はじめに
近年、AI、特にDeep Learning技術は、画像認識、自然言語処理といった分野で目覚ましい成功を収めていますが、多くの実世界のデータ、特に企業の基幹システムに蓄積されるリレーショナルデータベース(RDB)に内在する複雑な関係性を捉え、活用することは依然として大きな挑戦です。顧客と製品、取引履歴、サプライチェーンなど、複数のテーブルに分散し、相互にリンクされたデータは、個々のレコードだけでは見えない価値ある洞察の宝庫ですが、従来の機械学習アプローチでは、この構造を効果的にモデル化することが困難でした。多くの場合、複雑なJOIN操作や手作業による特徴量エンジニアリングが必要となり、時間とコストがかかるだけでなく、データの持つ本来の構造や意味情報が失われるリスクも伴いました。
本稿では、この課題に対する有望な解決策として登場した「Relational Graph Transformers」アーキテクチャについて、エンジニア向けに詳細に解説します。この技術は、Relational Deep Learningの自然な進化形と位置づけられ、RDBをその本質であるグラフ構造としてネイティブに扱うことで、従来のアプローチが抱えていた多くの制約を克服します。煩雑な前処理や特徴量エンジニアリングの大部分を不要にし、データ間のリレーションシップから直接学習することで、より高精度で効率的なAIモデルの構築を可能にします。
引用元記事
- タイトル: Relational Graph Transformers: A New Frontier in AI for Relational Data
- 発行元: Kumo.ai
- 発行日: 2025年4月28日
- URL: https://kumo.ai/research/relational-graph-transformers/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
Relational Graph Transformersは、エンタープライズ環境で広く利用されるRDBに格納された情報を、AIが構造を保ったまま効率的に学習するための新しいアーキテクチャパラダイムです。
- 課題: 従来のML/DLモデルは、複数テーブル間の関係性(例: 1対多、多対多)やスキーマ構造を直接活用することが困難でした。そのため、多くの場合、情報を損失する可能性のあるテーブル結合や、ドメイン知識に依存した手動の特徴量エンジニアリングが必要でした。
- 解決策: RDB全体を、テーブルの各行(エンティティ)をノード、外部キー関係をエッジとする異種グラフ(Heterogeneous Graph)として表現します。ノードとエッジはそれぞれのタイプ(テーブル名、関係名)を持ち、属性情報(カラム値)を保持します。これにより、データ間の複雑な関係性をモデルが直接学習可能になります。
- 技術: 自然言語処理(NLP)でTransformerアーキテクチャが達成した成功を、グラフ構造データ、特にリレーショナルエンティティグラフに適用します。中核となるアテンションメカニズムを活用し、固定的なグラフ構造に縛られず、タスクに応じてグラフ内のノード間の長期的な依存関係や重要な関連性を動的に捉えます。
