はじめに
本稿では、Alibaba CloudのQwenシリーズの最新世代である大規模言語モデルQwen3について、AIエンジニアの皆様に向けてその技術的な側面を詳細に解説します。
Qwen3は、訓練データ、モデルアーキテクチャ、最適化技術における広範な進歩に基づき、前世代のQwen2.5から大幅な改善を実現しています。特に、Mixture-of-Experts (MoE)モデルとDenseモデルの両方を提供し、ハイブリッド思考モードや多言語対応、エージェント能力の向上など、注目すべき特徴を備えています。
引用元記事
- タイトル: Qwen3: Think Deeper, Act Faster
- 発行元: Qwen Team
- 発行日: 2025年4月29日
- URL: https://qwenlm.github.io/blog/qwen3/
- 関連リソース:
- Hugging Face (例: Qwen3-0.6B-Base): https://huggingface.co/Qwen/Qwen3-0.6B-Base
- GitHub: https://github.com/QwenLM/Qwen3
GoogleColab(弊社作成)
https://colab.research.google.com/drive/1V68faX3SaCNihzxS2Yu7Xa5ZZySErjma?usp=sharing
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- モデルラインナップ: Qwen3は、0.6Bから235Bまでのパラメータを持つDenseモデルとMoEモデルの包括的なスイートを提供します。MoEモデル(例: Qwen3-235B-A22B)は、活性化パラメータ数を抑えつつ高い性能を実現します。
- 訓練データ: Qwen2.5の3倍となる119言語をカバーする36兆トークンの高品質なデータセットで事前学習されています。コーディング、STEM、推論、書籍、多言語、合成データなどが豊富に含まれます。
- 訓練手法とアーキテクチャ: MoEモデル向けのglobal-batch load balancing lossや全モデル向けのqk layernormなどの新しい訓練技術とアーキテクチャ改良を導入し、安定性と性能を向上させています。
- 3段階の事前学習:
- 広範な言語モデリングと一般知識獲得 (4Kコンテキスト長)
- STEM、コーディング、論理推論などの推論スキル向上
- 高品質な長文コンテキストデータによる長文読解能力向上 (最大32K/128Kコンテキスト長)
- ハイブリッド思考モード: 複雑な問題に対して段階的に推論する「思考モード」と、簡単な質問に迅速に応答する「非思考モード」を切り替え可能で、タスクに応じた思考予算の制御を実現します。
- 多言語対応: 119の言語と方言をサポートし、グローバルな応用を可能にします。
- エージェント能力の向上: コーディングとエージェント能力が最適化され、MCP (Multi-agent Collaboration Protocol)のサポートも強化されています。
詳細解説
前提知識: MoE, GQA, LayerNorm, CoT, RL
以下の知識が前提となります。
- MoE (Mixture-of-Experts): モデル内に複数の専門家(エキスパート)ネットワークを持ち、入力に応じて関連性の高いエキスパートを選択的に活性化させる技術です。モデルのパラメータ数を大幅に増やしながら、推論時の計算量を抑えることができます。Qwen3では、負荷分散のための損失関数などが工夫されています。
- GQA (Grouped Query Attention): Multi-Head Attentionの変種で、クエリ(Q)ヘッドを複数のグループに分け、各グループでキー(K)とバリュー(V)ヘッドを共有します。これにより、Attention計算に必要なKVキャッシュのサイズを削減し、推論速度とメモリ効率を向上させます。
