
はじめに
聴覚障害者や言語学習者にとって、複数人が参加する会話をリアルタイムで理解することは大きな挑戦です。既存の音声認識アプリは誰が話しているかを区別できず、会話の流れを把握することが困難でした。
本稿では、Googleが開発した新たな音源定位技術「SpeechCompass」について、Google Researchの「Making group conversations more accessible with sound localization」という記事をもとに詳しく解説します。この技術は、複数マイクロフォンを活用した音源定位により、グループ会話での話者識別と方向表示を実現し、モバイル端末でのアクセシビリティを大幅に向上させるソリューションです。
引用元記事
- タイトル:Making group conversations more accessible with sound localization
- 著者:Samuel Yang(Google Research研究員)、Sagar Savla(Google DeepMindプロダクトマネージャー)
- 発行元:Google Research Blog
- 発行日:2025年7月2日
- URL:https://research.google/blog/making-group-conversations-more-accessible-with-sound-localization/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- SpeechCompassは、複数マイクロフォンを用いた音源定位技術により、モバイル端末での音声認識に話者分離機能と方向表示機能を追加する革新的なシステムである。
- 従来のモバイル音声認識アプリの最大の問題点は、複数人の発話を区別できず、全ての音声を連続したテキストとして表示することにあった。これにより、ユーザーは会話の内容を理解しながら話者を特定し、さらに会話に参加するという認知的負荷の三重苦を強いられていた。
- SpeechCompassの技術的核心は、到達時間差(TDOA)アルゴリズムと位相変換付き一般化相互相関(GCC-PHAT)を組み合わせた音源定位手法にある。この手法により、機械学習モデルを使用せずにリアルタイムでの話者分離を実現し、計算コストの削減、レイテンシの短縮、プライバシーの保護という三つの重要な利点を提供する。
- システムは2つの実装形態を持つ:4つのマイクロフォンを搭載したスマートフォンケース型プロトタイプ(360度音源定位対応)と、既存のデュアルマイクスマートフォン用ソフトウェア実装(180度音源定位対応)である。

詳細解説
従来技術の限界と課題
モバイル端末の音声認識技術は、Live Transcribeなどのアプリケーションを通じて、聴覚・言語アクセシビリティ、言語翻訳、議事録作成などの分野で重要な役割を果たしてきました。しかし、複数人が参加する会話においては、話者の識別ができないという根本的な問題を抱えていました。
従来のモバイル自動音声認識(ASR)アプリは、全ての発話を時系列順に連結して表示するため、ユーザーは以下の課題に直面していました:
- 認知的負荷の増大:文字起こし内容の理解、話者の特定、会話への参加という三つの作業を同時に行う必要
- 会話の流れの把握困難:誰がいつ発言したかが不明確
- 既存の解決策の制約:音声・映像分離技術では話者がカメラに映る必要があり、話者埋め込み手法では個人の声紋データが必要
SpeechCompassのアプローチ
音源定位技術の基礎原理
