はじめに
私たちの生活は、日々スマートフォンやインターネットを通じて大量のデータと結びついています。便利なサービスを享受する一方で、「自分の情報がどのように使われているのだろうか」「プライバシーは守られているのだろうか」といった不安を感じる方も少なくないでしょう。個人のプライバシーを保護しながらデータを活用することは、現代社会における非常に重要な課題です。
本稿では、このような課題に対する新しいアプローチとして、Google Researchが発表した「信頼グラフ上の差分プライバシー(Trust Graph Differential Privacy: TGDP)」という技術について、その概要と意義をGoogleの技術ブログの記事「Differential privacy on trust graphs」より解説します。この技術は、実社会における人間関係の複雑さを考慮した、より現実に即したプライバシー保護の形を提案するものです。
引用元記事
- タイトル: Differential privacy on trust graphs
- 発行元: Google Research
- 発行日: 2025年5月13日
- URL: https://research.google/blog/differential-privacy-on-trust-graphs/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- 差分プライバシー(DP)は、個人のデータが特定されるリスクを抑えつつ、集計データから有益な情報を得るための強力な枠組みである。
- 既存のDPモデル(中央モデル、ローカルモデル)は、信頼関係を二元的にしか扱えず、現実の多様な信頼レベルに対応しきれないという課題があった。
- 本研究で提案された信頼グラフ上の差分プライバシー(TGDP)は、ユーザー間の信頼関係を「グラフ」としてモデル化し、誰が誰をどの程度信頼しているかに応じてプライバシー保護の度合いを調整する新しいアプローチである。
- TGDPは、中央モデルとローカルモデルを自然に包含する一般化されたフレームワークであり、信頼関係に応じてアルゴリズムの精度とプライバシーレベルのバランスを取ることが可能になる。
- 具体的なアルゴリズムとして、グラフ理論における「支配集合」を用いた集計方法が提案され、そのエラーの上限が示された。また、「パッキング数」を用いてエラーの下限も示された。
- TGDPは、機械学習、特に連合学習におけるプライバシー保護にも応用可能であり、より現実に即した形で個人のデータを保護しながらAI技術の発展に貢献することが期待される。
詳細解説
プライバシー保護の重要性と差分プライバシーの基本
現代社会において、個人のデータは様々な形で収集・分析され、新しいサービスや価値を生み出しています。しかし、その裏側では、個人のプライバシーが侵害されるリスクも常に存在します。例えば、購買履歴から個人の嗜好が詳細に分析されたり、位置情報から行動パターンが把握されたりすることが考えられます。日本では、個人情報保護法によって個人の権利利益の保護が図られていますが、技術の進歩とともに、より高度なプライバシー保護技術が求められています。
そこで注目されているのが「差分プライバシー(Differential Privacy: DP)」という考え方です。これは、「あるデータベースに特定の個人のデータが含まれているか否かによって、分析結果が大きく変わらないようにする」という統計的な性質を保証するものです。具体的には、データに意図的に「ノイズ」と呼ばれるランダムな値を加えることで、個人の特定を防ぎつつ、全体の傾向を把握できるようにします。これにより、個人のプライバシーを守りながら、集団としてのデータから有益な知見を引き出すことが可能になります。
既存の差分プライバシーモデルとその限界
差分プライバシーを実現するための主要なモデルとして、以下の二つが知られています。
- 中央モデル(Central Model):
- 仕組み: 信頼できる第三者(キュレーター)が、個々のユーザーから生のデータを収集し、一括して差分プライバシー処理を施した上で分析結果を公開します。
- メリット: 比較的高い精度で分析結果を得られます。
- デメリット: 全てのデータが一箇所に集まるため、そのキュレーターに対する絶対的な信頼が必要になります。もしキュレーターが悪意を持ったり、攻撃を受けたりした場合、プライバシー侵害のリスクが高まります。
- ローカルモデル(Local Model):
- 仕組み: 各ユーザーが自身のデータをデバイス上で差分プライバシー処理(ノイズを加えるなど)してから、サーバーや他のユーザーに送信します。