- 効果: 従来のアプローチ(手動特徴量エンジニアリング+古典的ML、あるいは単純なGNN)と比較して、モデル開発から価値創出までの時間(Time-to-Value)を20倍高速化、予測精度(例: AUC)を30-50%向上、データ準備に関わる労力を95%削減といった、顕著な改善が報告されています。これは、データ構造を活かした効率的な学習と自動化によるものです。
- 応用: 顧客分析(チャーン予測、LTV予測、セグメンテーション)、リアルタイム推薦システム、金融分野での不正検知、サプライチェーン最適化、需要予測など、RDBがデータ基盤の中心となる多くのエンタープライズAIアプリケーションにおいて、その有効性が期待されます。
詳細解説
1. 前提となる技術概念
Relational Graph Transformersのアーキテクチャと動作原理を理解するために、以下の基盤となる技術要素が前提となります。
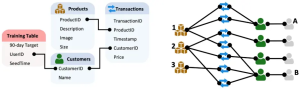
- リレーショナルデータベース (RDB): リレーショナルモデルに基づき、データを正規化されたテーブルの集合として格納したもの。主キー(Primary Key)が一意なレコードを識別し、外部キー(Foreign Key)がテーブル間の参照整合性を保証し、リレーションシップ(1対1、 1対多、多対多)を定義します。SQL(Structured Query Language)を用いてデータの操作や問い合わせを行います。RDBの強みはデータの整合性と構造化にありますが、複雑な関係性を横断するクエリは高コストになることがあります。
- グラフ (Graph): ノード(Vertices/Entities)とそれらを接続するエッジ(Links/Relationships)Eのペア G=(V,E) で構成されるデータ構造。ソーシャルネットワーク、分子構造、知識ベースなど、関係性を持つデータを表現するのに適しています。特に、ノードやエッジが複数のタイプを持つ場合、異種グラフ (Heterogeneous Graph) と呼ばれ、RDBの構造をより自然に表現できます(例: CustomerノードとProductノード、purchasedエッジ)。グラフ理論は、これらの構造を分析するための数学的基盤を提供します。
- Graph Neural Networks (GNNs): グラフ構造データを直接処理するために設計された深層学習モデルの総称。代表的なものにGCN、 GraphSAGE、 GATなどがあります。多くはメッセージパッシングパラダイムに基づき、各ノードがその近傍ノードから情報を集約し、自身の状態(埋め込みベクトル)を更新する処理を層状に繰り返します。これにより、ノードの局所的な構造情報がエンコードされますが、遠距離の依存関係を捉えるには多くの層が必要になる(Over-smoothing問題の一因)という課題があります。
- Transformers: GoogleのVaswaniらによって提案された、主にSelf-Attentionメカニズムに基づいて構築されたニューラルネットワークアーキテクチャ。元々はNLPのシーケンス・ツー・シーケンス問題のために開発されました。入力シーケンス(または集合)内の全要素ペア間の関連度を動的に計算し、文脈に応じたリッチな表現を獲得します。並列計算が可能で、長距離依存関係の捕捉に優れている点が特徴ですが、計算量が入力長の二乗に比例するため、非常に長いシーケンスや大規模グラフへの適用には工夫が必要です。
