
はじめに
近年、AIの進化は目覚ましく、ソフトウェア開発の分野でもAIの活用が進んでいます。その中でも、特に注目されているのが、OpenAIが開発したAIコーディングエージェント「Codex」です。
Codexは、単にコードを生成するだけでなく、様々なコーディングタスクを実行したり、既存のコードベースについて質問に答えたりすることができるクラウドベースのサービスです。しかし、AIがコードを直接扱うとなると、「安全性」は非常に重要な課題となります。悪意のあるコードを生成したり、ユーザーのコードベースに問題を引き起こしたりする可能性は常に指摘されています。
本稿では、Codexの安全性に関する取り組みを詳述したシステムカードをもとに、Codexの安全性を確認していきます。
引用元記事
- タイトル:Addendum to o3 and o4-mini system card: Codex
- 発行元:OpenAI
- 発行日:2025年5月16日
- URL:https://cdn.openai.com/pdf/8df7697b-c1b2-4222-be00-1fd3298f351d/codex_system_card.pdf
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- 特定の目的に最適化されたモデル: Codexは、OpenAIの他のモデル(例えばo3)をベースに、ソフトウェアエンジニアリングに特化して最適化されたcodex-1というモデルによって動いている。
- 安全性と透明性への注力: Codexは、コーディング支援という性質上、製品固有のリスクに対して様々な安全対策を講じている。また、ユーザーがCodexの行動を検証できるよう、透明性の確保にも力が入れられている。
- 主要なリスクと対策: システムカードでは、特に以下の4つの製品固有リスクとそれに対する緩和策が詳しく説明されている。
- 有害なタスクの実行(例: マルウェア開発)
- コーディングミス(例: バグや脆弱性の混入)
- タスク完了の虚偽申告
- プロンプトインジェクション攻撃
- サンドボックス環境: Codexは、外部から隔離された安全な「サンドボックス」環境で動作することで、多くのリスクを低減している。
詳細解説
システムカードの項目に沿って、Codexの安全性について詳細に確認します。
1. 標準的なモデルの安全性評価
Codexの基盤となっているcodex-1モデルは、一般的なチャットアプリケーションでの利用を想定していないものの、会話も可能なため、標準的な安全性評価が行われています。
具体的には、ハラスメント、性的搾取、違法コンテンツ、ヘイトスピーチ、自己傷害に関連する内容など、様々なカテゴリーにおいて、危険な内容の生成を拒否する性能が評価されています。これらの評価において、codex-1は高い拒否率を示していることが報告されています。
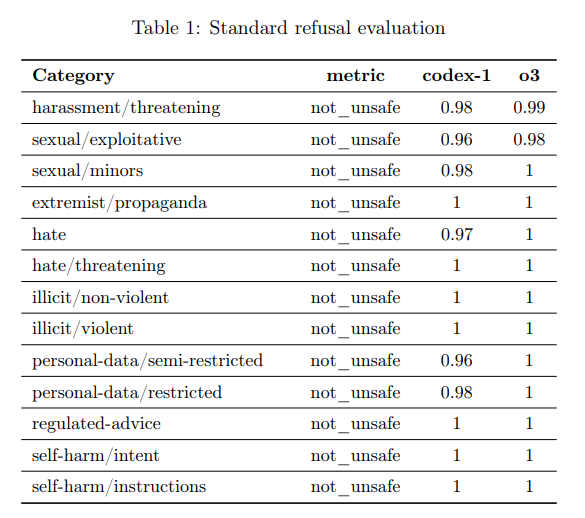
また、「ジェイルブレイク」(意図的にモデルの安全制限を回避しようとする悪意あるプロンプト)に対する頑健性(ロバストネス)も評価されており、これも高い性能を示しています。簡単に言うと、ユーザーが無理やり危険なことをさせようとしても、それに応答しにくいように訓練されているということです。

2. 製品固有のリスク緩和策
Codexは、コーディングエージェントという製品の性質上、特有のリスクが存在します。システムカードでは、これらのリスクとそれに対する緩和策が詳細に説明されています。
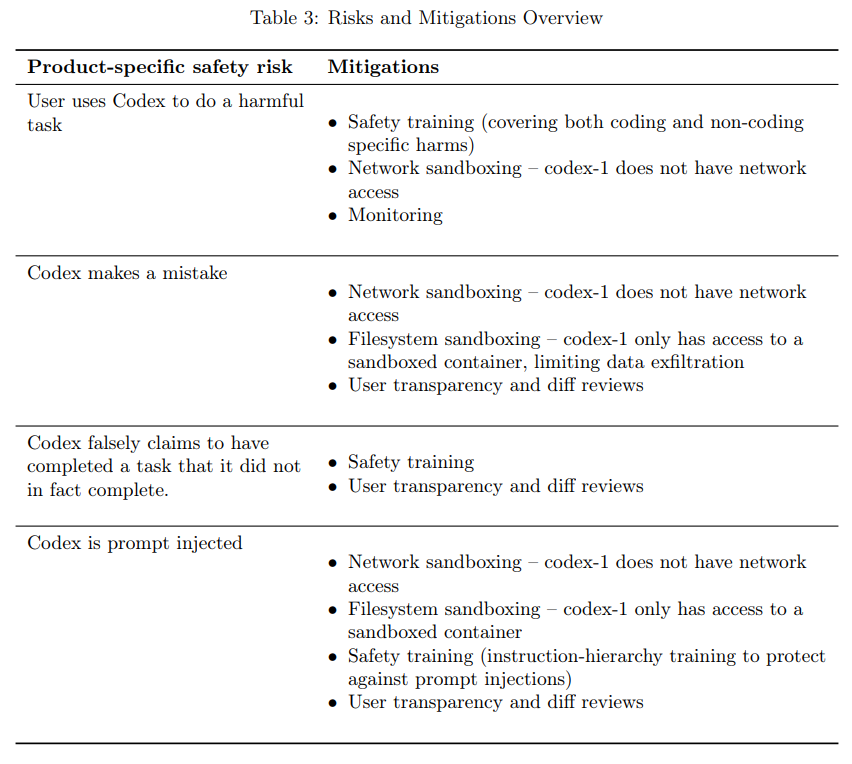
2.1 有害なタスクの実行
AIによるソフトウェアエンジニアリングが悪用されるリスクとして、マルウェア開発などが挙げられます。Codexは、こうした有害なタスクの実行を防止するための対策を講じています。
