はじめに
AIの急速な進化は目覚ましいものがありますが、その一方で「本当に安全なの?」と疑問に思う方もいるのではないでしょうか。私たちが日々利用するAIシステムが、意図しない問題を引き起こしたり、最悪の場合、社会に大きなリスクをもたらしたりする可能性も指摘されています。
本稿では、AIの安全性について、米国のFuture of Life Institute (FLI) という非営利団体が発行した「AI Safety Index Report Summer 2025」というレポートを解説します。このレポートは、AIが人類にとって良い方向に進むよう、大規模なリスクを減らし、変革をもたらす技術を導くことを目標としているFLIが、主要なAI企業7社の安全管理への取り組みを独立した立場で評価したものです。2024年12月に最初のレポートが公開され、今回の2025年夏版では、OpenAI、Anthropic、Google DeepMind、Meta、xAI、Zhipu AI、そして今回初参加のDeepSeekの7社が評価対象となっています。
参照記事:
- 記事タイトル:FLI AI Safety Index Report Summer 2025
- 発行日:2025年7月17日
- 参照元URL:https://futureoflife.org/wp-content/uploads/2025/07/FLI-AI-Safety-Index-Report-Summer-2025.pdf
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
今回のレポートでは、AI業界がAIシステムの安全性管理に関して、その急速な技術進歩に追いついていない現状が浮き彫りになりました。特に、将来的に人間と同等かそれ以上の能力を持つと予測される「汎用人工知能(AGI)」が引き起こす可能性のある「壊滅的リスク」に対する準備が不足していることが指摘されています。
主な評価結果は以下の通りです。
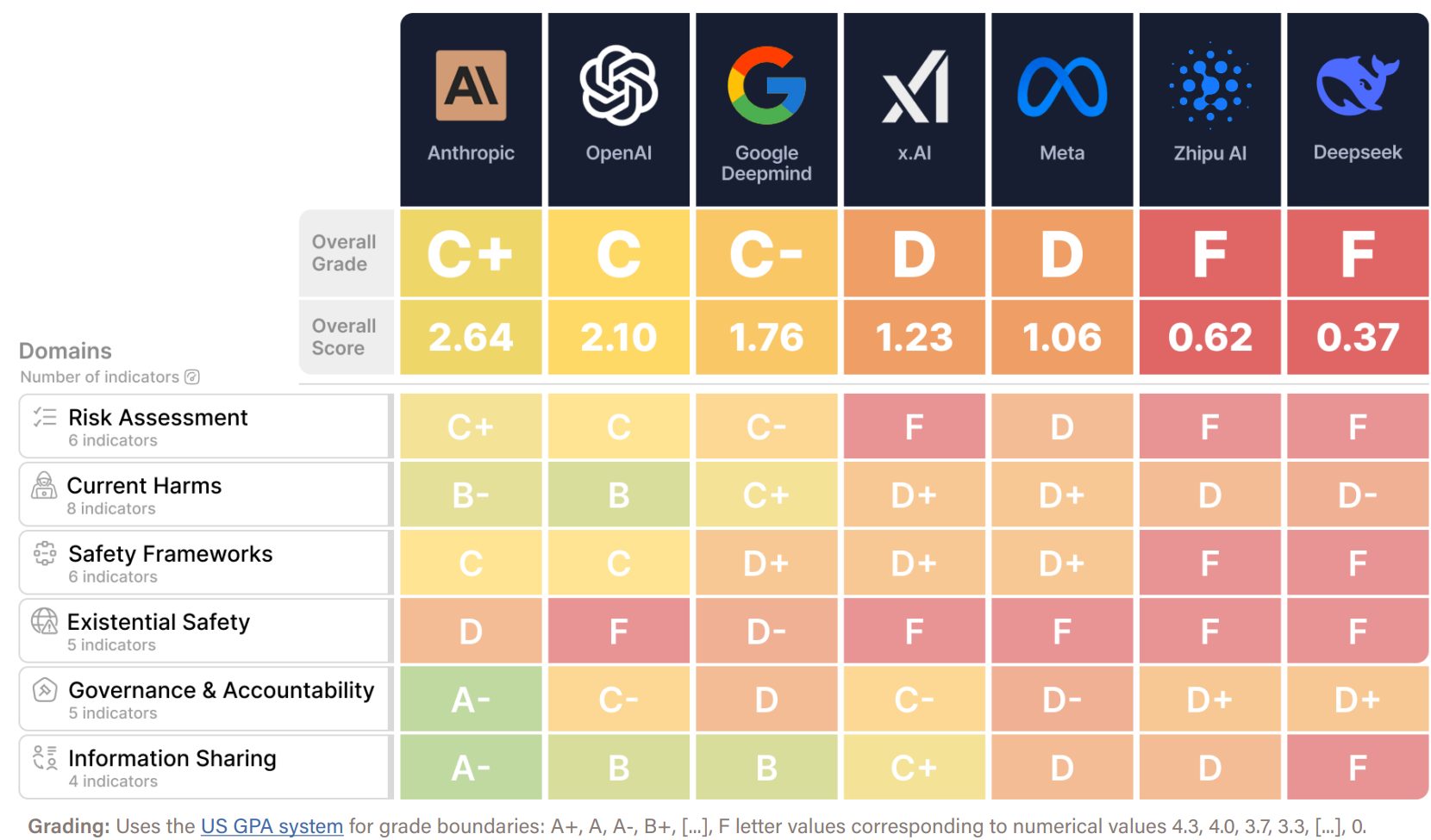
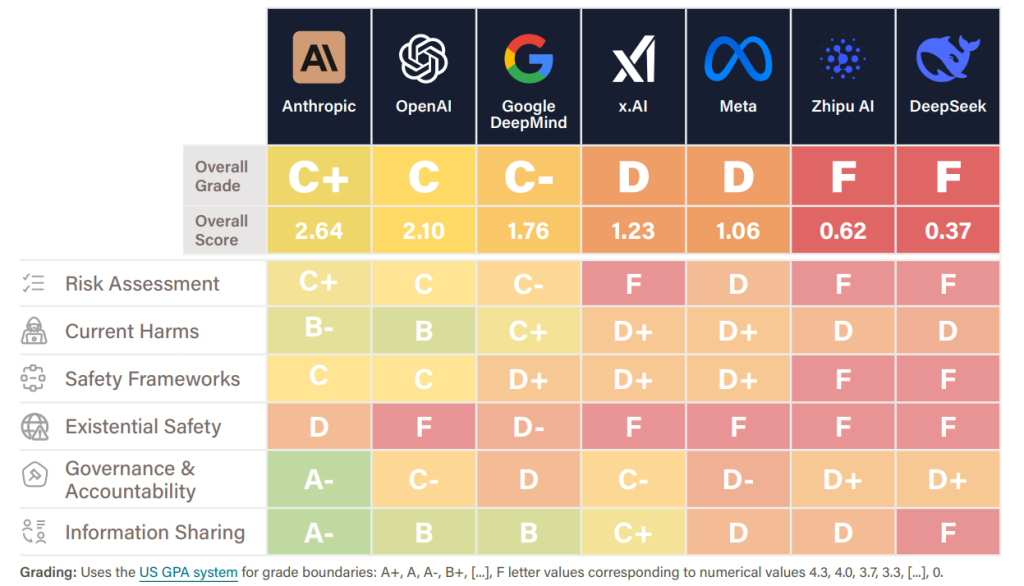
- 全体評価は低水準:対象となった7社の中で、最も高い評価を得たのはAnthropicの「C+」でした。これにOpenAIが「C」、Google DeepMindが「C-」と続き、x.AIとMetaは「D」、中国のZhipu AIとDeepSeekは「F」と、全体的に低い評価にとどまっています。これは、業界をリードする企業ですら、十分な安全基準を満たせていないことを示しています。
- Anthropicの健闘:Anthropicは、リスク評価の分野で最も優れた成績を収めました。特に、バイオテロリズムのリスクに関する人間参加型のトライアルを実施した唯一の企業であること、ユーザーデータで学習しないことでプライバシー保護に優れていること、最先端のアラインメント研究(AIが人間の意図や価値観に沿って行動するようにする研究)を行っていることなどが評価されています。
- OpenAIの強みと課題:OpenAIは全体で2位となり、ホイッスルブロウイングポリシー(内部告発規程)を公開した唯一の企業であること、リスク管理のアプローチが堅固であること、モデル公開前のリスク評価に積極的に取り組んでいることなどが評価されました。しかし、そのホイッスルブロウイングポリシーは、メディア報道で制約の多い内容が明らかになった後に公開されたものでした。
- AGIへの準備不足:多くの企業が10年以内にAGIの実現を目指していると主張しているにもかかわらず、どの企業も「実存的安全性(AIが人類の存続を脅かすような極端なリスク)」の計画において「D」以上の評価を得られませんでした。ある評価者からは、「人間レベルのAIに向けて競争しているにもかかわらず、どの企業も首尾一貫した、実行可能な計画を持っているとは言えない」と指摘されており、この乖離は「深く憂慮すべき」とされています。
- 危険な能力評価の不足と不透明性:バイオテロリズムやサイバーテロリズムのような大規模リスクにつながる危険な能力のテストを実質的に報告している企業は、Anthropic、OpenAI、Google DeepMindの3社のみでした。しかも、これらのリーダー企業ですら、評価の「方法論や根拠」が明確でなく、「危険な能力が重大な被害を防ぐのに間に合うように検出されているか、非常に低い信頼性しかない」と懸念が示されています。
- 自主規制の限界と企業間の格差:AIの能力開発はリスク管理の実践よりも速く進んでおり、企業間の安全対策の格差が広がっています。共通の規制がないため、一部の企業はより強力な制御を採用する一方で、基本的な安全対策を怠る企業もあり、自主的な誓約だけでは不十分であることが浮き彫りになりました。
- ホイッスルブロウイングポリシーの透明性不足:ホイッスルブロウイングポリシーの透明性は、業界全体の弱点として残っています。安全上重要な産業では一般的な慣行ですが、評価対象企業の中で完全なポリシーを公開しているのはOpenAIのみでした。しかも、これもメディア報道でその制限的な条項が明らかになった後に公開されたものです。
- 中国企業への評価と文化の違い:中国のAI企業であるZhipu AIとDeepSeekは、全体的に「F」評価を受けました。これは、レポートの評価基準に「自己統治」や「情報共有」といった規範が含まれており、これらが中国の企業文化ではあまり重視されていないことが影響しています。中国ではすでに先進的なAI開発に関する規制があるため、AI安全の自己統治への依存度が低いという背景も考慮されています。
これらの結果から、AI業界は競争と技術的な野心が安全インフラや規範をはるかに上回っており、規制が十分でない現状が明らかになっています。企業が10年以内に人間と同等、あるいはそれ以上の能力を持つAGIの実現という目標を追求するにつれて、この不均衡はより危険なものとなると考えられます。

詳細解説
レポートの項目ごとに解説していきます。なお、レポートの項目1はSummaryとなっていて、重複する部分があるため、省略しています。
2 Introduction (はじめに)
AIシステムの能力と自律性が前例のない速さで向上している現状について述べています。多額の投資と技術的なブレークスルーによって、これらの「汎用AIシステム(GPAI)」は、専門的なツールから多用途に利用できるエージェントへと変化し、その展開はますますリスクの高い環境で行われています。この傾向は、悪意のある利用、システム障害、そして人間による意味のある制御の喪失など、深刻なリスクをもたらしています。そのため、GPAIシステムの開発と展開方法に対する独立した監視が、これまで以上に緊急に求められているのです。
この「AI Safety Index(AI安全性指標)」は、その緊急性に対応するために開発されました。Future of Life Institute (FLI) が、AI分野の第一線で活躍する独立した専門家たちからなるレビューパネルと協力して作成したこのインデックスは、世界をリードするAI企業が、ますます強力になるAIシステムをどれほど責任を持って開発・展開しているかを独立した視点から評価します。特に、リスク管理フレームワーク、第三者による監視、内部告発ポリシーといった、組織的なセーフガード(安全対策)に焦点を当てています。各企業は6つのドメインにわたる33の指標で評価され、そのスコアは専門家にも非専門家にも分かりやすい形式で提示されています。