- アテンションメカニズム (Attention Mechanism): 入力データの中から、現在の処理(例: 次の単語の予測、ノードの分類)にとってどの部分がより重要であるかに「注意」を向け、その重要度に応じて重み付けを行うメカニズム。Transformerでは、Query、 Key、 Valueという3つのベクトルを用いてScaled Dot-Product Attentionが計算され、これにより各要素が他の全要素との関連性を考慮した表現を獲得します。
2. Relational Graph Transformersの必要性:既存の課題の克服
従来の機械学習モデルでRDBを扱う際に直面する課題は、単なる手間やコストの問題にとどまりません。
- 情報の損失と歪み: 複数テーブルをJOINして単一のフラットなテーブルを作成するプロセスは、特に多対多の関係性を持つ場合に情報の爆発(行数の急増)や情報の損失(集約による詳細の欠落)を引き起こす可能性があります。また、どのテーブルを主軸にJOINするかによって結果が変わり、恣意的なバイアスが入る可能性もあります。元のリレーショナル構造が持つ豊かな意味論的情報(どのエンティティがどのように関連しているか)が、フラット化によって大きく損なわれています。
- 特徴量エンジニアリングの限界と属人性: ドメイン知識に基づき、手動で有効な特徴量を設計・抽出する作業は、「アート」とも呼ばれ、担当者のスキルや経験に大きく依存します。時間と専門知識を要するだけでなく、網羅的な探索は困難であり、潜在的に重要な特徴量が見逃される可能性があります。また、ビジネス要件の変化に応じて特徴量を再設計する必要も生じます。
- スケーラビリティと計算効率: テーブル数やデータ量が増加するにつれて、JOIN操作や特徴量生成の計算コストは非線形に増大します。特に大規模なトランザクション履歴やログデータを扱う場合、全データをメモリにロードして処理することは現実的ではなく、分散処理基盤などが必要になりますが、それでも効率的な処理は困難な場合があります。
Relational Graph Transformersは、これらの課題に対する根本的なアプローチを提供します。RDBをグラフとして直接モデル化することで、JOIN操作やフラット化を回避し、データ構造をそのまま活かします。Transformerアーキテクチャを用いることで、特徴量エンジニアリングの多くをモデル自身に学習させ、データ間の複雑な関係性をエンドツーエンドで捉えることを目指します。これにより、開発プロセスの自動化・簡略化と、より深いデータ理解に基づく高精度な予測の両立を可能にします。
3. Relational Graph Transformersのアーキテクチャと処理フロー:詳細
Relational Graph Transformersの処理パイプラインは、いくつかの重要な技術要素から成り立っています。
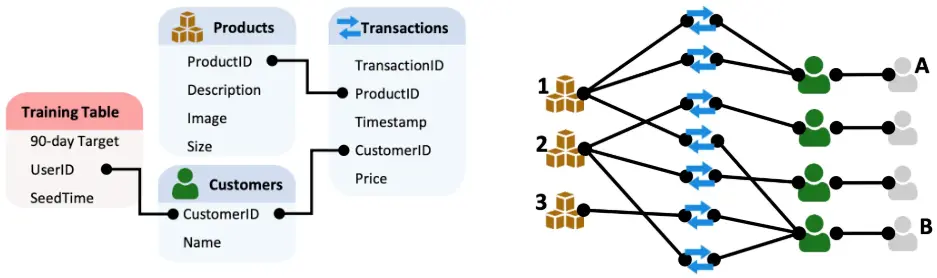
1.RDBからグラフへの変換:構造の抽出と表現
- スキーマグラフ (Schema Graph) の構築: このステップは、グラフ変換の設計図を作成するプロセスです。RDBのメタデータ(INFORMATION_SCHEMAなど)を解析し、テーブルをノードタイプ、外部キー制約を(方向性を持つ)エッジタイプとして定義します。逆方向のエッジ(例: ProductからTransactionへのリンク)も定義することで、グラフ内での情報の双方向伝播を可能にします。このスキーマグラフは、後続のエンティティグラフの構造と型制約を定義します。
