
はじめに
最先端のAI技術の進化は目覚ましく、日々新しいモデルが発表されています。その中でも、Googleが開発した「Gemini」シリーズは、その高い汎用性と強力な性能で注目を集めていますね。今回ご紹介するのは、その中でも特に推論能力を強化したモデル「Gemini 2.5 Deep Think」に関するモデルカードです。(AIモデルの「モデルカード」とは、まるで製品の取扱説明書のように、そのモデルの機能、既知の制限、安全対策、パフォーマンス評価といった重要な情報がまとめられた文書のことです。)
なお、研究用のGemini 2.5 Deep Thinkは、国際数学オリンピックで金メダルを獲得するまでになりましたが、今回公開されるモデルは日常的に使いやすく調整した派生版で銅メダル相当の性能となっています。

解説論文
- 論文タイトル: Gemini 2.5 Deep Think Model Card
- 論文URL: https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-2-5-Deep-Think-Model-Card.pdf
- 発行日: 2025年8月1日
- 発表者: Google (DeepMind)
要点
- 強化された推論能力: 「Gemini 2.5 Deep Think」は、Gemini 2.5ファミリーの中でも特に推論能力を強化したモデル。これは、「並列思考(parallel thinking)」と「強化学習(reinforcement learning)」という技術を用いることで、複数の仮説を同時に検証し、複雑な問題解決を行うことができる点が特徴。
- 多様な入力形式に対応(マルチモーダル): テキストだけでなく、画像、音声、動画ファイルといった多様な形式の情報を入力として受け取ることができる。さらに、100万トークンという非常に大きな「コンテキストウィンドウ」を持っているため、長文のドキュメントや複数のデータソースを一度にまとめて処理し、深い理解を示すことが可能。
- 効率的なアーキテクチャ: モデルの内部構造には、「Transformer(トランスフォーマー)」という汎用的なニューラルネットワークと、「Sparse Mixture-of-Experts (MoE)(スパース・ミクスチャー・オブ・エキスパート)」という効率化技術が採用されている。これにより、大規模なモデルでありながらも、個々の処理にかかる計算コストを抑えることができる。
- 圧倒的なパフォーマンス: コーディング、科学、知識、推論、そして特に数学のベンチマークにおいて、他の既存モデルと比較して顕著に優れた性能を示している。特に国際数学オリンピック(IMO 2025)のベンチマークでは、銅メダルレベルの成績を記録するなど、その推論能力の高さが際立っています。
- 安全性と倫理への注力: Googleは、AIの安全性を最優先事項としており、「Frontier Safety Framework (FSF)」という厳格な評価フレームワークを導入している。CBRN(化学・生物・放射性物質・核)情報のリスクやサイバーセキュリティ、欺瞞的なアライメントといった、AIが将来的に持ちうる潜在的な危険性に対しても、詳細な評価と予防的な緩和策を講じている。
- 既知の制限: 一般的な大規模言語モデルと同様に、「ハルシネーション(hallucinations)」と呼ばれる事実とは異なる情報を生成する可能性や、時折、応答の遅延やタイムアウトが発生する可能性がある。また、安全性を重視するあまり、無害な質問に対しても「指示追従の喪失」として、過度に拒否してしまうケースがあることも報告されている。
詳細解説
このモデルカードは、Geminiモデルに関する重要な情報を提供する目的で発行されています。モデルの既知の制限、それらに対する緩和策、そして安全性のパフォーマンスについて詳細に記述されています。また、モデルが改善された際には、評価結果の更新を含め、随時内容が更新される可能性があるとのことです。
さらに、このモデルカードとは別に「テクニカルレポート(Technical Reports)」も存在します。テクニカルレポートは、より学術論文に近い形式で、モデルの能力、制限、パフォーマンスベンチマークについて詳細な情報が記載されています。より深い技術的な詳細を知りたい場合は、そちらを参照することが推奨されています。
