パッケージのインストール
# 基本インストール
python3 -m pip install .
# 開発用(パッケージを編集する場合)
python3 -m pip install -e .5. モデルチェックポイントの準備
指定されたリンクからモデルをダウンロードし、models/checkpoints/フォルダに配置後:
python3 -c "import vp_engine; vp_engine.export_default_models()"6. CUDA MPSの設定
複数のプロセスで同じGPUを使用するため、CUDA MPS(Multi-Process Service)を有効化:
export CUDA_VISIBLE_DEVICES=0
export CUDA_MPS_PIPE_DIRECTORY=/tmp/nvidia-mps
export CUDA_MPS_LOG_DIRECTORY=/tmp/nvidia-mps/log
# ディレクトリの作成と権限設定
sudo mkdir -p $CUDA_MPS_PIPE_DIRECTORY $CUDA_MPS_LOG_DIRECTORY
sudo chown $USER $CUDA_MPS_PIPE_DIRECTORY $CUDA_MPS_LOG_DIRECTORY
# MPSデーモンの開始
nvidia-cuda-mps-control -d基本的な使用方法
エンジンの初期化と起動
python
from vp_engine import Engine
# エンジンの初期化
engine = Engine('configs/default.json', 'model_registry/registry.jsonl')
# プロセス間通信の確立
engine.build()
# 推論の開始
engine.start_inference()
# テスト実行(強く推奨)
was_success: bool = engine.test()画像の処理
import torch
import numpy as np
# 画像の準備(TorchまたはNumPy形式)
img = torch.zeros(1920, 1080, 3).to(torch.uint8)
# 画像をエンジンに入力
was_success: bool = engine.input_image(img)
# 各タスクヘッドの出力を取得
depth_image = engine.get_head_output(0) # 深度推定
object_detection = engine.get_head_output(1) # 物体検出
segmentation = engine.get_head_output(2) # セグメンテーション実行時の動的制御
# モデルの実行レートを変更
new_rate = 10 # Hz
was_success = engine.change_model_rate("model_name", new_rate)
# モデルのパラメータ情報を取得
fm_params = engine.get_foundation_model_params()
mh_params = engine.get_model_heads_params()サンプルデモの実行
実際の画像を使ったデモ:
from vp_engine import Engine
import cv2
from time import sleep
# エンジンの初期化
engine = Engine('configs/default.json', 'model_registry/registry.jsonl')
engine.build()
engine.start_inference()
engine.test()
# サンプル画像の読み込み
image = cv2.imread("tests/resources/object_detection/inputs/20230710_103312.png")
img_resized = cv2.resize(image, (1920, 1080))
# 画像処理の実行
engine.input_image(img_resized)
sleep(0.1) # 処理完了まで待機
# 結果の取得
depth_image = engine.get_head_output(0)
object_detection = engine.get_head_output(1) # [labels, scores, normalized_boxes]
segmentation = engine.get_head_output(2)
# 可視化
visualization = engine.visualize_raw_output(1, engine.get_raw_head_output(1), img_resized)
cv2.imshow("Object detection visualization", visualization)ROS2との統合
ロボット工学での実用性を高めるため、ROS2ノードも提供されています:
ビルド手順
# ROS2環境の設定
source /opt/ros/humble/install/setup.bash
colcon build --packages-select vp_engine_ros --symlink-install
source install/setup.bash起動
# 基本起動
ros2 launch vp_engine_ros engine_launch.xml
# デモ実行
ros2 launch vp_engine_ros engine_demo.xmlROS2ノードでは、設定ファイルで指定された各モデルヘッド用のパブリッシャーが自動的に作成され、以下のサービスも利用できます:
GetModelNames:エンジン内のモデル名一覧を取得ChangeModelRate:実行時にモデルの実行頻度を変更
カスタマイズと拡張
Visual Perception Engineは高度にモジュラー設計されており、独自のモデルや処理を追加できます:
新しいモデルの追加
src/model_architecturesに実装を追加ModelInterfaceBaseを継承して実装__all__に追加してインポートModelExporterで登録
前処理・後処理の追加
AbstractPreprocessingまたはAbstractPostprocessingを継承src/transforms/__init__.pyの__all__に追加
このように、Visual Perception Engineは研究用途から実用的なロボットシステムまで、幅広い用途に対応可能な柔軟性を備えています。
宇宙から地球へ:技術の応用
このDINOv2を活用した技術は、宇宙探査だけに留まりません。例えば、2018年にタイで発生した洞窟遭難事故のような、人間が立ち入ることが困難な場所での災害救助活動にも応用が期待されています。
また、洞窟は宇宙からの放射線を遮蔽する性質があるため、もし地球外生命が存在するとすれば、洞窟のような環境にいる可能性が高いと考えられています。DINOv2を搭載した小型ローバーは、将来、他の惑星の洞窟を探査し、生命の痕跡を探すという壮大なミッションで活躍するかもしれません。
まとめ
本稿では、NASA JPLがMetaのAI「DINOv2」を活用して、次世代の小型惑星探査ローバーの自律航行技術をどのように進化させているかを紹介しました。
単一の強力な視覚基盤モデルを複数のタスクで共有するというアプローチは、計算資源が限られる宇宙探査において非常に有効です。これにより、ロボットはより賢く、より安全に未知の環境を探索できるようになります。宇宙で培われたこの技術が、やがて地球上の課題解決にも貢献していくことでしょう。AIとロボット工学が拓く、惑星探査の未来から目が離せません。