- リレーショナルエンティティグラフ (Relational Entity Graph) の構築: スキーマグラフの定義に従い、実際のデータからグラフインスタンスを構築します。
- ノード生成: RDBの各テーブルの各行が、対応するノードタイプのノードとしてグラフに追加されます。各ノードは、元の行の主キー、外部キー、そして各種属性値を保持します。属性値は、次のエンコーディングステップへの入力となります。
- エッジ生成: 外部キー関係に基づいて、対応するノード間にエッジが生成されます。エッジはスキーマグラフで定義されたタイプを持ちます(例: Customersテーブルの行ノードとTransactionsテーブルの行ノード間にmade_transactionタイプのエッジ)。
- 異種性と時間性: 結果として得られるグラフは、複数のノードタイプとエッジタイプを持つ異種グラフです。トランザクションデータのように時間情報を持つテーブルが含まれる場合、ノードやエッジにタイムスタンプ属性を付与し、時間的グラフ (Temporal Graph) として扱います。これにより、時間的順序性を考慮したモデリングが可能になります。
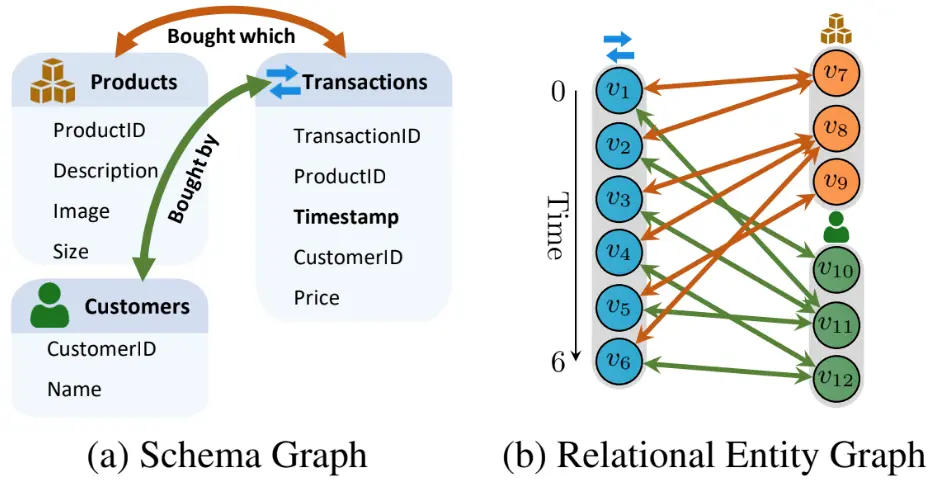
2. マルチモーダルノード特徴量のエンコーディング:多様な情報のベクトル化
- RDBのテーブルは通常、数値(価格、年齢)、カテゴリ(性別、商品カテゴリ)、テキスト(商品説明、レビュー)、画像(商品画像)、タイムスタンプなど、多様なデータ型(マルチモーダル)のカラムを含みます。これらを統一されたベクトル空間に写像し、Transformerが処理できる形式にする必要があります。
- モダリティ固有エンコーディング: 各データ型に最適化されたエンコーディング手法を適用します。
- 数値: 欠損値補完、正規化(Min-Max, Z-score)の後、MLPを通して埋め込みベクトルに変換するか、そのまま利用します。
- カテゴリ: 各カテゴリ値に一意なIDを割り当て、学習可能な埋め込みテーブル(Embedding Lookup)を用いて密なベクトル表現を獲得します。高カーディナリティの場合は、Hashing Trickなども検討されます。
- テキスト: TF-IDFのような古典的手法や、BERT、Sentence-BERTなどの事前学習済み言語モデルを用いて、テキストの意味を捉えた埋め込みベクトルを生成します。
- 画像: ResNet、 VGG、 Vision Transformerなどの事前学習済みモデルを用いて、画像の特徴を抽出したベクトルを得ます。
- タイムスタンプ: Unixタイムスタンプのような連続値として扱う、年月日時などの要素に分割してカテゴリ特徴として扱う、あるいは三角関数(sin/cos)を用いて周期性を捉えるなど、タスクに応じてエンコードします。
- 属性埋め込みの統合(フュージョン): 各属性から得られた個別の埋め込みベクトルを、単一の初期ノード埋め込みベクトルに統合します。単純な連結(Concatenation)後にMLPで処理する方法、Attentionメカニズムを用いて属性間の相互作用を考慮しながら統合する方法などがあります。記事で言及されている通りPyTorch は、このような異種・マルチモーダルな表形式データに対するエンコーディングと統合のパイプラインを効率的に構築・管理するために設計されており、モジュール性と再利用性を高めます。