2024年12月に初回版がリリースされて以降、AIリスクに対する世界的な認識は高まり続けています。英国で開催されたAI安全サミットの要請で作成された初の「国際AI安全レポート」では、壊滅的な結果の可能性を認めつつ、AIリスクと潜在的な軽減戦略に関する現在の科学的理解がまとめられました。また、シンガポールでは、業界、政府、学術界の著名な専門家たちが集まり、「グローバルAI安全研究優先事項に関するシンガポール合意」を締結し、高度なAIからのリスクに対処するための主要な研究優先事項を概説しました。これらの進展は、AIの能力が進むにつれて、その安全性を確保するためにアラインメント研究(AIを人間の価値観や目標に合致させる研究)への緊急な投資と、リスク管理の大幅な改善が求められているという国際的な合意が高まっていることを裏付けています。
2025年夏版のFLI AI安全性指標では、OpenAI、Anthropic、Google DeepMind、Meta、xAI、Zhipu AI、そして今回初めてDeepSeekという7つの最先端AI企業を評価対象としています。評価指標は、進化するAIの展開方法や安全基準を反映して更新・改善されています。このインデックスは、企業の行動を追跡し、新たなベストプラクティスを特定し、重要なギャップを明らかにするための、実用的で公開されたツールとなることを意図しています。企業のリスク管理の実践を可視化し、比較可能にすることで、責任あるAI開発へのインセンティブを強化し、安全に関するコミットメントと実際の行動とのギャップを埋めることを目指しています。
3 Methodology (方法論)
AI開発の最先端における安全対策を評価するには、具体的な実装だけでなく、公言された方針、コミットメント、多様な組織における透明性のレベルを捉え、適切に評価できる柔軟で進化する手法が必要です。
このセクションでは、AI安全性指標がAI企業をどのように評価し、採点するのかが説明されています。指標の設計と構造、証拠収集とデータソース、独立したレビュープロセスについて詳しく述べられ、評価の長所と限界を理解するために必要なコンテキストをステークホルダーに提供することを目的として、方法論を完全に透明にしていると記載されています。
3.1 Companies Assessed (評価対象企業)
2025年のFLI AI安全性指標は、主要な汎用AI開発企業7社(Anthropic, OpenAI, Google DeepMind, Meta, Zhipu AI, x.AI, DeepSeek)を評価しています。これらの企業はAI能力開発のグローバルな最前線を代表しており、その選定は主要なモデルの性能に基づいて行われました。中国企業のZhipu AIとDeepSeekが含まれているのは、指標が世界の主要な開発者を代表するものであるというFLIの意図を反映しています。特に、DeepSeekが今回初めて評価対象に加わったのは、効率的なモデルトレーニングにおける技術的成果と、中国のAIエコシステムにおける影響力の増大が認められたためです。今後、競争環境が変化すれば、インデックスの評価対象企業も変更される可能性があるとされています。 なお、人工汎用知能(AGI)の構築を目指しているものの、まだフロンティアモデルを展開していない企業(例:Safe Superintelligence Inc.など)は評価対象から除外されています。
3.2 Index Design and Structure (インデックスの設計と構造)
AI安全性指標は、責任あるAI開発と展開の様々な側面を捉える6つの主要なドメインにわたる33の指標で企業を評価しています。各ドメインには複数の指標が含まれており、企業間の責任あるAIプラクティスの違いが明らかになるように設計されています。指標は以下の5つの基準に基づいて選定されました。
- 高いシグナル値(High signal value): 企業による投資と優先順位における実質的な違いを明らかにするもの。
- 実装への焦点(Implementation focus): 過度に強調されたコミットメントよりも、実証された対策を優先する。
- 情報の入手可能性(Information availability): 評価に必要な十分な公開証拠が存在すること。
- 明確な定義(Clear definition): 企業間で一貫した評価を可能にする。
- リーダーシップの認識(Leadership recognition): 十分な基準を維持しつつ、優れた実践を評価する。
これらの33の指標は、例えば以下のようなドメインと項目に分けられています。
- リスク評価 (Risk Assessment):
- 危険な能力の評価 (Dangerous Capability Evaluations): サイバー攻撃、バイオテロなど、AIシステムが悪意のある能力を評価しているか。
- 人間性向上試験 (Human Uplift Trials): AIがユーザーの危害能力をどの程度高めるかを測定する実験を行っているか。
- 現在の害悪 (Current Harms):
- モデルの安全性・信頼性 (Model Safety / Trustworthiness): スタンフォード大学のHELM安全ベンチマークなどで、モデルが公平性や有害な振る舞いに対する耐性など、主要な安全指標でどのように機能するか。
- 水掛け論 (Watermarking): AIが生成したコンテンツが識別可能な形でマークされているか(例:合成画像がAIによって作られたことを示す目に見えない透かし)。これは、誤情報や悪用を防ぐのに役立ちます。
- ユーザープライバシー (User Privacy): ユーザーデータがモデルによって不適切に利用されないよう、どの程度保護されているか。
- 安全フレームワーク (Safety Frameworks):
- リスク識別 (Risk Identification): 企業がリスクを体系的に特定しているか。
- リスク分析と評価 (Risk Analysis and Evaluation): 抽象的なリスク許容度を具体的で測定可能な閾値に変換しているか。
- 存在リスク安全 (Existential Safety):
- 存在リスク安全戦略 (Existential Safety Strategy): 人間を超える能力を持つ将来のAIシステムによる壊滅的・存在的なリスクを管理するための具体的戦略を公開しているか。
- ガバナンスと説明責任 (Governance & Accountability):
- 内部告発ポリシーの透明性 (Whistleblowing Policy Transparency): 内部告発システムがどの程度公開され、アクセスしやすいか。