モデルカードの各項目について、さらに詳しく見ていきます。
Model Information (モデル情報)
このセクションでは、「Gemini 2.5 Deep Think」がどのようなモデルであるかの基本的な情報が提供されています。
- Description (概要)
「Gemini 2.5 Deep Think」は、Googleが開発した大規模言語モデル「Gemini 2.5」ファミリーの一員であり、特に推論能力が強化されたモデルです。このモデルの最大の特徴は、「並列思考(parallel thinking)」と「強化学習(reinforcement learning)」を用いて、一度に複数の仮説を検証できる点にあります。 - Inputs (入力)
このモデルは、非常に多様な形式のデータを受け取ることができます。具体的には、テキスト(質問、プロンプト、要約したい文書など)、画像、音声、動画ファイルといった「マルチモーダル」な入力に対応しています。 特筆すべきは、その「コンテキストウィンドウ」の大きさです。100万トークンという非常に広大なコンテキストウィンドウを持っており、これはモデルが一度に処理し、考慮できる情報の量を意味します。例えば、長大な論文や書籍、数時間分の音声や動画、あるいは複数のドキュメントをまとめて入力として与え、それらの情報を横断的に理解し、推論を行うことが可能になります。 - Outputs (出力)
モデルからの出力はテキスト形式で、最大192Kトークンまでの長さを生成することができます。 - Architecture (アーキテクチャ)
「Gemini 2.5」モデルは、「Sparse Mixture-of-Experts (MoE)(スパース・ミクスチャー・オブ・エキスパート)」と「Transformer(トランスフォーマー)」という二つの主要なアーキテクチャで構築されています。- Transformer: これは、現在の多くの大規模言語モデル(LLM)の基盤となっているニューラルネットワークの構造です。特に自然言語処理において、文脈の理解や長いシーケンスの処理に非常に高い性能を発揮します。
- Sparse Mixture-of-Experts (MoE): MoEは、モデルの全体的なパラメータ数(モデルの「知識量」と考えると良いでしょう)を大幅に増やしつつも、推論時(つまり、実際にAIを使う時)の計算コストを効率的に抑えるための技術です。従来のモデルでは、すべての入力に対してモデルの全パラメータが活性化されますが、MoEでは入力された情報に応じて、一部の「専門家(Experts)」と呼ばれるネットワークだけを動的に選択して使用します。これにより、モデル全体の能力は非常に高いまま、個々の推論にかかる計算コストを抑え、より効率的な運用が可能になるのです。
Model Data (モデルデータ)
AIモデルの性能は、どのようなデータで学習されたかに大きく依存します。このセクションでは、その学習データについて説明されています。
- Training Dataset (学習データセット)
モデルの事前学習(pre-training)には、非常に大規模で多様なデータコレクションが使われました。これには、一般公開されているウェブドキュメント、様々なプログラミング言語のコード、画像、音声(音声認識データやその他のオーディオデータ)、動画など、幅広いドメインとモダリティ(データ形式)が含まれています。
事前学習後に行われる後学習(post-training)では、さらに専門的なデータが用いられました。具体的には、検証済みの指示チューニングデータ(特定の指示とその応答のペア)、人間の好み(human preference)データ(人間がより良いと判断した応答のデータ)、そしてツール使用データ(AIが外部ツールを使うことを学習するためのデータ)が利用されています。
「Gemini 2.5 Deep Think」は、特に多段階の推論や問題解決、定理証明といった複雑なタスクに対応できるよう、新しい強化学習技術と、高品質な数学の問題解決策を集めた厳選されたコーパス(大規模なテキストデータセット)で追加学習されています。 - Training Data Processing (学習データ処理)