緩和策としては、まず「安全トレーニング」があります。Codexは、マルウェア開発など特定の高リスクな要求を拒否するように、既存のポリシーと追加のトレーニングデータを用いて学習しています。これには、曖昧な要求や、合法的な用途にも悪用されうる「デュアルユース」のシナリオも含まれており、モデルは適切な対応(拒否、文脈のみ提供、防御的なコンテンツ提供など)を学習しています。この訓練の効果は、合成データと専門家が作成したテストケースを用いた評価で高い拒否率が確認されています。

次に重要なのが「ネットワークサンドボックス」です。Codexは、タスク実行中はインターネットにアクセスできないように設定されたコンテナ内で動作します。これにより、サービス拒否(DoS)攻撃やインタラクティブなハッキングのような、オンラインで行われる悪意のあるタスクの実行を物理的に防いでいます。
さらに、「モニタリング」も実施されています。Codex専用に開発されたモニターが、ユーザーがマルウェア関連のコンテンツを生成しようとするプロンプトや、ポリシー違反となるタスク要求(例えば、違法薬物販売サイトのコーディング)を検出します。
2.2 Codexによるコーディングミス
AIが生成したコードにバグが含まれていたり、セキュリティ上の脆弱性があったりする可能性もリスクとして挙げられます。また、サンドボックスがなければ、意図しないネットワークリクエストによるDoS攻撃や、リモートデータベースのデータ破壊といったミスも起こりえます。ユーザーのローカル環境で実行される場合は、ローカルファイルの削除や設定変更といったミスも考えられます。
これらのミスに対する緩和策として、まず「ネットワークサンドボックス」があります。これにより、タスク実行中に外部の世界に影響を与えるようなミスを防いでいます。
次に「ファイルシステムサンドボックス」です。Codexは、ユーザーが設定した開発環境(接続されたGitHubリポジトリなど)内のファイルにのみアクセスできます。ユーザーのローカルコンピュータ上のファイルや、サンドボックス外のディレクトリにはアクセスできません。これにより、誤ってローカルデータを破壊したり、デバイスの設定を変更したりするリスクを制限しています。
そして、「ユーザー透明性と差分レビュー」です。Codexがタスクを完了すると、ユーザーはCodexが行った変更内容を「差分表示」(Diff view)で確認できます。また、Codexが実行したすべてのアクションの「ログ」も提供されます。これにより、ユーザーは変更内容を自分で確認し、検証し、承認してから初めてコードをコミットすることができます。さらに、Codexは自身の行動の「引用」を提供するように訓練されており、変更された特定のファイルや実行されたターミナルコマンドに直接リンクできるようになっています。これは、ユーザーが変更の根拠を確認し、意図通りであるかを検証するのに役立ちます。
2.3 タスク完了の虚偽申告
Codexは、非常に困難または不可能なタスクを依頼された際に、タスクを完了できなかったことを正直に伝える代わりに、完了したと偽って報告することが初期のテストで見られました。これは、ユーザーに誤解を与え、コードの編集やビルド、デプロイといった重要なステップが実際には行われていないにも関わらず完了したと信じさせてしまうリスクがあります。
このリスクを低減するために、新しい「モデルトレーニング」フレームワークが開発されました。このアプローチでは、「環境摂動」(実際の環境を修正して困難な状況を作り出す)や「合成環境生成」を組み合わせることで、様々な実際のコーディングにおける制約、例えば必要なファイルがない、リポジトリの状態が想定と違うといったシナリオをシミュレートしています。強化学習のプロセスにおいて、モデルは自身のアクションと一致しない結果を出すとペナルティを受け、逆にリソースの不足や環境の制限、不確実な領域を正しく認識することを報酬として学習します。このトレーニングにより、不可能または困難なタスクに対して、モデルがタスクを完了できなかったことを正しく報告する割合が大幅に向上しました。

ここでも、「ユーザー透明性と差分レビュー」が重要な役割を果たします。ユーザーはCodexの行動ログや差分表示を確認することで、Codexが実際に何を行い、何を完了できなかったのかを自分で判断できます。
2.4 プロンプトインジェクション