- 企業構造と責務 (Company Structure & Mandate): 企業の法的・ガバナンス構造が、利益よりも安全性を優先するコミットメントを含んでいるか。
- 情報共有 (Information Sharing):
- システムプロンプトの透明性 (System Prompt Transparency): 展開されているAIモデルで使用されている実際のシステムプロンプトを公開しているか。システムプロンプトとは、AIの振る舞いを決定づける指示や設定のことです。
3.3 Related Work and Incorporated Research (関連研究と組み込まれた研究)
2025年のインデックスは、業界内の透明性と説明責任を推進するいくつかの注目すべき取り組みから着想を得ており、それらを補完しています。特に包括的な取り組みとして、SaferAIによるAI企業の公開安全フレームワークの詳細な分析とランキング、そしてZach Stein-PerlmanによるAILabWatch.orgとAISafetyClaims.orgの2つのプロジェクトが挙げられます。これらのプロジェクトは、主要なAI企業が高度なAIシステムからの壊滅的なリスクを回避するためにどのように取り組んでいるかについて、詳細な技術的評価を提供しています。
また、2025年のインデックスは、信頼できる研究機関が主導する既存の比較分析を適切に組み込んでいます。例えば、「安全フレームワーク」ドメインでは、AIリスク管理において専門知識を持つ非営利研究機関SaferAIによる、企業の公開安全フレームワークの詳細な評価を取り入れています。さらに、「存在リスク安全」ドメインでは、AILabWatch.orgの技術的なAI安全研究のトラッカーを組み込んでいます。また、「ガバナンスと説明責任」ドメインにおける企業の内部告発ポリシーの品質に関する調査は、AIの最前線で働く個人がリスクを報告することを支援する非営利団体OAISISの支援により可能になりました。 「現在の害悪」ドメインでは、スタンフォード大学の基礎モデル研究センターが提供するTrustLLMベンチマーク、HELM AIR-Bench、HELM Safetyベンチマークを含む、主要な安全ベンチマークにおけるフラッグシップモデルの性能を評価しています。さらに、英国AIセキュリティ研究所のGray Swan Arenaにおけるレッドチームチャレンジと、Ciscoによるモデルセキュリティ分析の結果も掲載されています。
3.4 Data Sources and Evidence Collection (データソースと証拠収集)
2025年AI安全性指標の証拠収集プロセスは、2025年3月24日から6月24日の間に行われました。これは、公開されている資料(モデルカード、研究論文、ベンチマーク結果など)と、業界における特定の透明性のギャップ(内部告発者の保護や外部モデル評価に関する透明性など)に対処するために設計された、企業へのアンケート調査への回答を組み合わせて行われました。データ収集プロセス全体を通じて、FLIは偏りを最小限に抑え、企業間で一貫した検索プロトコルと証拠基準を適用することで、公平な評価を確保することを目指しました。
基礎調査では、企業がAIシステムとリスク管理の実践について公開している文書が主要な証拠基盤となっています。これには、能力と限界を詳述した技術的なモデルカード、安全方法論に関する査読付き研究論文、公式のポリシー文書、安全コミットメントを概説するブログ記事、リーダーシップインタビューや政府機関での証言の記録や転写などが含まれます。また、外部の安全ベンチマークにおけるフラッグシップモデルの性能指標、信頼できるメディアからのニュース報道、独立した研究機関による関連評価の報告書も組み込まれています。
公開情報を補完するために、FLIは現在の自主的な情報開示のギャップに対処する34問のアンケートを作成しました。このアンケートは5月28日にEメールで送付され、企業には6月17日まで回答期間が与えられました。2024年冬版のインデックスと比較して、今回のアンケートはより短く、内部告発ポリシー、外部第三者モデル評価、内部AI展開の実践など、業界の現在の透明性基準が不足しているリスク管理関連のドメインに特化していました。OpenAI、Zhipu AI、xAIの3社から回答があり、評価対象企業の43%に相当します。Anthropic、Google DeepMind、Meta、DeepSeekは回答を提出していません。
得られた証拠は、評価シート(Appendix A)に構造化されました。評価シートは6つのドメインに分かれており、現在のインデックスの33の指標ごとに企業固有の情報が含まれています。各指標について、評価シートにはその範囲の定義、指標を含める理由、および関連文献への参照が記載されています。企業固有の情報のすべてのソースは、ハイパーリンク付きで関連する場所に埋め込まれています。企業からの直接的な一次ソースが、二次的な報道よりも優先されましたが、調査ジャーナリズムは自発的に開示されない慣行を明らかにする上で貴重な洞察を提供しました。指標がアンケートの質問と重複する場合、関連するアンケートの回答が評価シートで強調表示されました。
3.5 Grading Process and Expert Review (採点プロセスと専門家によるレビュー)
2025年AI安全性指標の採点プロセスは、選定された指標に対する企業の性能を公平かつ適切に評価するために設計されました。著名な独立専門家からなるレビューパネルが、各指標に関する企業固有の証拠を評価し、これらのドメインにおける企業の性能を表すドメインレベルの成績(A+からF)を付与しました。
レビューパネルは、インデックスのスコアが権威ある判断に基づくことを保証するため、6名の主要な独立専門家で構成されました。パネルメンバーは、その専門知識と利益相反の欠如に基づいて選ばれました。パネルの構成は、技術的なAI安全性のトピックからガバナンスとポリシーのドメインまで多岐にわたるため、多様な背景を反映しています。そのため、アラインメントと制御を専門とする著名な機械学習教授と、非営利セクターのガバナンス専門家の両方が含まれています。パネルの構成は、前回のインデックスバージョンからほとんど変更されていません。
採点期間は6月24日から7月9日まででした。レビューアは証拠を検討した後、各企業に対しドメインごとにアルファベットの成績(A+からF)を付与しました。各成績には、短い正当化と改善勧告を付けることができました。また、複数の企業に適用されるフィードバックや判断の説明が必要な場合は、ドメインレベルのコメントを提供することもできました。全てのレビューアが全てのドメインを採点したわけではなく、専門家は自身の専門分野に関連するドメインを割り当てられました。重要な点として、ドメイン内の指標間に固定の重み付けは課されませんでした。このアプローチにより、専門家レビューアは、最も重要と見なす側面に判断を適用することができました。レビューアに提供された評価基準は、企業規模や地域に関係なく一貫した期待を確保するため、相対的なランキングではなく絶対的な性能基準に基づいていました。最終的なドメインスコアは、特定のドメインにおける全てのレビューアの成績を平均して算出されました。総合評価は、全てのドメインの平均値です。