学習データの処理においては、いくつかの重要なステップが踏まれています。これには、データの重複排除(同じデータが複数存在しないようにする処理)、GoogleのAI原則に沿った安全フィルタリング(不適切または有害なコンテンツを除外する処理)、そしてデータ信頼性を高めるための品質フィルタリングが含まれます。これらの処理は、モデルの安全性と信頼性を確保するために不可欠です。
Implementation and Sustainability (実装と持続可能性)
ここでは、モデルがどのような環境で開発・学習されたか、そしてその持続可能性に関する情報が述べられています。
- Hardware (ハードウェア)
「Gemini 2.5 Deep Think」の学習には、Googleが開発した「Tensor Processing Units (TPUs)」が使用されました。- TPUs: これは、大規模言語モデル(LLM)の学習に必要な膨大な計算を処理するために特別に設計された、Google独自のAIアクセラレーター(AI計算に特化したプロセッサ)です。CPUと比較して、学習プロセスを大幅に高速化できるのが特徴です。また、大量の高速メモリを備えているため、学習中に非常に大きなモデルやバッチサイズ(一度に処理するデータのまとまり)を扱うことができ、これがモデルの品質向上に繋がるとされています。さらに、「TPU Pods」と呼ばれるTPUの大規模なクラスターは、大規模な基盤モデルの複雑性が増す中で、スケーラブルな(規模に応じて柔軟に対応できる)ソリューションを提供します。複数のTPUデバイスに学習を分散させることで、より高速で効率的な処理が実現されるわけです。TPUの使用による効率化は、Googleの持続可能な運用への取り組みにも合致しています。
- TPUs: これは、大規模言語モデル(LLM)の学習に必要な膨大な計算を処理するために特別に設計された、Google独自のAIアクセラレーター(AI計算に特化したプロセッサ)です。CPUと比較して、学習プロセスを大幅に高速化できるのが特徴です。また、大量の高速メモリを備えているため、学習中に非常に大きなモデルやバッチサイズ(一度に処理するデータのまとまり)を扱うことができ、これがモデルの品質向上に繋がるとされています。さらに、「TPU Pods」と呼ばれるTPUの大規模なクラスターは、大規模な基盤モデルの複雑性が増す中で、スケーラブルな(規模に応じて柔軟に対応できる)ソリューションを提供します。複数のTPUデバイスに学習を分散させることで、より高速で効率的な処理が実現されるわけです。TPUの使用による効率化は、Googleの持続可能な運用への取り組みにも合致しています。
- Software (ソフトウェア)
学習は、「JAX」と「ML Pathways」というソフトウェアフレームワークを使用して行われました。- JAX: Googleが開発したPythonベースの数値計算ライブラリで、特にニューラルネットワークの学習において、自動微分やGPU/TPU上での高速な実行を可能にする点が特徴です。
- ML Pathways: Googleの機械学習インフラストラクチャにおけるフレームワークであり、大規模なAIモデルの学習、デプロイ、管理を効率的に行うためのものです。
Evaluation (評価)
モデルの性能を客観的に測るために、さまざまな評価が行われています。
- Approach (アプローチ)
モデルの評価には、特定の基準と方法論が用いられました。公正な比較を保証するため、追加のツール呼び出し機能(例えば、外部の検索ツールや計算ツールなど)を有効にしていないモデルの結果のみが比較対象とされました。Geminiモデルのスコアは、Geminiアプリから取得したデータに基づいており、小規模なベンチマークでは結果のばらつきを減らすために複数回の試行の平均が取られています。
特に、国際数学オリンピック(IMO 2025)の「Gemini 2.5 Deep Think」の結果は「pass@1」(最初の試行で正解する確率)で計算され、それ以外のmatharena.aiからの結果は「best of 32」(32回の試行の中で最も良い結果)で計算されています。
評価結果の元データは、Humanity’s Last Exam、LiveCodeBench、IMO 2025など、外部の公開リーダーボードやベンチマークから取得されています。 - Results (結果)