SpeechCompassの中核技術である音源定位は、音響工学の基本原理に基づいています。音は比較的低い周波数特性を持つため、室内環境では壁や天井で反射し、残響を生じます。この現象により、特に音声の正確な定位は困難とされてきました。
SpeechCompassは、到達時間差(Time Difference of Arrival: TDOA)アルゴリズムを採用してこの課題を解決しています。音信号は各マイクロフォンに僅かに異なる時間で到達するため、アルゴリズムはマイクロフォンペア間のTDOAを相互相関により推定し、音の到来角度を予測します。
GCC-PHATアルゴリズムの活用
具体的には、位相変換付き一般化相互相関(Generalized Cross Correlation with Phase Transform: GCC-PHAT)を使用しています。この手法の利点は以下の通りです:
- ノイズ耐性の向上:周囲雑音の影響を軽減
- 計算速度の向上:リアルタイム処理に適した高速演算
- 統計的推定の併用:カーネル密度推定などを組み合わせた精度向上
マイクロフォン配置と定位範囲
2つの全方向性マイクロフォンを使用する場合、必然的に前後混同問題が発生します。これは、配列の前方または後方からの信号がマイクロフォンアレイに対して同一に見える現象で、結果として180度の定位範囲に制限されます。この問題は3つ以上のマイクロフォンを使用することで解決され、360度の音源定位が可能になります。
システム実装の詳細
ハードウェア実装:スマートフォンケース型プロトタイプ
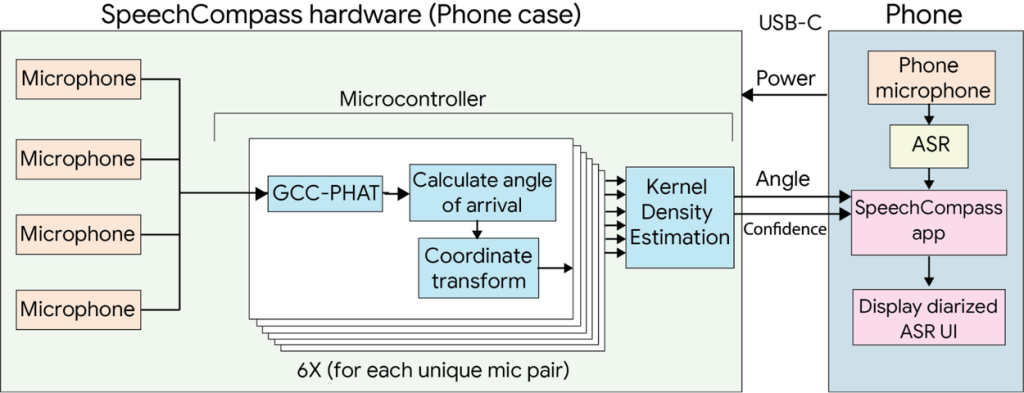
4つのマイクロフォンを搭載したスマートフォンケース型プロトタイプは、以下の特徴を持ちます:
- 360度音源定位対応:全方向からの音声を検出・分析
- 低消費電力マイクロコントローラー:STM32を使用したメイン基板
- フレキシブルPCBマイクロフォンマウント:最適な配置を実現
- USB接続:Androidアプリケーションとのデータ通信
ソフトウェア実装:既存デバイス対応
Pixelスマートフォンなどの2つ以上のマイクロフォンを搭載する既存デバイス向けのソフトウェア実装では、180度の音源定位を提供します。この実装により、新しいハードウェアを購入することなく、既存のデバイスでSpeechCompass機能を利用できます。
ユーザーインターフェースの革新
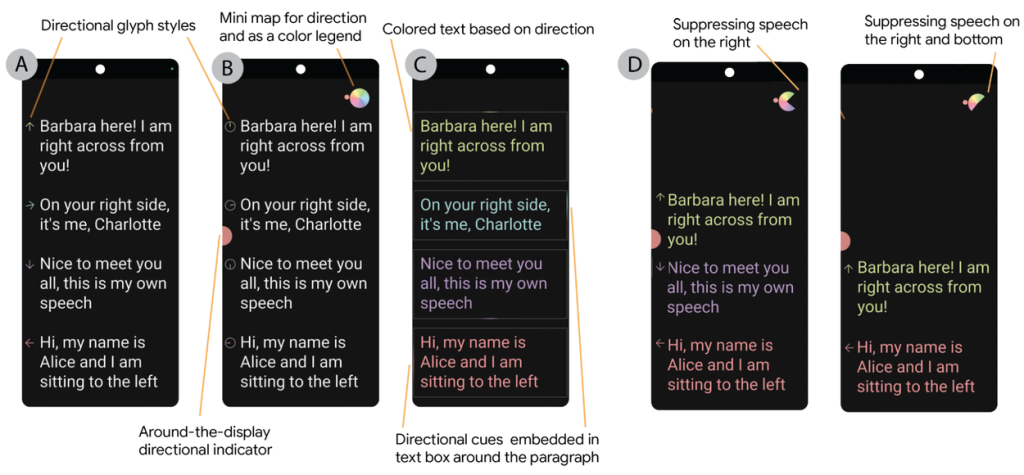
SpeechCompassは、音源定位データを視覚的に表現するための多様な可視化スタイルを提供します:
主要な可視化機能
- 色分けテキスト:話者ごとに異なる色でテキストを表示
- 方向性グリフ:矢印、円形ダイアル、色付きボックスハイライトによる話者位置の表示
- ミニマップ:レーダーのような小型ディスプレイで現在の話者位置を表示
- エッジインジケーター:画面端部の視覚的手がかりによる話者方向の表示
- 不要音声抑制機能:特定方向からの音声を除外(自分の発話や無関係な会話の除去)
特に不要音声抑制機能は、プライバシー保護の観点からも重要で、ユーザーが画面の特定領域をタップすることで、その方向からの音声を文字起こしから除外できます。
技術評価と性能分析
音源定位精度の評価
SpeechCompassソフトウェアの評価では、スマートフォンケースを回転プラットフォームに設置し、定位置のスピーカーから音声またはノイズを再生する方法を採用しました。プラットフォームを10度刻みで回転させ、各角度での到来角度を測定した結果、以下の性能が確認されました:
- 平均誤差:11°-22°(通常の会話音量60-65dBにおいて)
- 人間の音源定位能力との比較:人間が後方からの音を聞いた場合の答えは通常20度の誤差を含むため、SpeechCompassの精度は人間の定位能力とほぼ同等
