
はじめに
本稿では、Google CloudのVertex AI上で提供されている生成AIモデル「Gemini」に新たに追加されたlogprobsという機能について、Google AI for Developers Blogの「Unlock Gemini’s reasoning: A step-by-step guide to logprobs on Vertex AI」をもとに解説します。
これまで、AIがなぜその回答を生成したのか、その判断根拠は開発者にとってブラックボックスでした。しかし、logprobs機能を使うことで、AIが単語を選ぶ際の「迷い」や「確信度」を数値で取得できるようになります。これにより、私たちはAIの思考プロセスをより深く理解し、これまで以上にスマートで信頼性の高いアプリケーションを開発することが可能になります。
参考記事
- タイトル: Unlock Gemini’s reasoning: A step-by-step guide to logprobs on Vertex AI
- 著者: Eric Dong
- 発行元: Google AI for Developers Blog
- 発行日: 2025年7月16日
- URL: https://developers.googleblog.com/ja/unlock-gemini-reasoning-with-logprobs-on-vertex-ai/
要点
- logprobsは、生成AIモデルが各トークン(単語など)を選択した確率の対数値である。
- この値を見ることで、モデルがそのトークンをどれくらいの確信度で選択したかを把握できる。
- logprobsは、モデルの回答の曖昧さを検出したり、信頼度に基づいて処理を分岐させたりするのに役立つ。
- 具体的な応用例として、高信頼性な分類タスク、文脈に応じた動的オートコンプリート、RAG(検索拡張生成)システムの定量的評価などが挙げられる。
- この機能はVertex AIのGemini APIで利用可能であり、APIリクエスト時に簡単な設定を追加するだけで有効化できる。
詳細解説
logprobsとは? – モデルの「思考」を覗く新しい窓
logprobs(Log Probability、対数確率)とは、一体何でしょうか?
生成AI、特に大規模言語モデル(LLM)は、文章を生成する際に、次に来るべき単語(専門的にはトークンと呼びます)を確率的に予測しています。例えば、「人生で最も素晴らしいことは」という文章の次には、「愛」「健康」「学び」など、様々な単語が候補として挙がります。モデルは、その中から最も確率が高いと判断した単語を選んで文章を繋げていきます。
logprobsは、この「確率」を対数で表現した数値です。なぜ単なる確率ではなく対数を使うかというと、非常に小さな確率を扱う際の計算上の利点があるためですが、ここでは「モデルの確信度を示すスコア」と理解してください。
- 確率は0から1の間の値を取ります(1が100%の確信)。
- 対数確率(logprob)は、0以下の負の値を取ります。
- 確信度が100%(確率1)の場合、logprobは0になります。
つまり、logprobsの値が0に近いほど、モデルはそのトークンを選んだことに高い自信を持っていることを意味します。逆に、値が-10のように0から離れた負の数であるほど、モデルはその選択に自信がなかった(他の選択肢と迷った)ことを示します。
この機能により、開発者はモデルが生成した出力トークンだけでなく、そのトークンを選んだ際の「確信度」や、選ばれなかった他の候補トークンの「惜しさ」まで知ることができるのです。
環境の設定
SDKのインストール
pip install -U -q google-genaiプロジェクトの設定
PROJECT_ID = "[your-project-id]"クライアントとモデルの初期化
from google import genai
client = genai.Client(vertexai=True, project=PROJECT_ID, location="global")
MODEL_ID = "gemini-2.5-flash"logprobsの有効化と使い方
Vertex AIのGemini APIでlogprobsを有効にするのは非常に簡単です。APIリクエストを送る際のgeneration_configに、2つのパラメータを追加するだけです。
- response_logprobs=True: これにより、モデルが最終的に選んだトークンのlogprobsが返されます。(デフォルトはFalse)
- logprobs=[整数]: これにより、選ばれなかった候補(代替トークン)のlogprobsも指定した数だけ返されます。1から20までの値を設定できます。
以下は、ある文章が「ポジティブ」「ネガティブ」「ニュートラル」のいずれに分類されるかをモデルに尋ねる際のPythonコード例です。
from google.genai.types import GenerateContentConfig
prompt = "I am not sure if I really like this restaurant a lot."