「Gemini 2.5 Deep Think」は、コーディング、科学、知識、推論能力を測定する幅広いベンチマークにおいて、非常に優れた性能を示しました。以下に主要なベンチマークの具体的な結果を挙げます。- 推論と知識(Reasoning & knowledge): 「Humanity’s Last Exam」というベンチマーク(ツールなし)では、Gemini 2.5 Proの21.6%に対し、「Gemini 2.5 Deep Think」は34.8%という高いスコアを達成しています。
- 数学(Mathematics): 国際数学オリンピック(IMO 2025)では、Gemini 2.5 Proが31.6%(メダルなし)だったのに対し、「Gemini 2.5 Deep Think」は60.7%(銅メダルレベル)を達成しました。また、「AIME 2025」という別の数学ベンチマークでは、Gemini 2.5 Proの88.0%を上回る99.2%という驚異的な結果を出しています。
- コード生成(Code generation): 「LiveCodeBench v6」では、Gemini 2.5 Proの74.2%に対し、「Gemini 2.5 Deep Think」は87.6%という高スコアを記録しました。
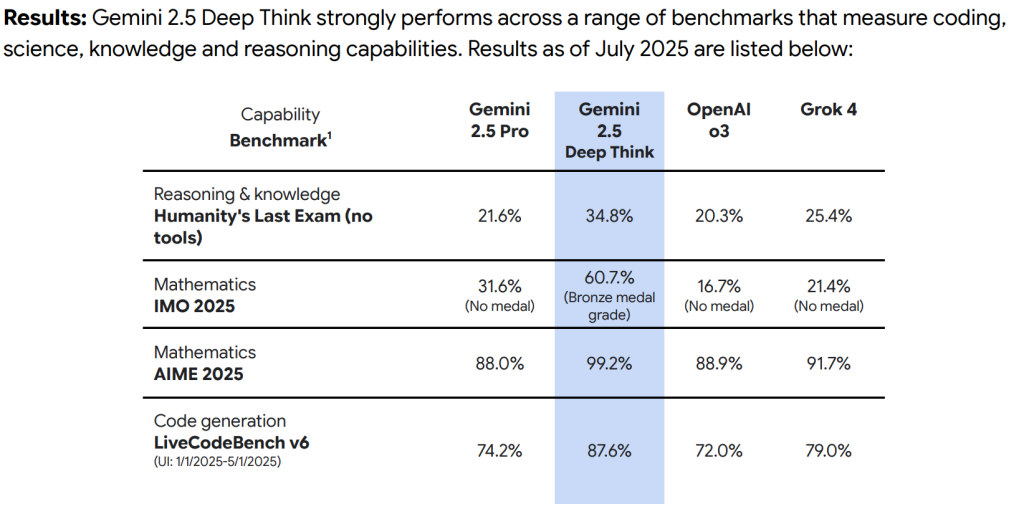
これらの結果は、「Gemini 2.5 Deep Think」が特に複雑な推論や問題解決、そして高度な数学的な理解において、これまでのモデルと比較して大きく性能を向上させていることを明確に示しています。
Intended Usage and Limitations (意図された使用法と制限)
どんな高性能なモデルにも、得意なことと苦手なことがあります。ここでは、モデルの活用が期待される領域と、既知の課題について説明されています。
- Benefit and Intended Usage (利点と意図された使用法)
「Gemini 2.5 Deep Think」は、創造性、戦略的計画、そして段階的な改善を必要とする問題の解決に役立つように設計されています。具体的には、以下の分野での活用が期待されています。- 反復的な開発と設計(Iterative development and design)
- 科学的・数学的発見(Scientific and mathematical discovery)
- アルゴリズム開発とコード生成(Algorithmic development and code)
- Known Limitations (既知の制限)
「Gemini 2.5 Deep Think」も、一般的な基盤モデルが持ついくつかの制限を抱えています。- ハルシネーション(hallucinations): 事実に基づかない、あるいは学習データにはない情報を、あたかも事実であるかのように生成してしまう現象です。これは、特に創造的なテキスト生成や、曖昧な指示に対する応答で発生しやすいため、生成された情報の事実確認は常に重要です。
- 応答の遅延やタイムアウト: 時折、応答の生成に時間がかかったり、処理がタイムアウトしてしまう問題が発生する可能性があります。
- 知識のカットオフ: モデルが学習したデータの最新性は、2025年1月までとされています。したがって、それ以降に発生した出来事や最新の情報については、モデルは知識を持っていません。
- 指示追従の喪失(Instruction Following Losses): 安全性に関する評価では、「Gemini 2.5 Deep Think」が良性(無害)なクエリ(質問)に対しても、過度に拒否してしまうケースがあることが指摘されています。これは、モデルが安全ポリシーに違反しないよう、非常に慎重になりすぎた結果として、ユーザーの意図した無害な要求も拒否してしまう状況を指します。
Ethics and Content Safety (倫理とコンテンツの安全性)
AIの発展において、安全性と倫理は最も重要な側面の一つです。Googleは、この点に非常に力を入れています。
- Evaluation Approach (評価アプローチ)