- LayerNorm (Layer Normalization): ニューラルネットワークの層ごとに入力を正規化する手法です。訓練を安定させ、収束を早める効果があります。Qwen3ではqk layernormという特定の形式が採用されている可能性がありますが、詳細な構造は公開情報からは判断できません。Attention機構内のQおよびKベクトルに適用されるLayerNormである可能性が考えられます。
- CoT (Chain-of-Thought): 複雑な推論問題を解く際に、最終的な答えだけでなく、思考の連鎖(中間的な推論ステップ)も生成させる手法です。これにより、モデルはより複雑な問題を段階的に解く能力を獲得します。Qwen3のポストトレーニングでは、このCoTデータを活用して推論能力を初期化・強化しています。
- RL (Reinforcement Learning): 強化学習は、エージェントが環境と相互作用しながら、報酬を最大化するように行動を学習する機械学習の手法です。LLMの文脈では、生成された応答の品質(指示追従性、安全性、有用性など)を報酬として与え、モデルの応答生成方策を改善するために用いられます (RLHF: Reinforcement Learning from Human Feedback が有名ですが、Qwen3ではルールベースの報酬も使用)。
モデルアーキテクチャとラインナップ
Qwen3モデルは、Transformerアーキテクチャに基づいており、自己注意機構(Self-Attention)とフィードフォワードネットワーク(FFN)を組み合わせた構造を持っています。Qwen3-8Bのデフォルト設定では、ボキャブラリサイズは151,936、隠れ層のサイズは4,096、中間層のサイズは22,016、隠れ層の数は32、アテンションヘッド数は32となっています。
MoEモデルの特徴は、パラメータの総数と活性化されるパラメータの数が異なることです。例えば、Qwen3-235B-A22Bは総パラメータ数が235Bであるのに対し、活性化されるパラメータは22Bのみです。このアプローチにより、大規模なモデルサイズを維持しながら、計算効率の向上を実現しています。Qwen3のMoEベースモデルは、活性パラメータが10%に過ぎないにもかかわらず、Qwen2.5の密なベースモデルと同等の性能を達成しており、トレーニングと推論の両方のコストを大幅に削減しています。
モデルアーキテクチャの改良点として、MoEレイヤーでは複数のFFNを組み込んでおり、各FFNが個別のエキスパートとして機能します。また、エキスパートルーティングメカニズムは、共有エキスパートとルーティング固有のエキスパートの両方を統合するアプローチを採用しており、これにより様々なタスクに対応できる共有エキスパートと、特定のルーティングシナリオ用に予約された専用エキスパートを持つことが可能になっています。
Qwen3は、多様なニーズに応えるために、DenseモデルとMoE (Mixture-of-Experts)モデルの両方を提供しています。
- Denseモデル: 0.6B, 1.7B, 4B, 8B, 14B, 32Bのパラメータサイズがあります。これらのモデルは、従来のLLMと同様に、すべてのパラメータが計算に関与します。
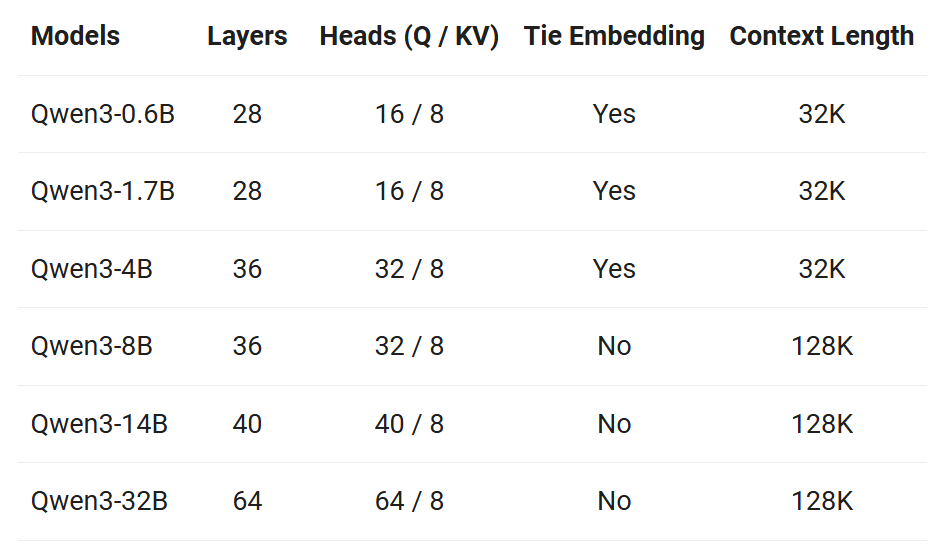
- MoEモデル: 30B-A3B (総パラメータ30B, 活性化パラメータ3B) と 235B-A22B (総パラメータ235B, 活性化パラメータ22B) があります。MoEは、入力に応じて特定の「エキスパート」ネットワークを選択的に活性化させるアーキテクチャです。これにより、総パラメータ数を増やしながらも、推論時の計算コスト(活性化パラメータ数)を抑えることができます。