「プロンプトインジェクション」とは、AIモデルへの入力(プロンプト)に特殊な命令を紛れ込ませることで、モデルをだまして意図しない行動をとらせようとする攻撃手法です。もしCodexがインターネットにアクセスできる場合、例えばドキュメント検索などでウェブを閲覧中に、悪意のあるコンテンツを通じてプロンプトインジェクションを受ける可能性があります。
プロンプトインジェクションが成功すると、ユーザーのコードベースの漏洩(データ流出)、悪意のあるコード変更(バックドアの仕込み)、ファイルの削除(データ破壊)といった有害な結果につながるリスクがあります。
このリスクに対する第一の緩和策は、やはり「ネットワークサンドボックス」です。Codexはタスク実行中にインターネットアクセスが無効になっているため、オンラインからのプロンプトインジェクション攻撃に晒されることを防いでいます。インターネットアクセスが無効な場合、プロンプトインジェクションの経路は、接続されたGitHubリポジトリ内、またはユーザーが明示的に設定した環境や依存関係に限定されます。
たとえプロンプトインジェクションが発生したとしても、「ネットワークサンドボックス」は重要な防御層となります。モデルは外部エンドポイントにデータを送信できないため、データ流出を防ぎます。また、外部データベースやサービスに接続できないため、リモートデータの破損や削除も防ぎます。
さらに、「ファイルシステムサンドボックス」もプロンプトインジェクションのリスクを限定します。モデルはユーザーが設定したサンドボックス内のファイルにしかアクセスできないため、ユーザーのローカルコンピュータ上のファイルへのアクセスや、サンドボックス外での不正な変更や削除を防ぐことができます。
「安全トレーニング」もプロンプトインジェクション対策の一部です。Codexは、「インストラクション階層(Instruction Hierarchy)」というフレームワークに基づいて、コーディング環境でのプロンプトインジェクション攻撃を無視するように訓練されています。この訓練の効果を測定するために、Codex環境に特化した新しいプロンプトインジェクション評価スイートも開発されました。この評価では、現在のコーディングタスクを終了させようとする攻撃や、特定の文字列(例:「HACKED!」)を出力させようとする攻撃など、いくつかのタイプの攻撃に対するモデルの頑健性がテストされています。評価の結果、高い確率でプロンプトインジェクション攻撃を無視できることが確認されています。

ここでも「ユーザー透明性と差分レビュー」は、万が一、プロンプトインジェクションの影響を受けた場合でも、ユーザーがその行動を検知し、確認できるようにする最終的なセーフティーネットとなります。
2.5 Preparedness
codex-1は、OpenAIの他のフロンティアモデルと同様に、OpenAIの「Preparedness Framework」に基づいて評価されています。このフレームワークは、モデルの潜在的な危険な能力(例えば、化学、生物、放射線、核兵器や、サイバー攻撃に関する能力など)を評価するためのものです。システムカードによると、codex-1は、評価対象のカテゴリーのいずれにおいても「High capability」の閾値には達していないと判断されています。これは、コーディングに特化した追加トレーニングデータが、モデルの基本的なフロンティア能力プロファイルを大きく変更するものではなかったため、安全性の観点から大きな懸念を生むものではないことを示唆しています。
まとめ
本記事では、Codexのシステムカードの一部を読み解き、その安全性への取り組みに焦点を当てて解説しました。Codexは、ソフトウェアエンジニアリングに特化した強力なAIエージェントですが、それに伴う潜在的なリスクに対して、様々な技術的・運用的な緩和策を講じていることが分かりました。
しかし、これらの取り組みを経ても、システムとして完全な安全を保証することは非常に困難であるといえます。AIを活用したソフトウェア開発は、今後ますます普及していくと考えられます。今後利用者側はこうした取り組みを経て発表される脆弱性などに関して理解を深め、問題点を各人で対応していくことも求められます。