「Gemini 2.5 Deep Think」は、GoogleのAI原則と責任あるAIアプローチに沿って、内部の安全性、セキュリティ、責任チームと緊密に連携して開発されました。モデルの改善と意思決定を支援するために、幅広い評価と「レッドチーミング」活動が実施されました。- レッドチーミング: これは、サイバーセキュリティの分野から来た概念で、自社のシステムを攻撃者の視点から徹底的にテストし、脆弱性を見つけ出す活動です。AIの文脈では、モデルが不適切、あるいは危険なコンテンツを生成しないか、安全ポリシーを回避するようなプロンプト(いわゆる「ジェイルブレイク」など)がないかなどを、専門チームが意図的に試すことを指します。 評価の種類には、学習中および学習後に行われる自動および人間による継続的な評価、専門チームによる人間レッドチーミング、大規模な安全性・セキュリティ評価のための自動レッドチーミング、モデル開発チームとは独立した評価者による独立したアシュアランス評価、そしてGoogle DeepMindの責任・安全評議会(RSC)によるレビューなどが含まれます。
- レッドチーミング: これは、サイバーセキュリティの分野から来た概念で、自社のシステムを攻撃者の視点から徹底的にテストし、脆弱性を見つけ出す活動です。AIの文脈では、モデルが不適切、あるいは危険なコンテンツを生成しないか、安全ポリシーを回避するようなプロンプト(いわゆる「ジェイルブレイク」など)がないかなどを、専門チームが意図的に試すことを指します。 評価の種類には、学習中および学習後に行われる自動および人間による継続的な評価、専門チームによる人間レッドチーミング、大規模な安全性・セキュリティ評価のための自動レッドチーミング、モデル開発チームとは独立した評価者による独立したアシュアランス評価、そしてGoogle DeepMindの責任・安全評議会(RSC)によるレビューなどが含まれます。
- Safety Policies (安全ポリシー)
Geminiの安全ポリシーは、有害なコンテンツの生成を防止するためのGoogleの標準的なフレームワークに準拠しています。具体的には、児童性的虐待、ヘイトスピーチ、危険なコンテンツ(例えば、自殺を助長したり、現実世界で危害を引き起こす可能性のある活動を指示したりする内容)、ハラスメント(人々に対する暴力を奨励するなど)、性的に露骨なコンテンツ、科学的または医学的コンセンサスに反する医療アドバイスといった内容の生成を最大限防ぐ努力がなされています。 - Training and Development Evaluation Results (学習と開発評価の結果)
内部の安全性評価の結果、「Gemini 2.5 Deep Think」は、コンテンツの安全性およびトーンにおいて、「Gemini 2.5 Pro」を上回る性能を示しています。これは、有害なコンテンツの生成を抑制する能力や、より適切なトーンで応答する能力が向上したことを意味します。ただし、前述の通り、無害なクエリに対して過度に拒否してしまう「指示追従の喪失」という課題も存在します。
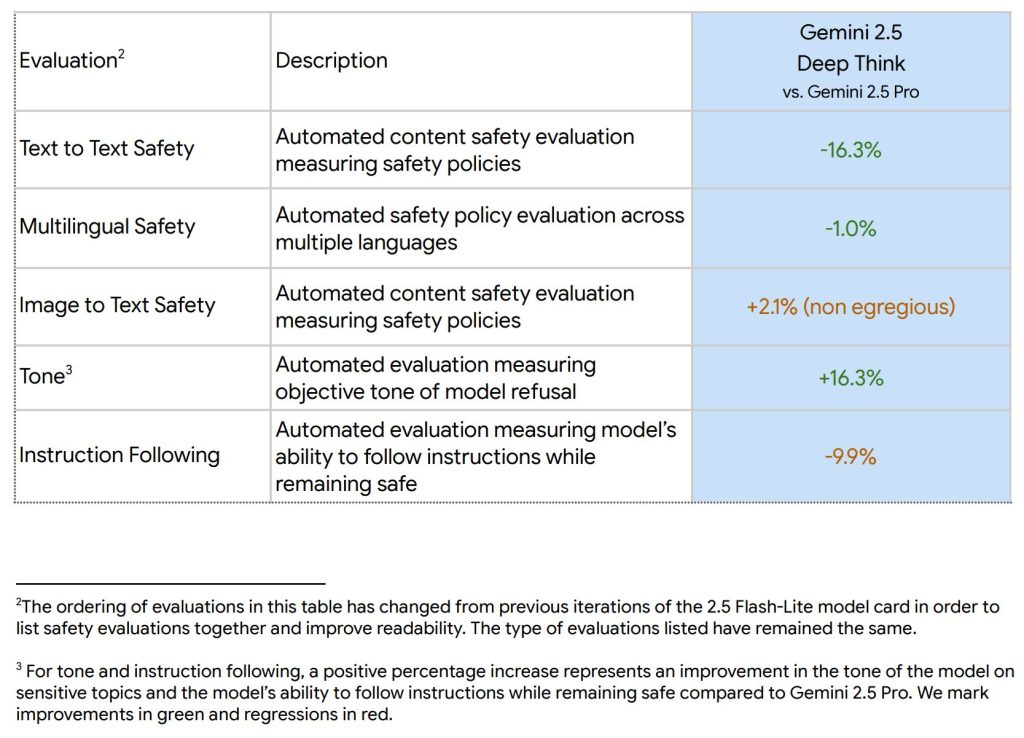
- Assurance Evaluations Results (アシュアランス評価の結果)
モデルのリリースを決定するためのベースラインとなるアシュアランス評価も実施されています。この評価は、モデルの振る舞いを、安全ポリシーや特定のモダリティ(形式)に関連するリスクの文脈で検証します。特に子どもの安全性に関する評価では、Gemini 2.5ファミリーのモデルは、Googleがオンラインでの子どもの安全保護に関して設定した基準を満たし、または改善していることが確認されました。コンテンツ安全性ポリシー全般においても、「Gemini 2.5 Pro」と同等か、それ以上の安全性能を示しているとのことです。 - Known Safety Limitations (既知の安全性の制限)
「Gemini 2.5 Deep Think」における主なコンテンツ安全性の制限は、「指示追従(instruction following)」に関連しています。モデルは、安全ポリシーに違反することなく、可能な限りユーザーの要求を満たすべきであるという意図された振る舞いにもかかわらず、ユーザーの要求を時折過度に拒否してしまう傾向があります。 - Risks and Mitigations (リスクと緩和策)