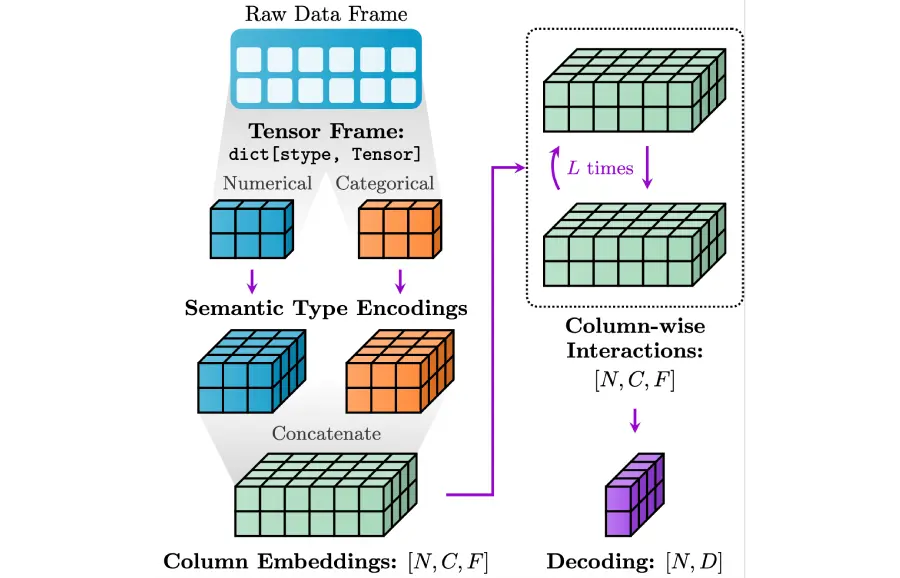
3. Relational Graph Transformerによる学習:関係性の動的捕捉
- エンコードされた初期ノード埋め込みとリレーショナルエンティティグラフ構造を入力として、Transformerベースのモデルでエンドツーエンドの学習を行います。
- アテンションメカニズムの適用と拡張: 標準的なTransformerのSelf-Attentionをグラフ構造に適応させます。
- グラフ構造の活用 (Relational Graph Connectivity): 全ノードペア間のアテンション計算 (O(N2)) は大規模グラフでは非現実的です。そのため、グラフのスパース性を活用します。アテンション計算を、GNNのようにk-hop近傍内のノードに限定する(Neighborhood Attention)、あるいはグラフ構造に基づいて定義されたスパースなアテンションパターンを用いるなどのアプローチが取られます。これにより、計算効率を改善しつつ、グラフの局所構造という誘導バイアス (Inductive Bias) を導入します。しかし、Transformerの利点である長距離依存関係の捕捉能力も維持するため、サンプリングされたノード集合内では(限定的ながらも)全結合に近いアテンションを計算することが多いです。
- エッジタイプの考慮 (Relational Edge Awareness): 異種グラフではエッジタイプが重要な意味を持ちます。これをアテンション計算に組み込むため、Relation-aware Attentionが用いられます。例えば、Query、Key、Valueの射影行列をエッジタイプごとに用意する、アテンションスコア計算時にエッジタイプに応じたバイアス項を加える、あるいはエッジタイプに基づいてアテンションの重みをゲートするなど、様々な方法が提案されています (例: Heterogeneous Graph Transformer – HGT)。これにより、モデルは「どのノードが関連しているか」だけでなく、「どのような関係性で関連しているか」も考慮できるようになります。
- 位置エンコーディング (Positional Encoding) の導入:グラフ内でのノードの位置づけ
- 標準的なTransformerは入力要素の順序情報を扱えないため、NLPではSinusoidal Positional Encodingなどが用いられます。グラフには明確な順序がないため、グラフ構造におけるノードの「位置」や「役割」を示すための代替的なエンコーディングが必要です。
- ホップエンコーディング (Hop Encoding): 予測対象のターゲットノードからのグラフ距離(最短経路ホップ数)をエンコードします。ターゲットに近いノードほど重要であるという直感をモデルに与えます。
- ツリーエンコーディング (Tree Encoding): 近傍サンプリングによって得られる計算サブグラフは、しばしばツリー状の構造を持ちます。このツリー内でのノードの深さや親子・兄弟関係といった階層構造をエンコードすることで、局所的なトポロジー情報をより豊かに表現します (例: Tree-LSTMの発想に近い)。
