はじめに
AIに「よくわからないので、教えてください」と質問させるのは、実は非常に難しい課題です。多くのAIは、曖昧な指示を受けると、不確かなまま推測で答えてしまう傾向があります。
この課題を解決するため、Google ResearchとGoogle DeepMindの研究者たちが発表した「Learning to clarify: Multi-turn conversations with Action-Based Contrastive Self-Training」という論文(および同名のブログ記事)で提案されている「ACT(Action-Based Contrastive Self-Training)」という手法について解説します。
引用元記事
- タイトル: Learning to clarify: Multi-turn conversations with Action-Based Contrastive Self-Training
- 著者: Maximillian Chen (Research Scientist, Google Research), Ruoxi Sun (Research Scientist, Google DeepMind)
- 発行元: Google Research
- 発行日: 2025年6月3日
- URL: https://research.google/blog/learning-to-clarify-multi-turn-conversations-with-action-based-contrastive-self-training/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 大規模言語モデル(LLM)は、ユーザーの指示が曖昧な場合、その意図を明確にするための質問をせず、誤った仮定に基づいて応答してしまうという課題がある。
- この問題を解決するため、少ない対話データからでも効率的にAIの対話方針を学習させることができる新しい手法「Action-Based Contrastive Self-Training (ACT)」が提案された。
- ACTは、対話における「明確化する」「回答する」といった行動(Action)に着目し、「良い行動」と「悪い行動」を対比させたデータ(対照データ)をまず作成する。
- 次に、AI自身がそのデータを用いて対話をシミュレーションし、その結果に基づいてさらに学習を進める自己訓練(Self-Training)の仕組みを取り入れている。
- 実験の結果、ACTは従来の学習手法(教師ありファインチューニングなど)と比較して、特に少ないデータ量でAIの性能を大幅に向上させることが確認された。これにより、AIが曖昧さを自ら認識し、ユーザーに適切な質問を投げかける能力が飛躍的に高まることが示された。
詳細解説
LLMが抱える対話の課題:「曖昧さ」との戦い
今日の対話型AI、特に大規模言語モデル(LLM)は非常に高性能になりましたが、人間同士の会話のような柔軟性にはまだ課題があります。その一つが「曖昧さの処理」です。
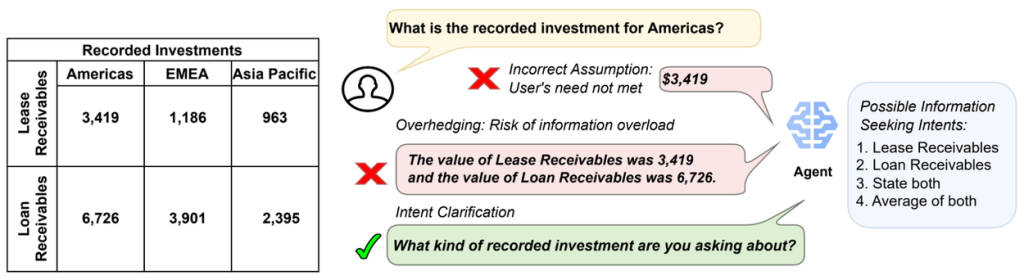
例えば、あなたがAIに「アメリカ大陸への投資額を教えて」と尋ねたとします。しかし、データには「リース債権」と「ローン債権」という2種類の投資記録があった場合、AIはどう応答すべきでしょうか?