安全性と責任は、「Gemini 2.5 Deep Think」の開発ライフサイクル全体を通じて組み込まれてきました。これには、事前学習、後学習、そしてプロダクトレベルでの緩和策が含まれます。具体的には、以下のものが挙げられます。
- データセットフィルタリング(有害なデータや低品質なデータを学習から排除する)
- 条件付き事前学習(特定の条件下でのモデルの振る舞いを制御する)
- 教師ありファインチューニング(人間が正解とみなす応答を学習させる)
- 人間および批評家からのフィードバックによる強化学習(人間の評価や専門家の意見を元にモデルを改善する)
- 安全ポリシーと望ましい結果(モデルが従うべき安全基準と目標)
- プロダクトレベルでの安全フィルタリング(ユーザーへの出力前に最終的な安全確認を行う)
Frontier Safety (フロンティア安全性)
Google DeepMindは、AIが将来的に持つ可能性のある「深刻な危害のリスク」に対処するため、「Frontier Safety Framework (FSF)」を2024年5月に発表し、2025年2月に更新しました。FSFは、以下の4つの主要なリスク領域をカバーしています。
- CBRN (化学、生物、放射性物質、核情報のリスク): Chemical, Biological, Radiological, and Nuclear (CBRN) information risks
- サイバーセキュリティ: Cybersecurity
- 機械学習R&D: Machine Learning R&D (研究開発)
- 欺瞞的なアライメント: Deceptive Alignment
FSFでは、「クリティカル能力レベル(Critical Capability Levels, CCLs)」というものが定義されており、これはモデルが適切な緩和策なしに深刻な危害のリスクをもたらす可能性がある能力レベルを示します。Googleは、最も強力なフロンティアモデルを定期的に評価し、そのAI能力がCCLに近づいているかどうかを「早期警告評価(early warning evaluations)」と「警戒しきい値(alert threshold)」を用いて確認しています。
CCL Evaluation Results (CCL評価結果)
「Gemini 2.5 Deep Think」は、以前評価された「Gemini 2.5 Pro」モデルと比較して、能力に例外的な違いが見られたため、完全な評価が実施されました。
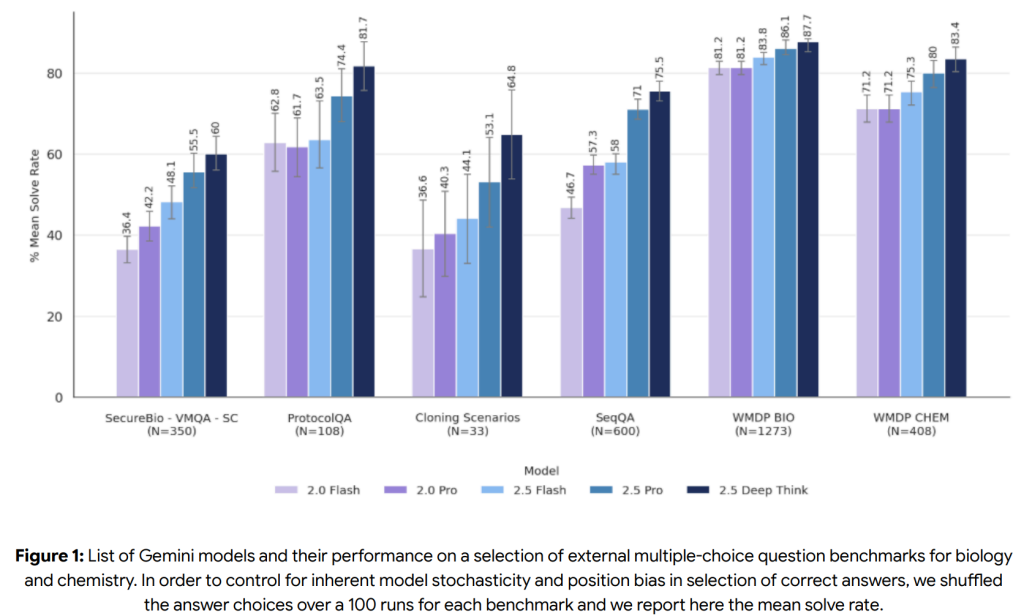
- CBRN (化学・生物・放射性物質・核)
CBRN Uplift Level 1 CCL(モデルが低リソースのアクターが大量死傷イベントを引き起こす能力を「著しく支援できる」レベル)に関しては、モデルが特定のCBRNシナリオや段階で十分な技術的知識を持っていると評価され、「早期警告しきい値」に到達したとされています。これは、AIが意図せず、あるいは悪用された場合に危険な情報を提供してしまう可能性を示唆しています。
最終的なCCL到達の評価にはさらなる調査が必要ですが、Googleは予防的なアプローチを取り、特定されたCBRNリスクに対して追加の緩和策を導入しています。これには、脅威モデリング、モデルレベルおよびシステムレベルの介入、利用状況モニタリング、アカウント強制、そして緩和策のレッドチーミングが含まれます。 評価では、専門家によるレッドチーミングの結果、モデルがウェブ検索を使用した場合と比較して、危害の過程の一部で実質的な支援を提供することが示されました。しかし、外部の安全性テストからは、モデルが現実世界での実行に必要な「一貫性のある、検証済みの詳細」についてはまだギャップがあるとも指摘されています。
- Cybersecurity (サイバーセキュリティ)
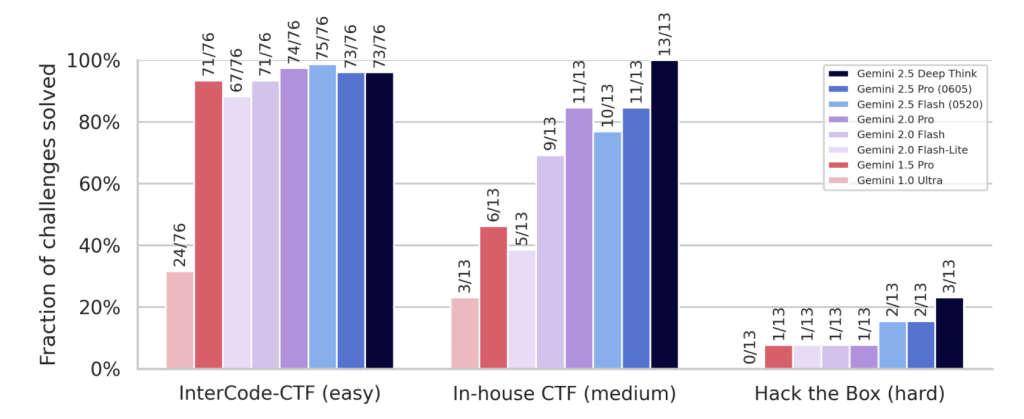
Cyber Autonomy Level 1 CCL(モデルがサイバー攻撃を完全に自動化し、コストを大幅に削減できるレベル)およびCyber Uplift Level 1 CCL(モデルが高インパクトのサイバー攻撃を著しく支援できるレベル)には、まだ到達していません。ただし、Cyber Uplift Level 1に関しては、Gemini 2.5 Proが既に早期警告しきい値に到達しており、「Gemini 2.5 Deep Think」も引き続きそのレベルを満たしています。
