目次
新AIモデル紹介:AIが捉える世界を広げる「Aya Vision」
引用元: Aya Vision: Expanding the worlds AI can see (2025年3月4日発行)
要点
- Cohere For AIが、多言語かつマルチモーダルなタスクに対応する最先端のオープンウェイトビジョンモデル「Aya Vision」を発表しました。
- Aya Visionは、画像キャプション、視覚的な質問応答、テキスト生成、テキストと画像の説明文生成など、多様なタスクで優れた性能を発揮します。
- 特に、多言語対応能力が強化されており、世界人口の半数以上が話す23の言語で、テキストと画像を理解し、自然な言語で表現できます。
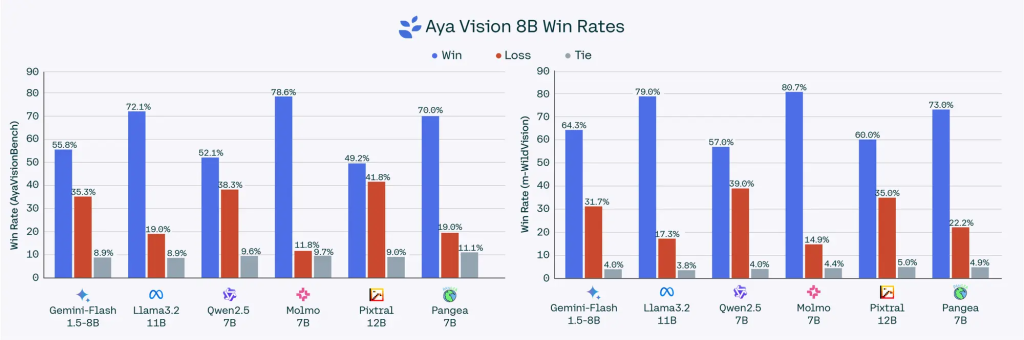
- 80億パラメータのモデルは、Qwen2.5-VL 7B、Gemini Flash 1.5 8B、Llama-3.2 11B Vision、Pangea 7Bなどの主要なオープンウェイトモデルを上回り、AyaVisionBenchで最大70%、m-WildVisionで最大79%の勝率を達成しました。
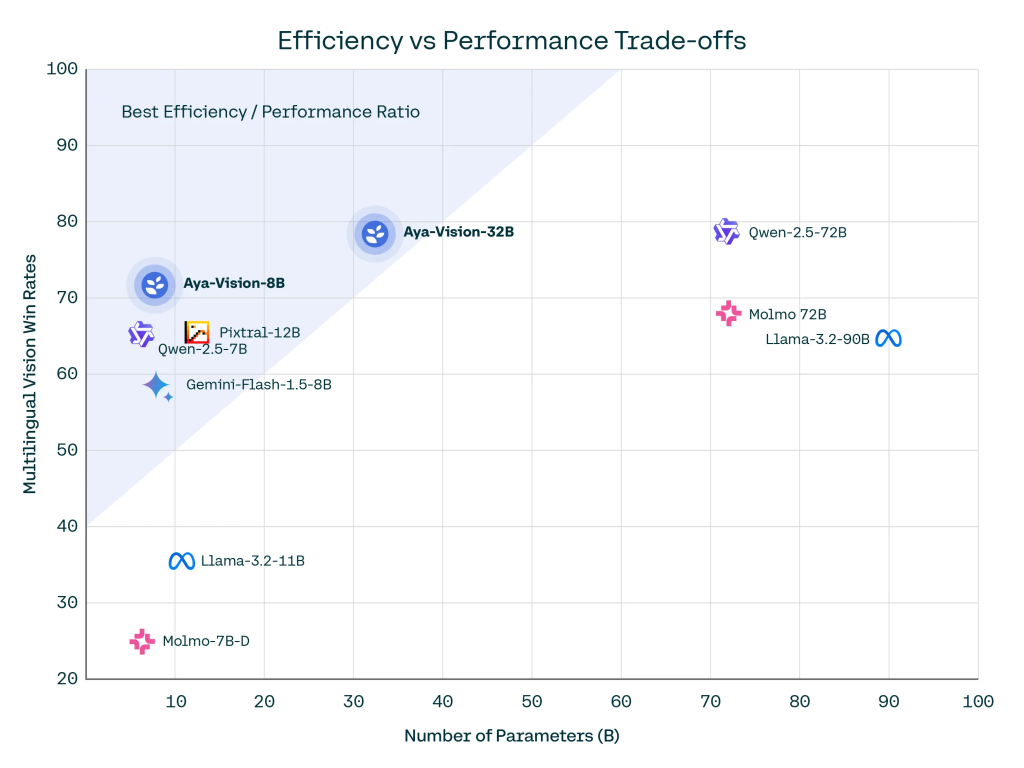
- 320億パラメータのモデルは、Llama-3.2 90B Vision、Molmo 72B、Qwen2-VL 72Bなどの大規模モデルを上回り、AyaVisionBenchで最大64%、m-WildVisionで最大72%の勝率を達成しました。
- Aya Visionは、研究目的での利用を想定して公開されており、モデルと評価ベンチマークがオープンソースとして提供されます。
詳細解説
背景
AI技術は近年目覚ましい進歩を遂げていますが、異なる言語間での性能差は依然として大きく、特にテキストと画像を組み合わせたマルチモーダルなタスクではその差が顕著です。Aya Visionは、このギャップを埋めることを目指して開発されました。
Aya Visionの特長
- 多言語対応
- 23の言語に対応し、世界人口の半数以上が使用する言語で、高度なマルチモーダルタスクを実行できます。
- これにより、文化的なニュアンスを理解し、多様な言語でコミュニケーションを行うことが可能になります。
- 多様なタスクに対応
- 画像キャプション:画像の内容を自然な言語で説明します。
- 視覚的な質問応答:画像に関する質問に答えます。
- テキスト生成:与えられた情報に基づいてテキストを生成します。
- テキストと画像の説明文生成:テキストと画像を組み合わせて、詳細な説明文を生成します。

- 高い性能
- Aya Visionは、複数のベンチマークテストで、他の主要なオープンウェイトモデルを大幅に上回る性能を示しました。
- 特に、80億パラメータのモデルは、より大規模なモデルと比較しても優れた性能を発揮し、効率的な学習を実現しています。

技術的なポイント
- 合成アノテーション:翻訳と言い換えを通じて多言語データをスケールアップし、モデルの性能を向上させています。
- マルチモーダルモデルの融合:言語理解と視覚理解を向上させるための技術を開発し、Aya Visionに統合しています。
- 効率性:より少ない計算リソースで高い性能を達成することに重点を置いており、研究コミュニティへの貢献を目指しています。
Aya Visionベンチマーク
Aya Visionのリリースに合わせて、多言語マルチモーダル評価のための厳密な評価セットである「Aya Vision Benchmark」もオープンソースとして公開されます。このベンチマークは、従来の選択式の問題だけでなく、よりニュアンスのあるオープンエンドな質問を含む、実際のユーザーインタラクションを捉えたものです。
利用方法
Aya Visionは、研究者や開発者が利用できるように、オープンウェイトモデルとして公開されています。モデルは、KaggleおよびHugging Faceからダウンロードできます。また、WhatsAppを通じて、世界中の人々がこれらのマルチモーダル機能を活用できるよう、無料アクセスも提供されています。
まとめ
Aya Visionは、多言語対応能力と多様なタスク処理能力を兼ね備えた、革新的なビジョンモデルです。このモデルの登場により、AIがより多くの言語と文化を理解し、より自然な形で人間とコミュニケーションできるようになることが期待されます。