- 悪い応答例1(誤った仮定): 「3,419ドルです」(リース債権の額だけを勝手に選んで回答)
- 悪い応答例2(過剰な情報): 「リース債権は3,419ドルで、ローン債権は6,726ドルです」(両方提示するが、ユーザーがどちらを知りたいかは無視)
これに対し、より良い応答は、ユーザーの意図を確認する明確化の質問をすることです。
- 良い応答例: 「どの種類の投資額についてお尋ねですか?」
現状の多くのLLMは、このような「良い応答」を生成するのが苦手です。なぜなら、その学習データに「質の高い明確化の質問」のサンプルが大量に含まれているわけではないからです。高品質な対話データを作成するには多大なコストがかかり、これがAIの対話能力向上のボトルネックとなっていました。
新提案「ACT」とは?— AIに「質問力」を授ける学習法
そこで提案されたのが、本稿の主役である「ACT(Action-Based Contrastive Self-Training)」です。これは、少ないデータでも効率的にAIの対話能力、特に「質問力」を高めるための新しい学習フレームワークです。ACTの名称は、その3つの主要な要素を表しています。
- Action-Based(行動ベース): AIの応答を、単なるテキスト生成ではなく、「明確化する」「回答する」といった目的を持った「行動(Action)」として捉えます。
- Contrastive(対照的): 「良い行動(例:明確化の質問)」と「悪い行動(例:不確かな回答)」を対比(Contrast)させることで、AIにその違いを学ばせます。
- Self-Training(自己訓練): AI自身が応答を生成し、その結果をシミュレーションしながら自分で自分を訓練していきます。
このACTは、大きく分けて2つのフェーズでAIを賢くしていきます。
ACTの学習プロセス:2つのフェーズ
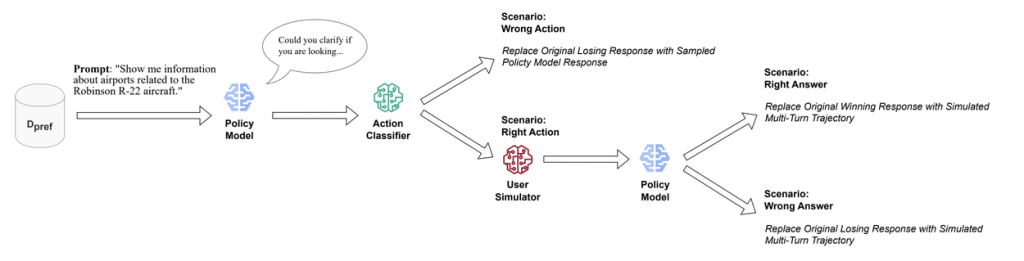
フェーズ1:お手本データの作成(アクションベースの対照データ生成)
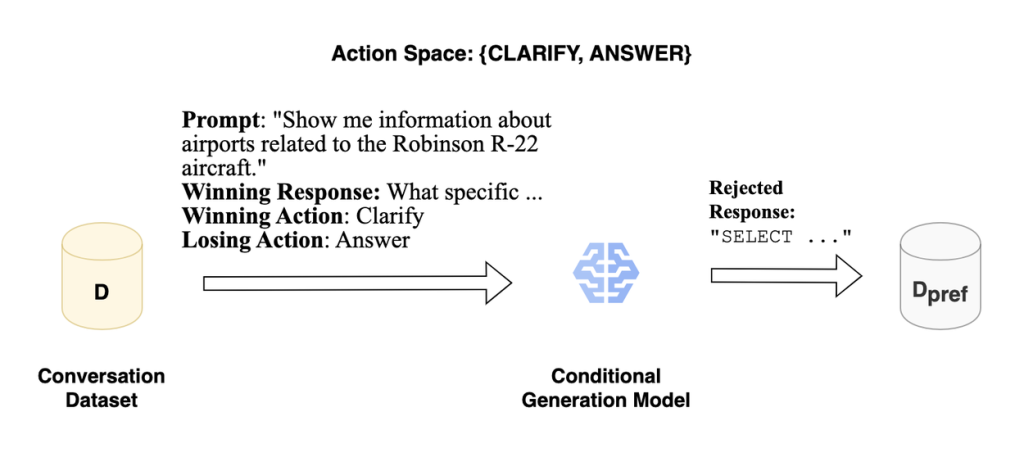