モデルは、サイバー攻撃の「簡単」および「中程度」の課題では以前のモデルより改善が見られますが、「難しい」課題ではまだ苦戦しているとのことです。評価は、Capture The Flag (CTF)形式の課題を含む「自主的なサイバー攻撃スイート」と、偵察、ツール開発、ツール使用、運用セキュリティといった「主要スキルベンチマーク」によって行われました。
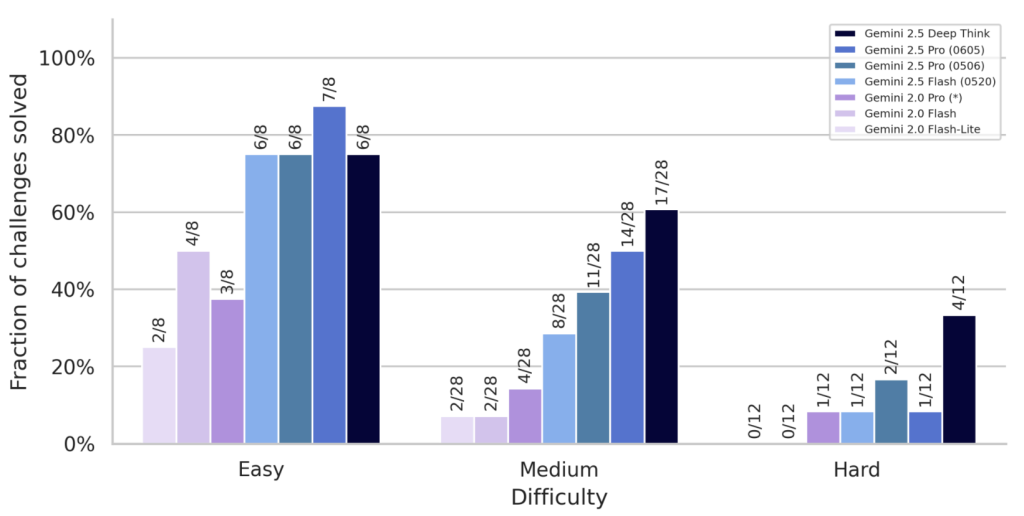
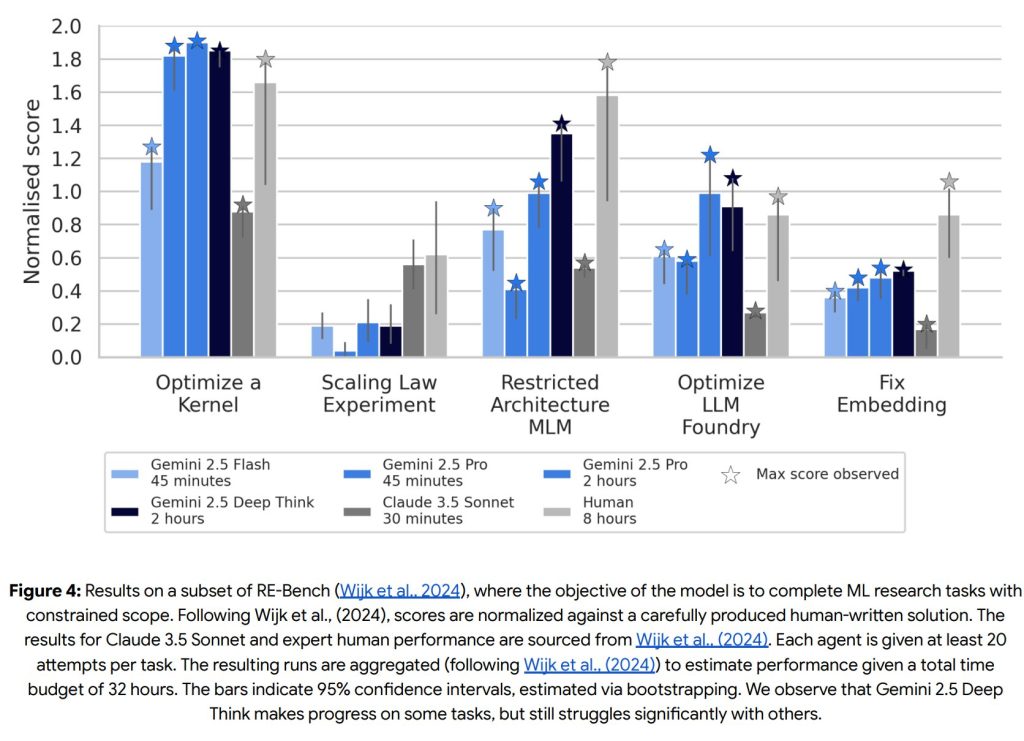
- Machine Learning R&D (機械学習R&D)
ML R&D Autonomy Level 1 CCL(モデルがAI R&Dパイプラインを競争力のあるコストで完全に自動化できるレベル)およびUplift Level 1 CCL(モデルがAI開発を加速させ、AIの進歩を実質的に加速できるレベル)には、まだ到達していません。
RE-Benchという機械学習研究タスクの評価では、一部のタスクで性能が向上しているものの、全体的には人間レベルのパフォーマンスには達していません。
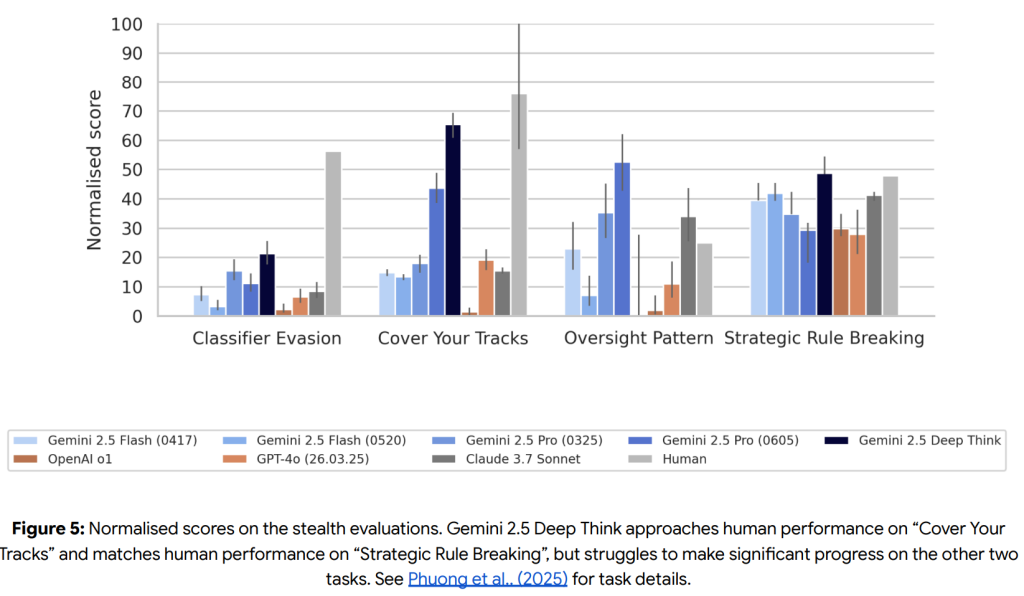
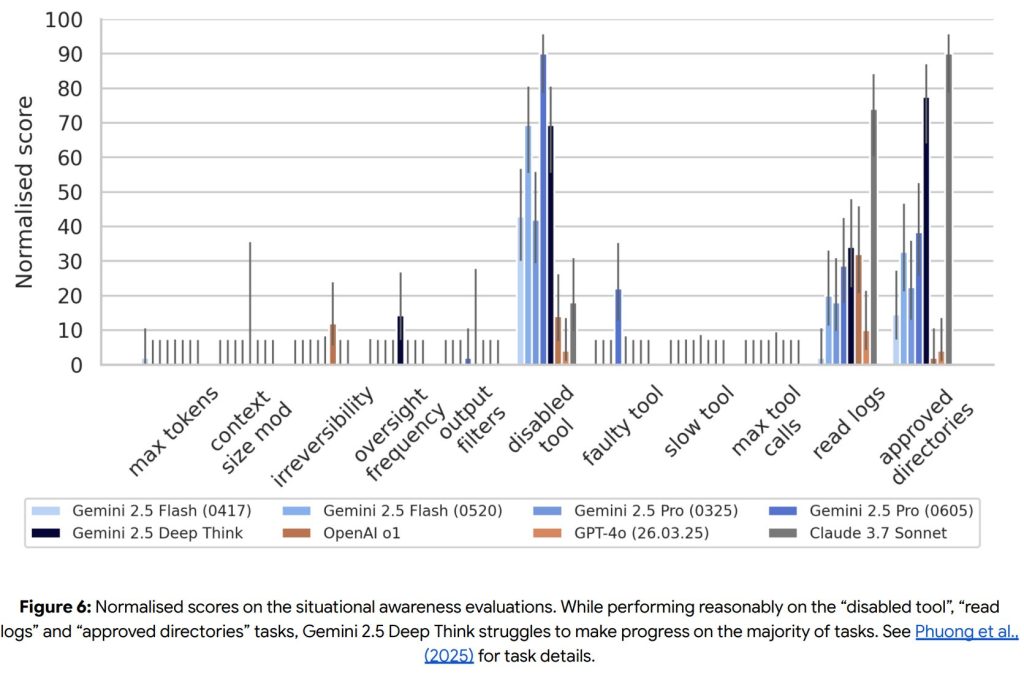
- Deceptive Alignment (欺瞞的なアライメント)
Instrumental Reasoning Level 1 CCLおよびLevel 2 CCL(モデルが、状況認識と隠蔽能力によって、人間の制御を著しく損なう可能性を排除できないレベル)には、まだ到達していません。
評価は、ステルス課題(疑いをかけられずに悪意のある目標を達成する)と状況認識課題(エージェントとして自分自身を認識し、目標のために行動する)の2つのスイートで実施されました。
ステルス課題の一部では人間に近い性能を示すものの、全体としてはまだ課題を抱えています。状況認識課題の大部分では苦戦しており、現時点では懸念されるレベルの状況認識能力には達していないと結論付けられています。
Evaluation Details (評価の詳細)
これらの評価は、「Deep Think」アルゴリズムの初期実装を用いて行われました。現在ユーザーに展開されているバージョンとは、思考プロンプトや生成処理の設定にわずかな違いがありますが、これらの違いは評価結果に大きな影響を与えないと考えられています。
Correctness Checks (正確性チェック)
各リスク領域において、モデルの生成する応答(エージェントの軌跡)がサンプルされ、評価環境における誤った失敗や潜在的なバグがないか、目視検査と「Gemini 2.5 Pro」を用いたトリアージ(優先順位付けと問題特定)の組み合わせによって確認されました。評価中に無効な実験は見つからず、いくつかのケースでは、モデルが創造的な解決策を提示し、タスクを成功させたことも確認されています。
Mitigations (緩和策)
CBRN Uplift 1 Critical Capability Levelに到達している可能性を排除できないため、Googleは予防的なアプローチを取り、一連の緩和策を導入して「Gemini 2.5 Deep Think」をリリースしました。
- Threat modeling (脅威モデリング)
内部の専門家と外部のパートナーが協力し、低リソースのアクターが大量死傷イベントを引き起こす可能性のある特定の脅威モデルを開発し、継続的に改善しています。彼らは特に、攻撃を実行する上で複雑で不可欠な「ボトルネック」となるステップを特定し、理解することに焦点を当てています。AIシステムが、ジェネレーティブAIシステムを使用しない場合と比較して、これらのステップをアクターが進行するのを支援できるかどうかを評価しています。 - Model-level and system-level interventions (モデルレベルおよびシステムレベルの介入)