response_schema = {"type": "STRING", "enum": ["Positive", "Negative", "Neutral"]}
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
generation_config=GenerateContentConfig(
response_mime_type="application/json",
response_schema=response_schema,
response_logprobs=True, # ここで有効化
logprobs=3, # 上位3つの候補を取得
),
)結果の処理をする関数
def print_logprobs(response):
"""
Print log probabilities for each token in the response
"""
if response.candidates and response.candidates[0].logprobs_result:
logprobs_result = response.candidates[0].logprobs_result
for i, chosen_candidate in enumerate(logprobs_result.chosen_candidates):
print(
f"Token: '{chosen_candidate.token}' ({chosen_candidate.log_probability:.4f})"
)
if i < len(logprobs_result.top_candidates):
top_alternatives = logprobs_result.top_candidates[i].candidates
alternatives = [
alt
for alt in top_alternatives
if alt.token != chosen_candidate.token
]
if alternatives:
print("Alternative Tokens:")
for alt_token_info in alternatives:
print(
f" - '{alt_token_info.token}': ({alt_token_info.log_probability:.4f})"
)
print("-" * 20)このリクエストに対し、モデルは例えば次のようなlogprobs情報を返します。
- 選ばれたトークン: ‘Neutral’ (logprob: -0.0214)
- 代替トークン:
- ‘Positive’: (logprob: -4.8219)
- ‘Negative’: (logprob: -5.6293)
この結果から、「Neutral」のlogprobが-0.0214と0に非常に近いため、モデルはこの分類に絶大な自信を持っていることが分かります。一方で、「Positive」や「Negative」はモデルにとって可能性の低い選択肢だったことも一目瞭然です。
ユースケース
ユースケース1:よりスマートな分類タスク
logprobsを使うことで、単に分類結果を得るだけでなく、その結果の信頼性を評価し、より高度なシステムを構築できます。
- 曖昧さの検出と人間によるレビュー
例えば、顧客からのフィードバックを自動で感情分析するシステムを考えます。もしモデルが「ポジティブ」と「ネガティブ」のlogprobsの差が非常に小さい回答(例:-1.5と-1.6)を出してきたら、それは「モデルが判断に迷っている」というサインです。このような曖昧なケースを検出し、自動で人間の担当者にレビューを依頼するといったワークフローを組むことができます。 - 信頼度に基づく処理の分岐
医療診断の補助など、極めて高い精度が求められるアプリケーションでは、「モデルの確信度が95%以上の場合のみ、結果を自動で採用する」といったルールを設定できます。logprobsの値を実際の確率(例:math.exp(logprob))に変換し、その値が特定のしきい値を超えているかで処理を分岐させることが可能です。
ユースケース2:文脈に応じた動的オートコンプリート
logprobsは、リアルタイムで変化するユーザーの入力に対して、気の利いた提案をするオートコンプリート機能にも応用できます。
元の記事では、「The best thing about living in Toronto is the」という文章を1単語ずつ入力していった場合に、モデルが予測する次の単語がどのように変化するかが示されています。
| 入力されたテキスト | 次の単語の予測 Top 3 (確率) |
| The | ‘cat’ (39.2%) |
| The best | ‘thing’ (84.4%) |
| The best thing about living in | ‘Europe’ (30.8%) |
| The best thing about living in Toronto is the | ‘diversity’ (99.8%) |
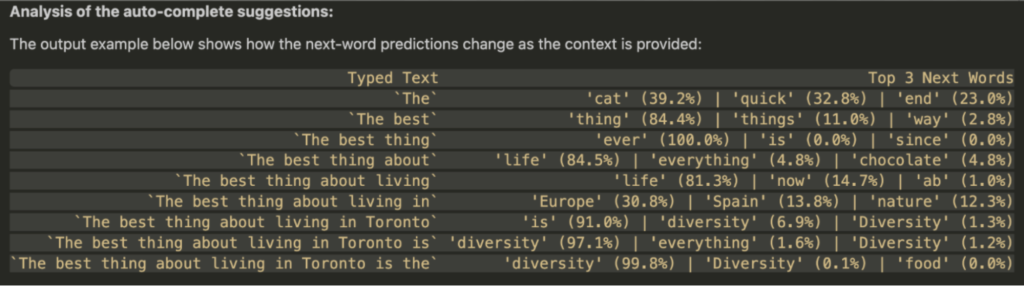
このように、文脈が具体的になるにつれて、モデルの予測が「cat」のような一般的な単語から、「diversity(多様性)」といったトロントの特性を表す非常に確信度の高い単語へと変化していく様子がlogprobsを通じて分かります。これにより、ユーザーが何をタイプしようとしているかを先読みし、より精度の高い候補を提示できます。
ユースケース3:RAGシステムの定量的評価
RAG(Retrieval-Augmented Generation、検索拡張生成)とは、外部の知識データベースから関連情報を検索し、その情報を基に回答を生成する技術です。このRAGシステムの性能を評価する上で、logprobsは強力な武器となります。
考え方はシンプルで、「モデルが正確な情報源(コンテキスト)を与えられた場合、事実に基づいた回答を生成する際の確信度は高くなるはずだ」というものです。つまり、生成された回答全体の平均logprobsを計算することで、その回答が提供された情報源にどれだけ忠実であるか(=グラウンディングされているか)を定量的にスコアリングできます。
実験では、3つのシナリオで平均logprobsを比較しています。
| シナリオ | スコア (平均logprob) | 生成された回答の例 |
| 良い検索結果 | -0.0076 | Quantum-Entangled Data Core (QEDC) |
| 悪い検索結果 | -0.1144 | 提供されたコンテキストには言及されていません。 |
| 検索なし (比較対照) | -0.2336 | プロジェクト・アダムのコア技術はディープラーニングです。 |
結果は一目瞭然です。最も関連性の高い情報が与えられた「良い検索結果」のシナリオでは、スコアが最も0に近く、モデルが非常に高い確信度で回答を生成していることが分かります。この指標を使えば、RAGシステムが適切な情報を検索できているかを自動で評価し、改善サイクルを効率的に回すことができます。
まとめ
本稿では、Vertex AIのGemini APIに搭載されたlogprobs機能について解説しました。この機能は、単なるデバッグツールにとどまりません。AIの判断プロセスを可視化し、その信頼性を数値で把握することで、私たちは以下のような、より高度で信頼性の高いアプリケーションを構築できます。
- 分類タスクの信頼性向上
- 文脈を理解する動的なユーザーインターフェース
- RAGシステムの自動評価と改善
logprobsは、AIとの対話をより深く、より有意義なものにするための鍵です。ぜひこの機能を活用して、あなたのアプリケーションを次のレベルへと進化させてみてください。