まず、学習の土台となる「お手本データ」を作成します。しかし、ただ正解データを集めるのではありません。ACTでは、「良い行動」と「悪い行動」をセットにした対照的なデータペアを作ります。
- 既存の対話データから、「良い行動」の例(論文では勝利する応答と表現)を抜き出します。例えば、人間がうまく明確化の質問をした場面などです。
- 次に、その「良い行動」とは逆の「悪い行動」(論文では拒否された応答)を、別のAIモデルを使って人工的に生成します。例えば、「明確化する」が良い行動なら、「(曖昧なまま)回答する」を悪い行動として生成します。
このプロセスにより、「プロンプト:X → 良い応答:Y / 悪い応答:Z」という形式のデータセットが出来上がります。これが、AIが行動の良し悪しを学ぶための最初の教科書となります。
フェーズ2:AI自身による実践と学習(対照的な自己訓練)
ここからがACTの真骨頂です。フェーズ1で作成した教科書をただ暗記させる(オフポリシー学習)のではなく、AI自身に実践練習をさせながら学習(オンポリシー学習)させます。
このフェーズは、以下のステップで構成されるループになっています。
- オンポリシーサンプリング: まず、学習中のAI自身に、あるプロンプトに対する応答を考えさせます。これは、AIが「今、自分ならこう動く」という応答を生成するステップであり、より実践的な学習を可能にします。
- 行動の評価: AIが生成した応答が、意図した「良い行動(例:明確化)」だったかどうかを分類器が判定します。
- マルチターン軌道シミュレーション: ここが非常に重要なポイントです。もしAIが良い行動(明確化の質問)を選択した場合、その質問に対してユーザーがどう答えるかをシミュレーターが模擬的に生成し、対話がどのように続くかをシミュレーションします。これにより、その場しのぎの応答ではなく、対話全体を成功に導くための長期的な視点をAIに学ばせることができます。
- お手本データの更新: シミュレーションの結果、最終的にユーザーの意図を満たすことができれば、その一連の対話(軌道)は「素晴らしい成功例」となります。この成功例を、フェーズ1で作成したデータセットの「勝利する応答」と置き換えます。逆に、シミュレーションが失敗に終われば、「敗北した応答」としてデータを更新します。