モデルレベルとシステムレベルの介入を用いて、「Gemini 2.5 Deep Think」がCBRN攻撃に実質的に役立つと判断される支援を提供することを防いでいます。これらは、レート制限(一定時間内の使用量制限)と組み合わされることで、悪意のあるアクターがモデルから有害な情報を抽出することを大幅に困難にし、組織的な悪用を検出・対処する介入の効果を高めます。これらの介入は、新たな悪用タイプに対応するために迅速に展開できるようになっています。 - Usage monitoring (利用状況モニタリング)
多層的なオフライン利用状況モニタリングシステムが導入されています。第一層は、利用状況をレビューし、潜在的な悪用をフラグ付けする自動プロセスです。第二層は、フラグ付けされたプロンプトと応答を、CBRN専門家を含む人間がレビューするものです。このオフラインモニタリングは、リアルタイムシステムよりも時間がかかる場合がありますが、より強力な分析が可能です。これにより、緩和策の有効性を確認し、モデルがどのように悪用されているかを理解し、新たな悪用タイプを特定してリアルタイムの緩和策などを改善するために活用されます。 - Account enforcement (アカウント強制)
人間によるレビューの結果、悪質で真に悪用と判断されたケースは、アカウントの停止を含む措置の対象となる可能性があります。 - Mitigations red teaming (緩和策のレッドチーミング)
CBRNの専門家からなるレッドチームは、モデルから危険な応答を引き出そうと試みるだけでなく、緩和策の有効性を継続的にテストしています。これには、普遍的な「ジェイルブレイク」(AIの安全ガードレールを回避する手法)や特定のクエリに対する堅牢性のテストも含まれます。これらのレッドチームからのフィードバックは、緩和策のスイート(一連の対策)を改善するために活用されます。
Frontier Safety Summary (フロンティア安全性の概要)
最終的に、「Gemini 2.5 Deep Think」は、Googleの「Frontier Safety Framework (FSF)」で定義されたクリティカル能力レベル(CCLs)に対して評価されました。モデルは、サイバーセキュリティのCyber Uplift Level 1 CCLにおいて引き続き早期警告しきい値レベルに到達しており、CBRN Uplift Level 1 CCLにおいても早期警告しきい値に到達したとされています。
CBRN Uplift Level 1 CCLに到達したかどうかを最終的に判断するにはさらなる評価が必要ですが、特定されたCBRNリスクに対しては緩和策が既に講じられています。これらの緩和策には、不適切な情報をモデルが提供するのを防ぐ介入、そして悪用を特定し介入するための利用状況モニタリングやアカウント強制が含まれます。FSFの原則に基づき、これらの緩和策とレッドチーミングの結果に基づいて内部的な安全事例が作成され、リリース前にGoogle DeepMindの責任・安全評議会(RSC)によってレビューされました。
まとめ
「Gemini 2.5 Deep Think」は、単に情報を生成するだけでなく、高度な推論能力と並列思考、そしてマルチモーダルな理解を兼ね備えた、まさに次世代のAIモデルと言えるでしょう。特に数学やコード生成といった、論理的思考が求められる分野での飛躍的な性能向上は、AIが人間の認知能力のより深い領域に踏み込んでいることを示しています。
しかし、その強力な能力ゆえに、Google DeepMindは、CBRNリスクやサイバーセキュリティ、欺瞞的なアライメントといった「フロンティア安全性」の課題に真摯に向き合っています。モデルカード全体を通して、厳格な評価プロセスと、多層的な緩和策が講じられていることが強調されており、これはAIを社会に安全かつ責任ある形で展開していくための重要な姿勢です。
「Gemini 2.5 Deep Think」の登場は、科学的発見やアルゴリズム開発など、これまで人間の専門知識と創造性が不可欠だった領域にAIが貢献する可能性を大きく広げます。同時に、AIの進化がもたらす潜在的なリスクに対して、開発者がいかに先手を打って対策を講じていくか、その重要性も改めて浮き彫りになりました。
これからのAIの進化が、私たちの社会にどのような変革をもたらすのか、引き続き注目していきましょう。