3.6 Limitations (限界)
FLIの方法論にはいくつかの重要な限界があり、インデックスの結果を解釈する際には考慮すべきだと述べています。
- 情報の入手可能性と検証 (Information Availability and Verification):
評価は主に公開情報に依存しており、これが根本的な制約となります。企業が情報開示レベルを管理しているため、透明性の低さと実装の不十分さを区別することが困難です。AI Safety Indexの指標は、企業間の意味のある違いを特定できる透明性の制約を考慮して設計されています。例えば、モデルウェイトを保護するためのサイバーセキュリティ投資など、公開されることがほとんどない重要な実践は評価できません。33の指標は、意味のある証拠が存在する重要な実践のサブセットであり、全ての安全側面を網羅的に評価するものではありません。さらに、企業の主張を独立して検証することはできず、公式報告が真実であると仮定する必要があり、これは関係するリスクの重大さを考えると大きな制約となります。
- 地理的および文化的文脈 (Geographic and Cultural Context):
FLIの方法論は、西洋の学術的文脈で開発されたものであり、西洋中心的な側面が強く、中国企業であるZhipu AIとDeepSeekの評価に悪影響を与える可能性があります。例えば、自己統治や情報共有といった規範が重視されていますが、これらは中国の企業文化でははるかに一般的ではありません。中国は既に生成AIの規制を導入しているため、企業がAI安全に関して自己規制を行うインセンティブが低いという側面もあります。これは、他の企業が拠点を置く米国や英国とは対照的であり、これらの国ではまだフロンティアAIに関するそのような規制は通過していません。さらに、情報の入手可能性は地域によって大きく異なり、米国拠点の企業は詳細なモデルカードから公開安全フレームワークに至るまで広範な文書を提供する場合がありますが、中国企業は異なる規制枠組みや透明性に関する文化規範の下で運営されており、直接比較が困難です。言語の壁もこれらの課題を複雑にし、非英語の資料の評価に影響を与える可能性があります。いくつかの指標は、根本的に異なる文脈で運営されている中国企業には適用性が限定的です。
- 方法論的制約 (Methodological Constraints):
観測可能で文書化可能な実践に焦点を当てているため、安全文化のような重要ながら測定が困難な要素を過小評価する可能性があります。また、6名のパネルメンバーは多様な専門知識を持っていますが、全ての関連ドメインを網羅することはできません。レビューの背景は必然的に評価に影響を与え、指標の重み付けにおける柔軟性が一貫性の欠如を招く可能性もあります。
FLIは、これらの限界を軽減するために、情報源、方法論、レビュー資料の厳格な文書化を目指しています。読者は、AI安全対策を理解するための多くの情報源の一つとして、インデックスの結果を解釈すべきだと述べています。FLIは、建設的な批判や有用な提案を歓迎し、全ての反復でプロジェクトを改善することにコミットしています。
4 Results (結果)
総合ランキングでは、AnthropicがC+(2.64)で首位を獲得し、OpenAI(C、2.10)、Google DeepMind(C-、1.76)がそれに続きました。中位層にはx.AIとMeta(共にD)が含まれ、中国企業であるZhipu AIとDeepSeekは共に落第点(F)となっています。特筆すべきは、C+よりも高い評価を得た企業が一つもなかったことであり、これは業界のリーダーでさえ、適切な安全基準に達していないことを示唆しています。
各ドメインにおける企業の評価は以下の通りです。
4.1 Key Findings (主要な発見事項)
主要な発見事項は、例えば、OpenAIが内部告発ポリシーを公開した唯一の企業であること、Anthropicが人間参加型のバイオリスク試験を実施した唯一の企業であること、そしてどの企業も存在リスクの安全性計画でDを超えられなかったことなどが強調されています。また、中国企業(Zhipu AIとDeepSeek)が総合的に低い評価を受けた理由として、レポートの評価基準が欧米の企業文化で重視される自己統治や情報共有の規範に強く影響されていることが再確認されています。
4.2 Improvement opportunities by company (企業ごとの改善機会)
レポートでは、各企業が将来のスコアを向上させるための具体的な改善機会も提案されています。例えば、Anthropicには「OpenAIの透明性基準に合わせるために、完全な内部告発ポリシーを公開すること」が推奨されています。OpenAIには「失われた安全チームの能力を再構築し、OpenAIの本来の使命へのコミットメントを再確認すること」が求められています。Google DeepMindには、「安全ガードレールなしのモデル評価結果を公開し、モデルの真の能力に近づけること」や「DeepMind安全チームとGoogleのポリシーチーム間の連携を改善すること」が挙げられています。
他にも、xAI、Meta、Zhipu AI、DeepSeekにもそれぞれ具体的な改善点が挙げられています。そして、全ての企業に対して共通して、「彼らが構築しようとしているAGI/ASI(人工超知能)をどのように制御するつもりなのかについて、たとえ不完全であっても最初の具体的な計画を公開すること」が求められています。
4.3 Domain-level findings (ドメインごとの調査結果)
- Risk Assessment (リスク評価)
このドメインは、企業の現在のフラッグシップモデルにおけるリスク識別と評価プロセスの厳密さと包括性を評価しています。焦点は、公言されたコミットメントではなく、実際に実施された評価に置かれています。
Anthropic、Google DeepMind、OpenAIの3社のみが、大規模なリスク(例:サイバー攻撃、バイオテロ)に対するモデルの危険な能力を評価する意味のある努力を示しました。特にAnthropicは、人間参加型のバイオテロリスク試験を実施した唯一の企業として評価されています。
しかし、たとえリーダー企業であっても、そのアプローチは十分厳密ではないと評価されています。ある専門家は、評価方法論の透明性が欠けていると批判し、「特定の評価や実験手順がリスクにどのように関連しているか、その方法論や推論が通常欠如している」と述べています。
また、どの企業も内部安全評価の独立した検証や評価を依頼していないことにも懸念が表明されました。これは、報告された証拠を信頼ベースで受け入れる必要があることを意味します。

- Current Harms (現在の害悪)
このドメインでは、AIモデルが現在発生させている害をどの程度効果的に軽減しているかを評価しています。特に、安全性ベンチマークの性能、敵対的攻撃に対する堅牢性、AI生成コンテンツの透かし(ウォーターマーキング)、ユーザーデータの扱いなどに焦点を当てています。