このように、AIは「自分で考えて行動 → 結果をシミュレーション → お手本を更新」というサイクルを繰り返すことで、自己対話のようにしてどんどん賢くなっていきます。これが「対照的な自己訓練」と呼ばれる仕組みの核心です。
驚くべき学習効果
研究チームは、このACTがいかに効果的であるかを複数の実験で証明しています。
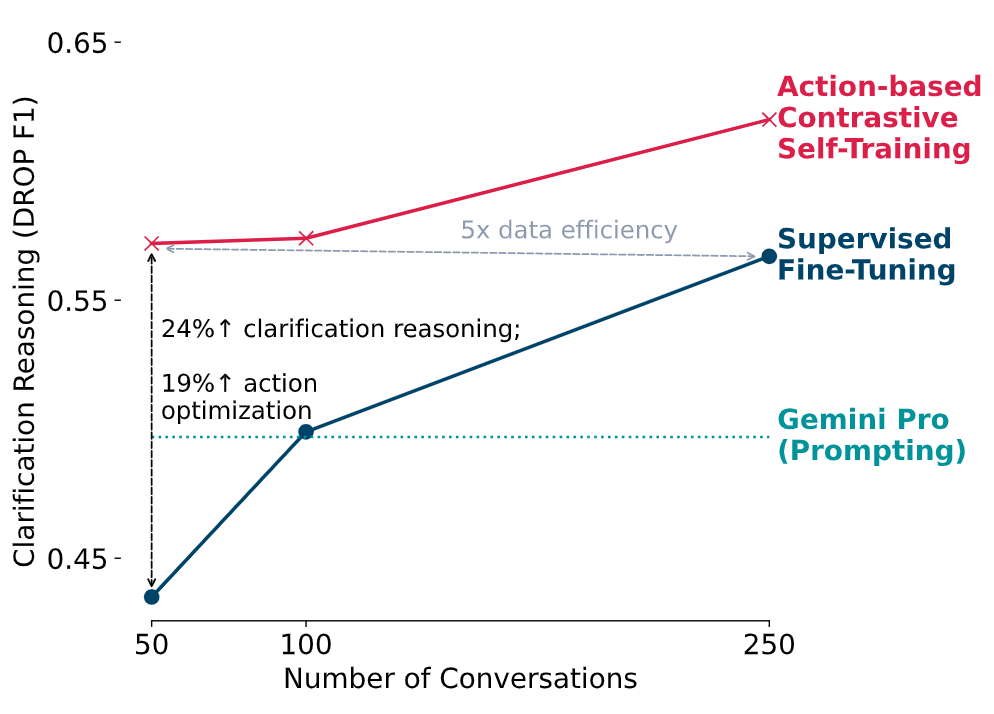
- 高いデータ効率: ある実験では、わずか50個の対話データを使ってACTで学習させただけで、AIが曖昧さを認識する能力(Macro F1スコア)が、従来の手法(SFT)と比較して19.1%も向上しました。これは、SFTで250個のデータを使った場合を上回る性能であり、約5倍のデータ効率を示唆しています。
- 最先端モデルへの匹敵: 驚くべきことに、限られたデータでACTを用いてチューニングされたモデルは、追加の学習なしで使われるGemini Proといった最先端モデルに匹敵、あるいはそれを上回る性能を達成しました。
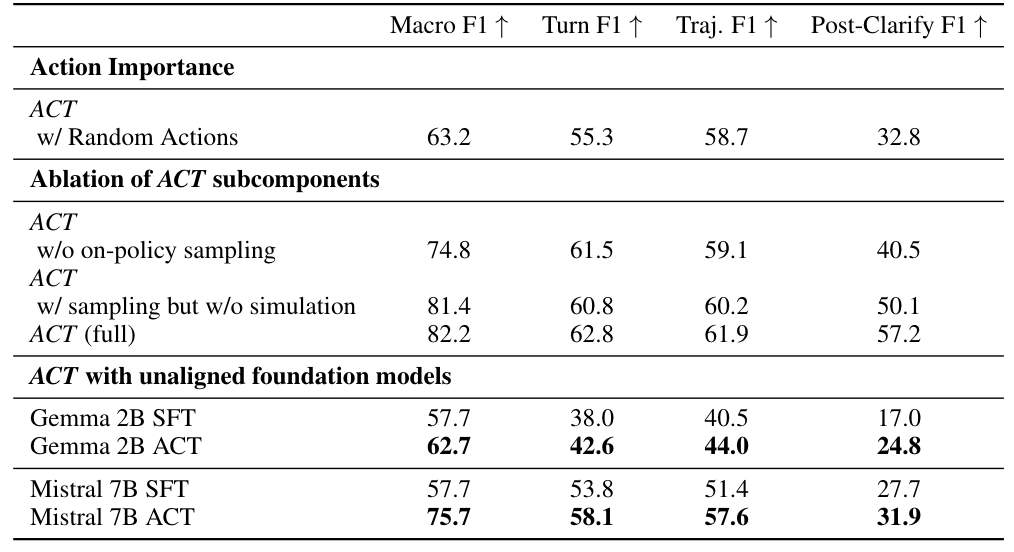
- 各要素の重要性: さらに詳細な分析(Ablation Study)により、「アクションベースの対照データ」「オンポリシーサンプリング」「軌道シミュレーション」のいずれもが性能向上に不可欠であることが実証されています。
まとめ
本稿では、Googleが提案した新しいAIの学習手法「Action-Based Contrastive Self-Training (ACT)」について解説しました。 ACTは、対話AIが長年抱えてきた「曖昧さ」という課題に対し、非常にエレガントで効果的な解決策を提示しています。単に正解を教え込むのではなく、対話を「行動」として捉え、AI自身にシミュレーションを通じて「良い行動とは何か」を考えさせるというアプローチは、今後のAI開発における重要なパラダイムとなるでしょう。