- 材質・環境耐性:異なる材質や周囲雑音条件下でも安定した性能を維持
話者分離性能の評価
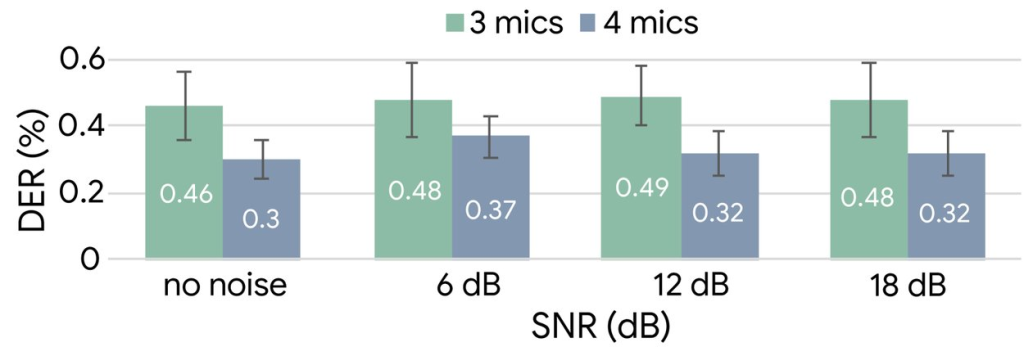
話者分離の評価には、話者分離誤差率(Diarization Error Rate: DER)という標準指標を使用しました。この指標は、インターフェースでの色分け話者分離の正確性に対応します:
- 4マイクロフォン構成:3マイクロフォン構成を一貫して上回る性能
- 相対的DER改善:異なる信号対雑音比(SNR)条件下で23%-35%の改善を実現
ユーザー調査と実用性評価
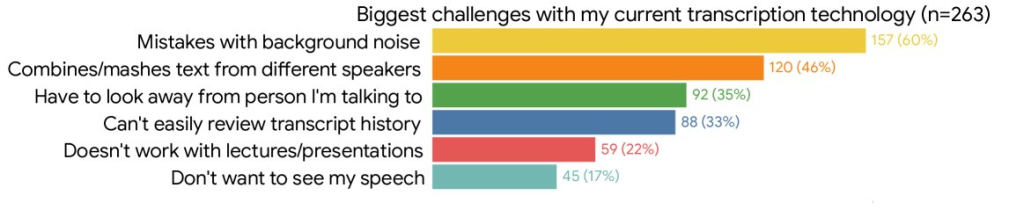
大規模ユーザー調査
現在のモバイル字幕技術の限界を理解するため、音声字幕技術の頻繁なユーザー263名を対象としたオンライン調査を実施しました。結果は、現在のソリューションが話者の区別ができないという重大な制約により、グループ会話での使用が困難であることを明確に示しました。
プロトタイプ実証実験
モバイル音声認識の頻繁なユーザー8名に対してプロトタイプのデモンストレーションを実施し、フィードバックを収集しました:
- 最も好まれた可視化手法:色分けテキストと方向矢印
- 方向ガイダンスの価値:全参加者がグループ会話での方向ガイダンスの価値に同意
- 実用性の確認:研究者間の会話を用いた話者分離と可視化の実演
従来手法に対する優位性
SpeechCompassのマルチマイクロフォンアプローチは、機械学習ベースの単一音源話者分離手法と比較して、以下の明確な優位性を提供します:
計算・メモリコストの削減
- モデル不要:機械学習モデルや重みパラメータが不要
- 小型マイクロコントローラー対応:限られたメモリと計算能力でも動作可能
レイテンシの短縮
- リアルタイム処理:話者埋め込み抽出に必要な十分な情報収集・クラスタリング処理が不要
- 即座の応答:遅延を引き起こす可能性のある処理ステップを排除
プライバシー保護の強化
- 個人識別情報不要:話者埋め込み(個人の声の固有アイデンティティ)やビデオデータが不要
- 物理的分離の仮定:異なる話者が物理的に別々の場所にいるという前提のみ
言語非依存動作
- 音響波形解析:コンテンツに対する事前仮定が不要
- 音声以外の音にも対応:言語や音声の種類を問わない汎用性
即座の再構成
- 動的適応:スマートフォンを移動させるだけで即座にシステムを再構成可能
まとめ
SpeechCompassは、音源定位技術を活用したモバイルアクセシビリティの革新として、グループ会話における話者識別という長年の課題に対する実用的なソリューションを提供します。機械学習に依存しない効率的なアプローチにより、計算コストの削減、プライバシーの保護、リアルタイム処理を同時に実現している点が特に注目されます。
技術的な観点から見ると、TDOA/GCC-PHATアルゴリズムの巧妙な活用とマルチマイクロフォン配置の最適化により、人間の音源定位能力に匹敵する精度を達成しています。また、多様な可視化オプションと不要音声抑制機能により、ユーザビリティとプライバシー保護の両面で優れた設計となっています。
今後の展開としては、スマートグラスやスマートウォッチなどのウェアラブルデバイスとの統合、機械学習によるノイズ耐性の向上、長期的な採用行動研究などが予定されており、アクセシビリティ技術の更なる発展が期待されます。教室での授業、ビジネス会議、社交の場面など、多様な実用場面での活用可能性は極めて高く、聴覚障害者や言語学習者のみならず、一般ユーザーにとっても価値のある技術として普及していくことが予想されます。