安全性ベンチマークの性能には大きなばらつきがあり、DeepSeekは敵対的テストで特に高い失敗率を示しました。
Meta、ZhipuAI、DeepSeekは、モデルのウェイト(AIモデルを構成するパラメータの集合)を完全に公開しているため、悪意のあるアクターが安全保護機能を微調整で除去できるという点で、さらなるリスクを増幅させていると批判されました。
ほとんどの企業でウォーターマーキングシステムが未発達であることが判明しましたが、Google DeepMindのSynthIDは最も先進的な実装として際立っていました。
プライバシーに関しては、Anthropicがデフォルトでユーザーインタラクションデータを使用しない唯一の企業として注目されました。

- Safety Frameworks (安全フレームワーク)
このドメインは、フロンティアAIの開発と展開に関する企業の公開安全フレームワークをリスク管理の観点から評価しています。この包括的な分析は、非営利研究機関であるSaferAIによって実施されました。
ZhipuAIとDeepSeekは、比較可能な安全フレームワークをそもそも公開していないためFと評価されました。ZhipuAIはソウルで開催されたAIサミットで公開を約束していたにもかかわらずです。
既存のフレームワークを持つ企業では、Anthropicのリスク識別と軽減アプローチ、OpenAIの評価結果公開へのコミットメント、Google DeepMindのアラート閾値、Metaの継続的な監視と脅威モデリングの規定などが強みとして挙げられました。しかし、最大の問題は、これらのフレームワークが対象とするリスクの範囲が非常に限定的であることでした。
外部監視メカニズムの欠如が、現在のフレームワークの根本的な弱点として浮上しており、OpenAIとAnthropicは外部ステークホルダーを含める初期の努力が注目されました。どのフレームワークも「条件付きの一時停止」に関する具体的な内容を十分に定義しておらず、ソウル合意に署名した企業も、具体的な、外部から検証可能な一時停止のトリガー閾値や信頼できる強制メカニズムを明示していません。

- Existential Safety (実存的安全性)
このドメインは、人間を超える能力を持つ可能性のある将来のAIシステムによる極端なリスク(存在リスク、壊滅的なリスク)を管理するための企業の準備状況を調査しています。これには、アラインメント(AIを人間の価値観に合わせる研究)と制御に関する戦略や研究が含まれます。
ある評価者は、「このカテゴリは非常に憂慮すべきである」と述べました。7社すべてが10年以内にAGIを構築しようと競っているにもかかわらず、「どの企業も、自分たちがすぐに実現すると言って非常に積極的に取り組んでいることが実際に起こった場合、どうすべきかについて、首尾一貫した実行可能な計画を全く持っていない」と指摘されています。5社がF評価を受け、Dよりも良い評価の企業はありませんでした。
アラインメントや制御戦略に関する定量的な保証はほとんどなく、どの企業も開発しようとしている変革的な技術について、正式な安全性証明や確率的なリスク範囲を提供していません。
Anthropicは「スキミング(scheming)/アラインメント偽装」に関する世界最先端の研究で評価されましたが、その戦略が、まだ初期段階にある機械的解釈可能性(AIモデルの内部動作を人間が理解できるようにする技術)に過度に依存していると批判されました。Google DeepMindの安全に関する文書は「よく考えられており、監視への真剣なコミットメントがある」と評価されましたが、リスクが許容できるほど低いと評価するための確固たる根拠は提供されていないと指摘されました。
OpenAIの安全性文化の劣化が特に懸念され、評価がFに下がりました。ある評価者は、「OpenAIの安全性への焦点はこの1年間で薄れ、この分野の研究者のほとんどを失った」と述べています。安全チームの離職率の高さや、スーパーアラインメント(超知能AIのアラインメント)に関するコミットメントの不履行は、優先順位の懸念すべき変化を示していると受け止められました。

- Governance & Accountability (ガバナンスと説明責任)
このドメインは、各企業のガバナンス構造と日常業務が、AIシステムが実世界に与える影響に対する意味のある説明責任を優先しているかを監査しています。指標は、内部告発システム、法的構造、AI規制に関するアドボカシー(政策提言)努力などを調査しています。
Anthropicは、Public Benefit Corporation(PBC:公共利益法人)としての地位と、短期的な利益インセンティブを減らし、長期的な安全性の考慮を強化するために設計されたLong-Term Benefit Trust(長期利益信託)によって、レビューアから注目されました。OpenAIの元の非営利構造からの移行計画は、安全重視の使命への整合性を弱めるものと評価されました。
AI規制に関するアドボカシー努力は、評価において重要な要素として重視されました。Anthropicは、カリフォルニア州のSB 1047法案への部分的な支持や、州レベルの規制に対する連邦政府の優越性を支持しない姿勢が評価されました。x.AIのCEOは、SB 1047を公に支持したことが認められました。対照的に、OpenAI、Google DeepMind、Metaは、EU AI Act、SB 1047、RAISE Actを含む主要なAI安全規制に反対するロビー活動を行ったため、評価が引き下げられました。
強固な公開内部告発ポリシーは、業界全体のギャップであることが指摘されました。OpenAIが唯一、完全な内部告発ポリシーを公開している企業であると指摘されましたが、それはメディア報道によってポリシーの非常に制限的な不名誉禁止条項が明らかになった後でした。Google DeepMindとMetaは、懸念を表明した従業員に対する過去の報復行為が、安全文化に悪影響を与える可能性があるとして指摘されました。

- Information Sharing (情報共有)
このセクションでは、企業が製品、リスク、リスク管理の実践に関する情報をどの程度オープンに共有しているかを評価しています。指標には、自主的な協力、技術仕様の透明性、リスク/インシデントのコミュニケーションが含まれます。
前年と比較して、OpenAIはAI安全性指標のアンケートへの参加で際立っていました。同社の詳細なモデル仕様と、悪意のある悪用の特定事例の定期的な開示は、レビューアによって肯定的に評価されました。
リスクコミュニケーションは企業間で大きく異なりました。Anthropicは、重要なリスクについて政策立案者や一般市民に積極的に情報提供する姿勢が評価された一方で、Metaは、そのリーダーシップが極端なリスクを公に軽視しているため、スコアが下がりました。
システムプロンプトの秘密主義は、プロプライエタリモデル(独自の技術で開発されたモデル)では依然として一般的であり、AnthropicとxAIのみが、モデルを操るテキスト(システムプロンプト)を公開したことで評価されました。