- メッセージパッシングエンコーディング (Message Passing Encoding): 大規模グラフ全体に対するLaplacian固有ベクトルやDeepWalkなどの計算は高コストです。代わりに、各ノードにランダムなベクトルを割り当て、それを数ステップのGNNメッセージパッシング(元のグラフ構造上で行う)によって更新することで、局所的な接続パターンを反映した一種の構造的埋め込みを近似的に獲得します。これは、高価な事前計算なしに構造情報を与える実用的な方法です。
- 時間エンコーディング (Time Encoding): 時間的グラフの場合、イベント発生時刻(タイムスタンプ)を連続値や周期関数などでエンコードし、入力特徴量に加えます。これは、モデルが時間的順序性(例: 購入履歴の順番)を学習し、未来の情報が過去の予測に影響を与えるデータリーク(Time Travel)を防ぐために極めて重要です。アテンション計算時に時間的なマスキング(未来の情報を参照しないようにする)と併用されることもあります。
- これらの位置エンコーディングは、通常、ノードの属性埋め込みに加算(Add)または連結(Concatenate)され、Transformerレイヤーへの最終的な入力となります。複数のエンコーディングを組み合わせることで、グラフ構造の異なる側面をモデルに伝えることができます。
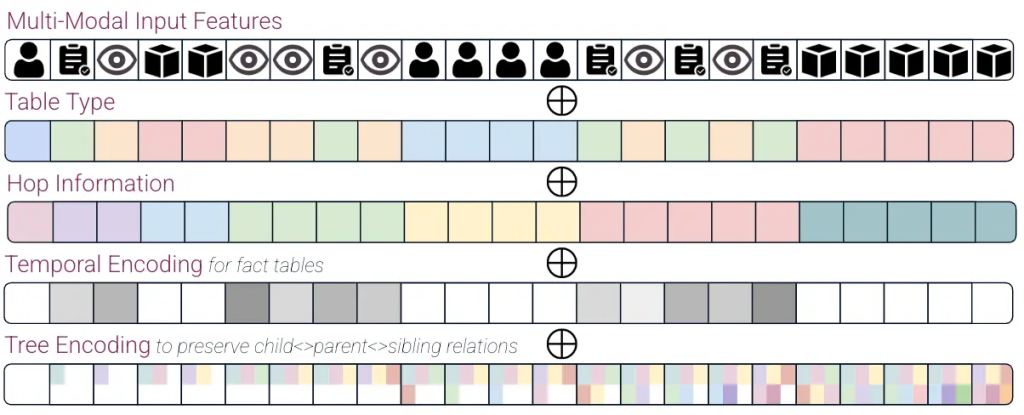
4. スケーラビリティへの対応:大規模グラフへの挑戦
- エンタープライズ規模のグラフ(数百万〜数億ノード、数十億エッジ)に深層学習モデルを適用するには、スケーラビリティが最重要課題となります。
- 近傍サンプリング (Neighbor Sampling): 学習時、全グラフをメモリに載せる代わりに、ミニバッチごとに予測対象ノード(群)を選択し、そのノードから数ホップ(例: 2ホップ)の範囲で隣接ノードを確率的または決定論的にサンプリングして計算サブグラフを構築します。GraphSAGEで提案されたこの手法は、GNNやGraph Transformerのスケーラビリティを確保するための標準的な技術となっています。サンプリング戦略(一様サンプリング、重要度サンプリングなど)やサンプリングする隣接ノード数は、計算コストと性能のトレードオフに影響します。異種グラフの場合、ノードタイプやエッジタイプを考慮したサンプリングが必要です。
- 計算量の削減: 標準的なTransformerのSelf-Attention (O(N2)) は、サンプリングされたサブグラフ内でもノード数が増えるとボトルネックになります。これを緩和するため、近似アテンション (Approximate Attention) メカニズムが研究されています。例えば、低ランク近似(Linformer)、カーネル法(Performer)、スパース化(Sparse Transformer)などの手法を用いて、計算量を O(NlogN) や O(N) に削減することを目指します。これらの手法は、精度を大きく損なわずに計算効率を向上させることを目的としています。