- メリット: 信頼できる第三者を必要とせず、個々人の手元でプライバシーが保護されるため、より強い安心感が得られます。
- デメリット: 各データに加えられるノイズの量が相対的に大きくなるため、分析結果の精度が中央モデルに比べて低下しやすい傾向があります。
これらのモデルは強力ですが、現実世界の複雑な人間関係や信頼の度合いを十分に反映できているとは言えません。例えば、家族や親しい友人には共有しても良い情報でも、見知らぬ他人には知られたくない、といった状況は日常的にあります。しかし、既存のモデルでは「全員を信頼する(中央モデルのキュレーターを信頼する)」か「誰も信頼しない(ローカルモデル)」という二元的な仮定に基づいているため、こうしたグラデーションのある信頼関係を柔軟に扱うことができませんでした。
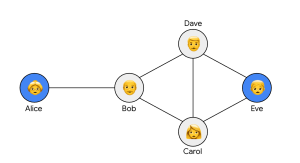
新しい提案:信頼グラフ上の差分プライバシー(TGDP)とは
そこで、Google Researchの研究者たちは、「信頼グラフ上の差分プライバシー(Trust Graph Differential Privacy: TGDP)」という新しいモデルを提案しました。これは、ユーザー間の信頼関係を「信頼グラフ」という形で表現し、それに基づいてプライバシー保護のレベルを調整するという画期的なアイデアです。
- 信頼グラフとは:
- グラフ理論における「グラフ」を用いて、ユーザー間の信頼関係を視覚化したものです。
- 各ユーザーを「頂点(ノード)」で表します。
- ユーザー間で信頼関係がある場合、それらの頂点を「辺(エッジ)」で結びます。
下の図は、信頼グラフの一例です。アリスはボブを信頼し、ボブはキャロルとデイブを信頼し、キャロルとデイブはイブを信頼している、という関係を表しています。

TGDPの定義では、「あるユーザーUの情報は、Uが信頼していない他のユーザー(群)からは保護されるべきである」と考えます。具体的には、ユーザーUの元々のデータが何であれ、U(またはUが信頼する隣人)と、Uが信頼していない他のユーザーとの間で交換されるメッセージの統計的な性質が変わらないようにします。先の例で言えば、アリスの個人情報は、アリスが直接信頼していないキャロル、デイブ、イブには知られないように保護される、ということです。たとえキャロル、デイブ、イブが結託して情報を集めようとしても、アリスの情報を特定することは困難になります。
TGDPは、既存の中央モデルとローカルモデルを自然に内包する、より一般的な枠組みと考えることができます。
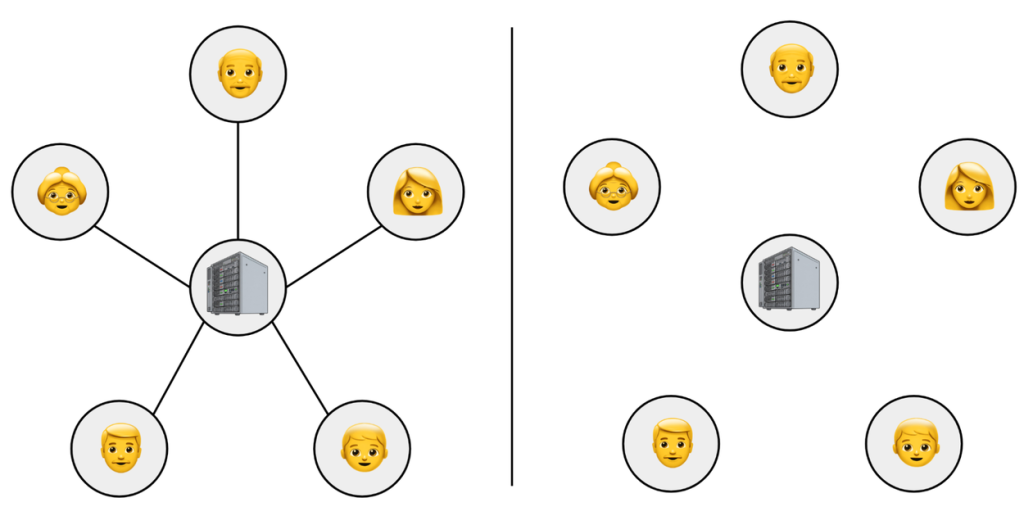
- 中央モデルとの関係: もし信頼グラフが、中央のキュレーター(サーバーなど)に全てのユーザーが繋がっている「スターグラフ(星形グラフ)」であれば、TGDPは中央モデルと等価になります。
- ローカルモデルとの関係: もし信頼グラフが、どのユーザー間にも信頼関係がない(辺がない)「完全に非連結なグラフ」であれば、TGDPはローカルモデルと等価になります。
このように、TGDPは信頼関係の構造に応じて、プライバシー保護の強度とデータ活用の精度を柔軟に調整できる可能性を秘めています。
TGDPの技術的なポイント
研究論文では、TGDPの具体的なアルゴリズムと、その性能評価(エラーの上下限)について議論されています。ここでは、特に「集計タスク」と呼ばれる基本的な問題設定を通じて、その技術的な核心に触れてみましょう。集計タスクとは、各ユーザーが持つ私的な数値データ(例えば、あるサービスの利用時間や満足度など)の合計値を、プライバシーを保護しながらできるだけ正確に推定する問題です。
- 支配集合アルゴリズム:
提案されているアルゴリズムの一つは、グラフ理論における「支配集合(Dominating Set)」という概念を利用します。- 支配集合とは:
グラフの頂点の部分集合Tであって、Tに属していない全ての頂点が、Tに属する少なくとも一つの頂点と辺で結ばれている(隣接している)ような集合のことです。簡単に言えば、支配集合Tのメンバーの誰かが、グラフ全体の「見張り役」や「情報集約役」を担うイメージです。 - アルゴリズムの動作:
- 信頼グラフから支配集合Tを見つけます。
- 各ユーザーは、自分のデータを、信頼している支配集合T内の隣人(誰か一人)に送信します。
- 支配集合T内の各ユーザーは、集まってきたデータの合計を計算し、そこに適切な量(プライバシーレベルに応じた量)のラプラスノイズ(差分プライバシーでよく用いられるノイズの一種)を加えます。
- ノイズが加えられた合計値が、支配集合Tの各メンバーからブロードキャスト(全体に通知)されます。