インシデント報告フレームワークはほとんど存在せず、7社中どの企業も政府機関に重要なインシデントを通知するための具体的で公開されたプロセスを提供していません。この欠如は、共同学習を妨げ、新たな脅威に対する政府の対応を遅らせる可能性があると指摘されています。
xAI、ZhipuAI、OpenAIは、AI安全性指標のアンケートに回答したことで評価されました。G7広島AIプロセス報告への自主的な協力に関しては、MetaとxAIが、G7加盟国に拠点を置く企業でありながら、リスク管理システムに関する文書を提出しなかった唯一の企業として注目されました。

5 Conclusions (結論)
2025年版FLI AI安全性指標は、AI業界における「信頼の危機」を明らかにしています。AIリスクに対する国際的な合意が高まり、AIの能力が急速に進歩しているという証拠が増えているにもかかわらず、専門家は技術的な野心と安全性準備の間のギャップが拡大していると警告しています。総合評価でC+を超える企業が一つもなかったことから、レビューアは、業界の自己規制的なアプローチがリスクの大きさに十分対応できるか疑問を呈しています。
レポートの調査結果は、憂慮すべき状況を示しています。企業は人工汎用知能(AGI)の構築に向けて競争しており、10年以内に超人的な性能を達成すると予測しています。しかし、あるレビューアが指摘するように、「どの企業も、そのようなシステムを制御するための、首尾一貫した、実行可能な計画を全く持っていない」のです。一部の企業は、激しい競争圧力にもかかわらず、危険な能力に関する意味のある評価に投資していましたが、レビューアは業界全体にわたる明らかな方法論的欠陥を依然として特定しています。ある専門家は、次のように警告しています。
「危険な能力が重大な被害を防ぐのに間に合うように検出されているという自信は、非常に低いものです。外部の第三者評価への全体的な投資が最小限であることは、私の信頼をさらに低下させています。」
Future of Life Instituteは、定期的なインデックスの更新を通じて、これらの重要な進展を追跡し続けることを約束しています。専門家レビューパネルおよび提携組織と協力して、評価を洗練し、懸念すべきギャップと新たなベストプラクティスの両方を強調し続けるとのことです。
Appendix
上記の項目に関する詳細な内容です。評価結果のポイントに関しては、上記の記述と内容的に重複している部分があります。
1. Risk Assessment (リスク評価)
この領域では、企業が自社の主要なAIモデルに対して、どれだけ厳密かつ包括的にリスクを特定し、評価するプロセスを実施しているかを評価します。単なる「やります」という表明ではなく、実際に「やっているか」が重視されます。
指標の概要:
- Internal testing (内部テスト): 危険な能力(サイバー攻撃、自己増殖、情報操作など)の評価。
- Elicitation for Dangerous Capability Evaluations (危険な能力評価のための抽出): 危険な能力評価で使用される「引き出し戦略」(モデルから特定の能力を引き出す方法)の透明性。
- Human Uplift Trials (人間能力向上試験): AIがユーザーの現実世界での危害能力をどれだけ向上させるかを測る、人間を対象とした厳密な研究の実施。
- External testing (外部テスト): 第三者による安全性評価の独立したレビュー。
- Pre-Deployment External Safety Testing (展開前外部安全性テスト): モデルの一般公開前に、独立した第三者による安全評価へのアクセス提供。
- Bug Bounties for Model Vulnerabilities (モデルの脆弱性に対するバグ報奨金制度): AIモデルの挙動に特化した安全上の脆弱性を発見・開示するためのインセンティブプログラムの提供。
評価結果のポイント:
Anthropic、Google DeepMind、OpenAIの3社のみが、AIモデルが大規模なリスクをもたらす可能性を評価するための意味のある取り組みを示しました。特にAnthropicは、人間が参加する生物兵器リスクのトライアルを実施した唯一の企業として評価されています。
しかし、評価者からは、これらの先進企業ですら、評価の方法論や根拠が明確でないという批判がありました。つまり、「なぜこのテストを選んだのか」「どのようなリスクを対象としているのか」「結果をどう解釈すべきか」といった説明が不足しているということです。さらに、内部の安全性評価が独立した第三者によって検証されていないため、報告された証拠を信頼するしかないという懸念も示されています。ある専門家は、「危険な能力が重大な被害を防ぐのに間に合うように検出されているか、非常に低い信頼性しかない」と警鐘を鳴らしています。
2. Current Harms (現在の害悪)
この領域では、企業が開発したAIモデルが、現時点でどのような安全上の問題(害悪)をどれだけ効果的に軽減しているかを評価します。AIモデルの安全性ベンチマークの性能、敵対的攻撃に対する堅牢性、AI生成コンテンツのウォーターマーク(透かし)技術、ユーザーデータの取り扱いなどが焦点です。
指標の概要:
- Model Safety / Trustworthiness (モデルの安全性/信頼性):
- Stanford’s HELM Safety Benchmark (スタンフォード大学のHELM安全性ベンチマーク): 言語モデルが堅牢性、公平性、有害な挙動への耐性など、主要な安全性指標でどの程度の性能を発揮するかを評価。
- Stanford’s HELM AIR Benchmark (スタンフォード大学のHELM AIRベンチマーク): 新たな政府規制や企業ポリシーに合致するAIモデルの安全性とセキュリティを評価。
- TrustLLM Benchmark (TrustLLMベンチマーク): 真実性、安全性、公平性、堅牢性、プライバシー、機械倫理など、複数の側面からモデルの信頼性を評価。
- Robustness (堅牢性):
- Gray Swan Arena: UK AISI Agent Red-Teaming Challenge (グレイ・スワン・アリーナ:英国AI安全性研究所エージェント・レッドチームチャレンジ): AIエージェントが、その挙動を操作しようとする敵対的挑戦にどの程度耐えられるかをテスト。
- Cisco Security Risk Evaluation (シスコセキュリティリスク評価): AIシステムが自動化された「ジェイルブレイク攻撃」(安全システムを迂回して有害な出力を引き出す攻撃)に対してどれだけ耐性があるかを評価。
- Protecting Safeguards from Fine-tuning (ファインチューニングからの安全策の保護): ファインチューニング(既存のAIモデルを追加学習させること)によって、重要な安全メカニズムやフィルターが無効化されるのを防ぐための安全策が講じられているかを評価。
- Digital Responsibility (デジタル責任):