- システムレベルの最適化: 大規模なモデルとデータを扱うためには、GPUメモリの効率的な利用、複数GPUを用いた分散学習(データ並列、モデル並列)、効率的なグラフデータ構造と操作ライブラリ(例: DGL, PyG)の活用など、システムレベルでの最適化も重要になります。
4. 実験結果と考察:性能と洞察
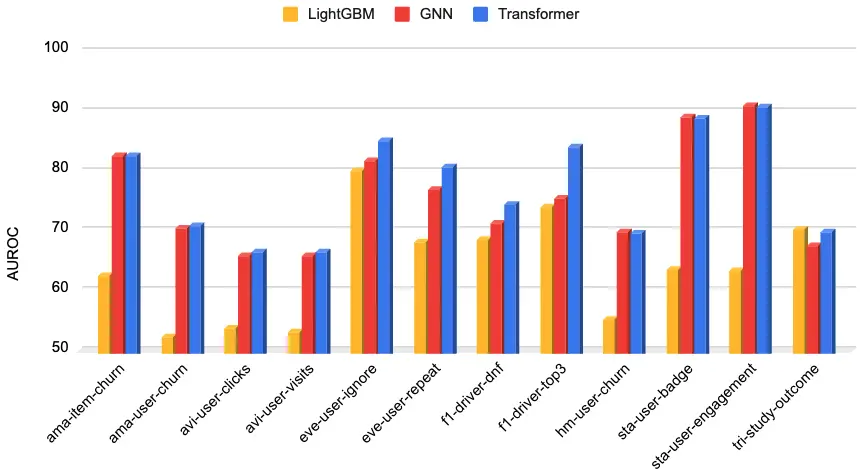
記事で紹介されているRelBenchベンチマークを用いた評価実験は、Relational Graph Transformersの有効性を定量的に示しています。
- RelBenchの概要: RelBenchは、実世界の様々なドメイン(Eコマース: Amazon, 広告: Avito, イベントベース: Epinionsなど)から収集されたリレーショナルデータベースと、それに対する現実的な予測タスク(例: ユーザーのチャーン予測、アイテム推薦、エンティティ分類)を提供するために設計されたベンチマークです。これにより、異なるモデルアーキテクチャや手法を公平かつ再現可能な形で比較評価することが可能になります。
- 評価指標: 主にROC-AUCが用いられています。これは二値分類タスクにおいて、モデルの識別能力(真陽性率と偽陽性率の関係)を総合的に評価する指標であり、クラス不均衡の影響を受けにくいという特徴があります。
- 比較対象:
- LightGBM: 高速かつ高精度な勾配ブースティング決定木モデル。ここでは、ターゲットエンティティが含まれる単一テーブルの行特徴のみを入力としており、リレーショナルな情報を活用しない古典的な機械学習ベースラインとしての役割を果たします。
- 標準的なGNN: メッセージパッシングに基づくグラフニューラルネットワーク。RelBenchのデータセットに対して最適化されたGNNアーキテクチャが比較対象となります。
- 実験設定の詳細: GNNとTransformerの両方で、計算コストを揃えるために2ホップの近傍サンプリング(各ホップで15ノードをサンプリング)が用いられています。これは、両モデルが基本的に同じ局所的な情報(2ホップ範囲内のノードとエッジ)にアクセスできることを意味します。ノード埋め込みの次元数は128に統一されています。Transformerモデルは、4層のエンコーダレイヤー、8つのアテンションヘッド、フィードフォワードネットワーク(FFN)の隠れ層次元数を512(ノード次元の4倍)という、比較的一般的な設定で評価されています。
- 結果の解釈:
- GNNに対する優位性: Relational Graph Transformerは、多くのタスクでGNNを平均約10%上回る精度を達成しました。これは、同じ局所情報(2ホップ近傍)が与えられた場合でも、Transformerのアテンションメカニズムがノード間の関係性をより柔軟かつ効果的に捉えられることを示唆しています。GNNのメッセージパッシングは、情報を1ホップずつ固定的に伝播させるのに対し、アテンションはサブグラフ内の任意のノードペア間の関連度を動的に計算し、タスクにとって重要な情報を直接的に集約できます。特に、2ホップ以上離れたノード間の間接的な関係性(例: 同じ商品を異なる時期に購入した顧客間の類似性)の捕捉において有利であると考えられます。
- LightGBMに対する大幅な改善: LightGBMと比較して40%以上の精度向上は、リレーショナルな情報(他のテーブルや関係性)を活用することの重要性を明確に示しています。単一テーブルの情報だけでは捉えきれない複雑なパターンや文脈を、グラフ構造全体から学習することで、予測精度が劇的に向上することを示唆しています。