- 最終的な集計結果の推定値は、これらのブロードキャストされた値の合計となります。
- エラーの上限: このアルゴリズムによる推定誤差(真の合計値とのズレ)は、用いた支配集合Tのサイズ(頂点の数)が小さいほど小さくなる傾向があります。特に、可能な限り最小の支配集合(これを最小支配集合といい、そのサイズを支配数と呼びます)を見つけることができれば、エラーの上限を抑えることができます。つまり、信頼ネットワークの中で効率的に情報を集約できる少数の「ハブ」を見つけることが重要になります。
- 支配集合とは:
- エラーの下限とパッキング数:
一方で、どんなに優れたアルゴリズムを用いても、達成できる精度には限界があります。この「エラーの下限」を特徴づけるために、「パッキング数(Packing Number)」というグラフ理論の別の概念が用いられます。- パッキング数とは: グラフ内で、どの二つの頂点も互いに隣接しておらず、かつ共通の隣人も持たないような頂点の集合のうち、最大のサイズを指します。直感的には、グラフの中で互いに「遠い」あるいは「独立している」ユーザーの最大数と考えることができます。
- エラーの下限: 論文では、いかなるTGDPアルゴリズムも、そのエラーの大きさがパッキング数に比例するある定数よりも小さくなることはないと証明されています。つまり、ネットワーク内に互いに独立した情報源が多いほど、全体の情報を正確に集約することは難しくなることを示唆しています。
- パッキング数とは: グラフ内で、どの二つの頂点も互いに隣接しておらず、かつ共通の隣人も持たないような頂点の集合のうち、最大のサイズを指します。直感的には、グラフの中で互いに「遠い」あるいは「独立している」ユーザーの最大数と考えることができます。
- 上下限のギャップと今後の課題:
一般的に、グラフの支配数はパッキング数以上になることが知られています。しかし、両者が常に一致するわけではなく、グラフの構造によっては大きな「ギャップ」が生じることがあります。これは、現状のアルゴリズム(支配集合アルゴリズムなど)によるエラーの上限と、理論的なエラーの下限との間にまだ改善の余地があることを意味しています。このギャップを埋める、より最適なアルゴリズムの開発は、今後の重要な研究課題の一つです。
TGDPの応用可能性:機械学習への展開
TGDPの考え方は、単純な数値集計だけでなく、より複雑なタスクにも応用できます。特に期待されるのが、機械学習(Machine Learning: ML)、とりわけ連合学習(Federated Learning)への応用です。
- 連合学習とは: 個々のユーザーの生データを中央サーバーに集めることなく、各ユーザーのデバイス上でモデルの学習を行い、その学習結果(例えば、モデルの更新部分である「勾配」というベクトルデータ)のみをサーバーで集約して、全体のモデルを賢くしていく技術です。プライバシー保護とAI開発の両立を目指す上で非常に重要なアプローチとされています。
TGDPは、この連合学習の枠組みに自然に適合します。集計タスクで用いた支配集合プロトコルは、実数の集計だけでなく、ベクトルデータ(機械学習の勾配など)の集計にも拡張できます。TGDPの枠組みでベクトル集計を行うことにより、最終的に得られる機械学習モデル自体もTGDPのプライバシー保証を満たすことになります。これにより、ユーザー間の信頼関係を考慮した、よりきめ細やかなプライバシー保護のもとで機械学習モデルを構築・運用できるようになる可能性があります。
まとめ
本稿では、Google Researchによって提案された新しいプライバシー保護の枠組み「信頼グラフ上の差分プライバシー(TGDP)」について解説しました。TGDPは、ユーザー間の多様な信頼関係を「信頼グラフ」としてモデル化し、それに基づいてプライバシー保護のレベルを調整するという、より現実に即したアプローチです。
この技術は、既存の中央モデルやローカルモデルの限界を克服し、プライバシーとデータ活用の精度の間でより柔軟なバランスを取ることを可能にします。特に、連合学習などの機械学習分野への応用が期待されており、個人のデータをより安全に、かつ効果的に活用する道を開く可能性があります。
日本においても、SNSでの情報共有から医療分野に至るまで、TGDPの考え方が応用できる場面は多岐にわたります。私たちの人間関係や社会構造を考慮に入れたプライバシー保護技術の発展は、より安心してデジタル社会の恩恵を享受するために不可欠と言えるでしょう。TGDPは、その重要な一歩となる可能性を秘めています。今後の研究の進展と、社会への実装に注目していきたいと思います。