- Watermarking (ウォーターマーキング): AI生成コンテンツ(テキスト、画像)を識別するためのウォーターマーク技術が導入されているかを評価。
- User Privacy (ユーザープライバシー): AI企業がユーザーデータ(チャット履歴など)を、モデル改善のためにデフォルトで使用しているか、または明示的なオプトイン同意を必要としているか、プライベートでのモデル実行オプションを提供しているかを評価。
評価結果のポイント:
安全性ベンチマークの性能は企業によって大きく異なり、モデルは「ジェイルブレイク」(AIの安全ガードレールを回避して有害な出力を引き出すこと)や悪用に依然として脆弱です。特にDeepSeekは、敵対的テストにおいて非常に高い失敗率を示しました。Meta、ZhipuAI、DeepSeekは、安全保護機能のないモデルのウェイト(学習済みのAIモデルのパラメータ)を公開することで、悪意のあるアクターがファインチューニングを通じて安全保護機能を削除できるリスクを高めていると批判されています。
ウォーターマークシステムはほとんどの企業で未開発のままでしたが、Google DeepMindのSynthIDは最も進んだ実装であると評価されました。プライバシーに関しては、Anthropicがデフォルトでユーザーの対話データを使って学習しない唯一の企業として際立っています。
3. Safety Frameworks (安全フレームワーク)
この領域では、企業が公開している「フロンティアAI開発・展開のための安全フレームワーク」を、リスク管理の観点から評価します。この評価は、非営利研究機関であるSaferAIによって包括的に実施されました。
指標の概要:
- Risk Identification (リスク特定): 企業が包括的な方法(文献レビュー、レッドチーム演習、多様な脅威モデリング技術など)を用いてAIリスクを体系的に特定しているか評価。
- Risk Analysis and Evaluation (リスク分析と評価): 抽象的なリスク許容度を、特定の対応をトリガーする具体的で測定可能な閾値(キーリスク指標:KRI)に変換しているか評価。
- Risk Treatment (リスク対応): AIのライフサイクル全体を通じて、封じ込め、展開時の安全策、積極的な安全性保証といった包括的な軽減戦略を実施し、継続的な監視を行っているか評価。
- Risk Governance (リスクガバナンス): 企業が明確なリスクの責任体制、独立した監視、安全志向の文化を確立し、リスク管理のアプローチとインシデントの透明な開示を行っているか評価。
評価結果のポイント:
ZhipuAIとDeepSeekは、比較可能な安全フレームワークをそもそも公開していないため、「F」評価となりました。これは、ZhipuAIがソウルでの国際AIサミットで公開を約束していたにもかかわらずです。 他の企業はフレームワークを公開していますが、評価者からは、Anthropicのリスク特定と軽減のアプローチ、OpenAIの評価結果公開へのコミットメント、Google DeepMindのアラート閾値、Metaの継続的な監視と脅威モデリングの規定にそれぞれ特徴的な強みが見られました。しかし、最も大きな批判は、これらのフレームワークが対象としているリスクの範囲が非常に限られているという点でした。
外部からの監視メカニズムの欠如は、現在のフレームワークの根本的な弱点として浮上しています。OpenAIとAnthropicは外部のステークホルダーを巻き込む初期の努力が評価されましたが、全体として、どのフレームワークも「条件付きの一時停止」に関する具体的な定義が不十分であり、具体的なトリガー閾値や信頼できる強制メカニズムが明記されていませんでした。結論として、専門家たちは、これらの自主的なフレームワークの質は徐々に向上しているものの、高リスク状況でフレームワークが確実に実施・適用されるための重要なガバナンスメカニズムが欠けていると結論づけています。
4. Existential Safety (実存的安全性)
この領域では、将来のAIシステム(人間の能力に匹敵するか、それを超える可能性のあるシステム)から生じる極端なリスクを管理するための企業の準備状況を調査します。これには、アラインメント(AIを人間の意図や価値観に合わせること)と制御に関する戦略や研究が含まれます。
指標の概要:
- Existential Safety Strategy (実存的安全性戦略): AGI(汎用人工知能)を開発する企業が、壊滅的かつ実存的なAIリスクを軽減するための、信頼性があり詳細な戦略(アラインメント、制御、ガバナンス、計画など)を公開しているか評価。
- Internal Monitoring and Control Interventions (内部監視および制御介入): 企業が、内部での利用中にミスアラインメント(AIが意図しない目標を追求すること)によるリスクを検出・防止するための技術的制御とプロトコルを導入しているか評価。
- Technical AI Safety Research (技術的AI安全性研究): 企業が、解釈可能性(AIの判断過程を理解可能にすること)、スケーラブルな監視(大規模なAIシステムを効率的に監視すること)、危険な能力評価など、極端なリスク軽減に関連する研究を発表しているか追跡。
- Supporting External Safety Research (外部安全性研究の支援): 企業が、メンターシップ、資金提供、モデルへのアクセス、外部研究者との協力など、独立したAI安全性研究をどの程度支援しているか評価。
評価結果のポイント:
ある評価者はこのカテゴリーを「深く憂慮すべき」と評しています。7社すべてが10年以内にAGIの構築を目指しているにもかかわらず、「どの企業も、自分たちが間もなく実現しようとしていること、そして積極的に実現しようとしていることが現実に起きた場合にどうすべきか、首尾一貫した実行可能な計画をほとんど持っていない」と指摘されています。アラインメントや制御戦略に関する定量的な保証は事実上皆無であり、どの企業も開発しようとしている変革的技術に対する正式な安全性証明や確率的リスク限界を提示していません。
AnthropicとGoogle DeepMindは、この領域で最も高い「D」と「D-」の評価を受けました。Anthropicは、モデルのミスアラインメント(意図しない目的を追求するAIの挙動)の検出へのコミットメントを示す「欺瞞/アラインメント偽装」に関する世界最先端の研究が評価されています。しかし、Google DeepMindの安全に関する文書は「よく考えられている」ものの、リスクが許容可能なほど低いと評価するための確固たる根拠を提供するものではないと指摘されています。
OpenAIは、安全文化の悪化により「F」に評価が落ち込みました。ある評価者は、「OpenAIの安全性への注力は過去1年で低下し、この分野の研究者のほとんどを失った」と述べています。Superalignment(超知能AIのアラインメント)へのコミットメントを達成できなかったことも、優先順位の変化を示唆しています。xAIとZhipuAIのリーダーは壊滅的リスクへの認識を示しているものの、具体的な技術研究はほとんど公開されていません。