- 長期依存関係の捕捉: Transformerアーキテクチャは、原理的にグラフ内の任意のノード間の依存関係をモデル化できるため、長期的な依存関係 (long-range dependencies) の捕捉に優れていると考えられます。これは、例えば、数ヶ月前の購買行動が現在の確率に影響を与えるような場合に特に有効です。
- 考察と今後の方向性:
- サンプリング戦略の影響: 現在の実験は2ホップサンプリングという制約下で行われていますが、GNNと異なりTransformerは原理的に非接続ノードからの情報集約も可能です。より広範な情報を捉えるサンプリング戦略(例: より多くのホップ数、より多様なノードを選択する手法)や、サブグラフ間の情報を交換するメカニズム(例: 記事で示唆されるクロスアテンション)を導入することで、更なる性能向上が期待されます。
- 位置エンコーディングの重要性: 実験結果は、多様な位置エンコーディングを組み合わせることが、Transformerがグラフ構造を理解し、高い性能を発揮するために重要であることを裏付けています。どのエンコーディングがどのタスクやデータ構造に有効であるかを探求することは、今後の重要な研究テーマです。
- アーキテクチャの選択: 全てのタスクでTransformerがGNNを大幅に上回るわけではなく、タスクやデータの特性によってはGNNが依然として有効な場合もあります。モデル選択は、精度、計算コスト、解釈性などのトレードオフを考慮して行う必要があります。
まとめ
本稿では、エンジニア向けに「Relational Graph Transformers」の技術的背景、アーキテクチャ、主要な構成要素、そしてその有効性についての解説を行いました。
このアーキテクチャは、エンタープライズデータの中核であるRDBを、その関係性を保持した異種グラフとしてネイティブにモデル化し、Transformerの強力な表現学習能力、特にアテンションメカニズムを適用することで、従来の手法では困難だった複雑なデータ間の構造と関係性を効果的に捉えます。その実現には、マルチモーダルな特徴量エンコーディングによる多様なデータ型の統合、グラフ構造とエッジタイプを考慮したRelation-aware Attention、グラフ内でのノードの位置づけを支援する多様な位置エンコーディング、そして大規模データに対応するためのスケーラビリティ確保の工夫(近傍サンプリング、近似アテンション) が不可欠な技術要素となっています。
RelBenchベンチマークを用いた実験結果は、従来のGNNや古典的機械学習モデルに対する明確な優位性を示しており、特にエンタープライズデータに普遍的に存在する長距離依存性のモデリングにおいて高いポテンシャルを持つことを裏付けています。データ準備の労力を大幅に削減しつつ、より深いデータ理解に基づいた高い予測精度を実現するこの技術は、単なる既存手法の改善ではなく、リレーショナルデータに対するAIの関わり方を変革する、今後のエンタープライズAIにおける重要なブレークスルーとなる可能性を秘めています。スマートなサンプリング戦略、グローバルな文脈の統合、より表現力の高い位置エンコーディングなど、更なる研究開発によって、その能力は今後さらに向上していくことが期待されます。