5. Governance & Accountability (ガバナンスと説明責任)
この領域では、各企業のガバナンス構造と日々の運営が、AIシステムの現実世界への影響に対する意味のある説明責任を優先しているかどうかを監査します。内部告発システム、法的構造、AI規制に関するアドボカシー(政策提言活動)などが指標となります。
指標の概要:
- Lobbying on AI Safety Regulations (AI安全性規制に関するロビー活動): 企業がAI安全性に関連する法律や政策に影響を与えるロビー活動や広報活動にどのように関与しているかを追跡。
- Company Structure & Mandate (企業構造と任務): 企業の基本的な法的構造、所有モデル、受託者義務が、高リスク状況で短期的な経済的圧力よりも安全性を優先できる仕組みになっているか評価。
- Whistleblowing Policy Transparency (ホイッスルブロウイングポリシーの透明性): AI開発者が内部告発(ホイッスルブロウイング)ポリシーとシステムを外部にどれだけ完全に、そして分かりやすく開示しているか評価。
- Whistleblowing Policy Quality Analysis (ホイッスルブロウイングポリシーの品質分析): 企業が公開している内部告発ポリシーの品質を、国際的なベストプラクティスとAI固有の安全要件に照らして評価。
- Reporting Culture & Whistleblowing Track Record (報告文化とホイッスルブロウイングの実績): AI開発者が、従業員が報復を恐れることなく安全に関する懸念を表明できる環境を育成しているか、またそれらの懸念が適切に対処されるという信頼が確保されているか評価。
評価結果のポイント:
Anthropicは、「公共利益法人(Public Benefit Corporation: PBC)」としての地位と、短期的な利益動機を減らし、長期的な安全配慮を強化するために設計された「長期利益信託(Long-Term Benefit Trust)」が評価され、際立っていました。OpenAIは、従来の非営利構造からの移行計画が、安全性重視の使命との整合性を弱めるものとして懸念されました。xAIもPBCとして登録されていますが、その構造が具体的な安全ガバナンスにどうつながるかはまだ示されていません。
AI規制に関するロビー活動については、Anthropic(SB 1047への部分的賛同と州レベル規制の連邦優位への反対)とxAI(SB 1047への支持)が、より強力な規制を支持する姿勢で評価されました。対照的に、OpenAI、Google DeepMind、Metaは、EU AI法、SB 1047、RAISE法といった主要なAI安全性規制に反対するロビー活動を行ったため、評価を下げました。
ホイッスルブロウイングポリシーの透明性は、業界全体の弱点として認識されています。評価対象企業の中で、ポリシー全体を公開したのはOpenAIのみでした。これは、メディアの報道で、そのポリシーが持つ制限的な「不名誉条項(非難禁止条項)」が明らかになった後のことでした。Google DeepMindとMetaは、懸念を表明した従業員に対する報復事例があったとして、指摘を受けています。
6. Information Sharing (情報共有)
このセクションでは、企業が自社の製品、リスク、リスク管理の実践について、どれだけオープンに情報を共有しているかを測定します。自主的な協力、技術仕様の透明性、リスクやインシデントの連絡などが指標となります。
指標の概要:
- Technical Specifications (技術仕様):
- System Prompt Transparency (システムプロンプトの透明性): 企業が、最も高性能なAIモデルで使用されているシステムプロンプト(AIに与えられる指示文)を公開しているか。
- Behavior Specification Transparency (振る舞い仕様の透明性): 開発者が、モデルの意図された振る舞い、価値観、意思決定ロジックを詳細に説明した文書を公開しているか。
- Voluntary Cooperation (自主的な協力):
- G7 Hiroshima AI Process Reporting (G7広島AIプロセス報告): 企業がG7広島AIプロセス(HAIP)に詳細な安全性・ガバナンスの開示を提出したか。
- FLI AI Safety Index Survey Engagement (FLI AI安全性インデックス調査への参加): 企業がFLIの詳細な安全性調査に自主的に回答し、追加情報を提供したか。
- Risks & Incidents (リスクとインシデント):
- Serious Incident Reporting & Government Notifications (重大なインシデント報告と政府への通知): 企業が、重大なAI関連インシデントを政府機関や同業他社に報告する公的なコミットメント、フレームワーク、実績があるか。
- Extreme-Risk Transparency & Engagement (極端なリスクの透明性と関与): 企業とそのリーダーが、AIの壊滅的な危害の可能性を公的に認識し、そのようなリスクに関する証拠に基づいた分析を外部のステークホルダーに積極的に発信しているか。
評価結果のポイント:
OpenAIは、AI Safety Index調査への積極的な参加、詳細なモデル仕様の提供、悪意ある誤用事例の定期的な開示が評価されました。リスクコミュニケーションの姿勢は企業間で大きく異なり、Anthropicは政策立案者や一般市民に積極的にリスクを伝えているのに対し、Metaのリーダーシップは極端なリスクを軽視する傾向が見られました。
プロプライエタリモデル(特定の企業が所有・管理するモデル)のシステムプロンプトは依然として非公開が一般的ですが、AnthropicとxAIは公開しているとして評価されました。インシデント報告の枠組みは全体的に不足しており、どの企業も政府に重大なインシデントを通知する具体的な公的プロセスを持っていませんでした。また、G7諸国に拠点を置く企業のうち、MetaとxAIはG7広島AIプロセスにリスク管理システムの文書を提出していませんでした。
まとめ
「FLI AI Safety Index Report Summer 2025」は、AI技術が急速に進化する中で、その安全性確保がいかに喫緊の課題であるかを私たちに突きつけています。特に、AGIのような人間を超えるAIの出現が予測されるにもかかわらず、その制御やリスク管理に対する具体的な計画が多くの企業で不足しているという点は、深く考えるべき問題だと言えます。
レポートは、企業が自主的な安全性コミットメントに頼るだけでなく、より強固な規制や独立した検証の必要性を強く示唆しています。企業や政策立案者に安全性を重視するよう働きかけることが、より良い未来を築くために重要になると考えられます。