事前学習プロセス
Qwen3の事前学習は、質と量の両面で大幅に強化され、以下の3段階で構成されています。
- ステージ1 (基盤構築): 30兆トークン以上のデータと4Kのコンテキスト長で学習し、基本的な言語能力と一般知識を獲得します。
- ステージ2 (専門知識強化): STEM、コーディング、推論タスクなどの知識集約型データの比率を高めたデータセット(追加5兆トークン)で学習し、専門分野の能力を向上させます。
- ステージ3 (長文対応): 高品質な長文コンテキストデータを用いて、コンテキスト長を最大32K (小型モデル) または128K (大型モデル) まで拡張し、長文入力への対応能力を高めます。
訓練データは、ウェブデータに加え、PDF様式の文書からも収集されました。その際、Qwen2.5-VL (Vision-Languageモデル) を用いてテキストを抽出し、Qwen2.5で品質を向上させています。さらに、数学やコードデータの量を増やすために、Qwen2.5-MathやQwen2.5-Coderを用いて教科書、質疑応答ペア、コードスニペットなどの合成データも生成されました。
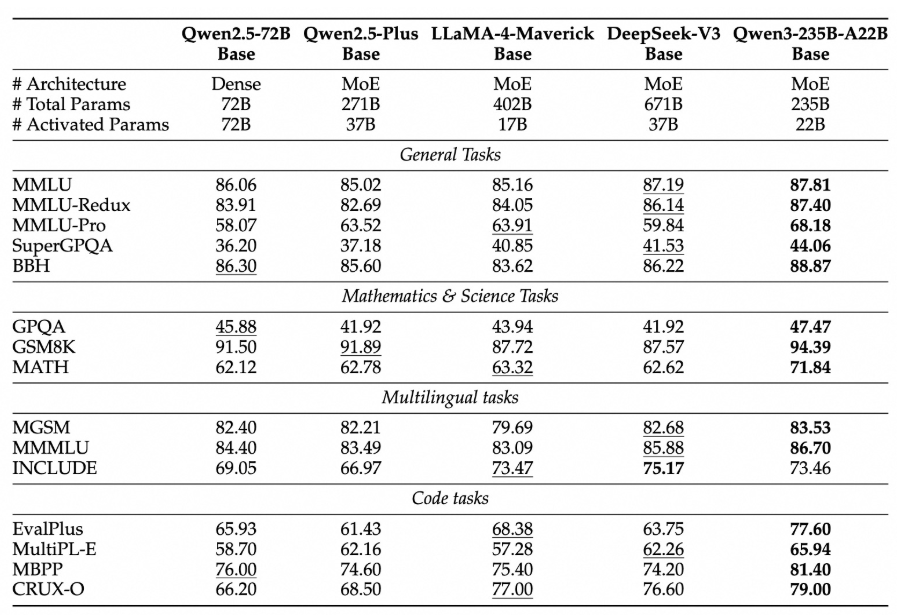
また、スケーリング則(Scaling Law)に基づいた広範な研究を通じて、学習率スケジューラやバッチサイズなどの重要なハイパーパラメータが、DenseモデルとMoEモデルそれぞれに対して体系的に調整されました。これにより、異なるモデルスケールでの訓練ダイナミクスと最終的な性能が最適化されています。結果として、Qwen3のDense Baseモデルは、より多くのパラメータを持つQwen2.5 Baseモデルと同等の性能を達成し、特にSTEM、コーディング、推論の分野では上回る性能を示しています。Qwen3 MoE Baseモデルは、Qwen2.5 Dense Baseモデルと同等の性能を、わずか10%の活性化パラメータで達成し、訓練と推論コストの大幅な削減を実現しています。
ポストトレーニングとハイブリッド思考モード
Qwen3のInstruction-tunedモデル(例: Qwen3-30B-A3B)は、独自のハイブリッド思考モードを実現するために、以下の4段階のポストトレーニングパイプラインを経ています。
- Long CoT Cold Start: 多様なタスク(数学、コーディング、論理推論、STEMなど)にわたる長文のChain-of-Thought (CoT)データを用いてファインチューニングし、基本的な推論能力を獲得します。
- Reasoning RL: 計算リソースをスケールアップした強化学習 (RL) を行い、ルールベースの報酬を用いてモデルの探索と活用能力を高めます。
- Thinking Mode Fusion: ステージ2で強化された思考モデルが生成した長文CoTデータと一般的な指示チューニングデータを組み合わせてファインチューニングし、「思考モード」と「非思考モード」(迅速応答)の能力を融合させます。
- General RL: 20以上の一般ドメインタスク(指示追従、フォーマット追従、エージェント能力など)で強化学習を適用し、モデルの汎用能力をさらに強化し、望ましくない振る舞いを修正します。
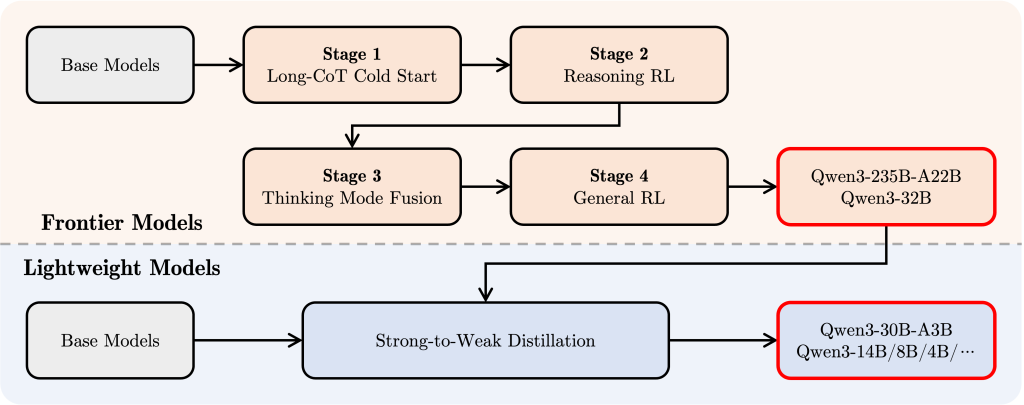
このパイプラインにより、Qwen3はユーザーがタスクの複雑さに応じて思考プロセスを制御できるハイブリッド思考モードを獲得しました。
- 思考モード (enable_thinking=True): デフォルトのモード。複雑な問題に対し、内部的に段階的な推論(思考プロセス)を実行してから最終的な回答を生成します。思考プロセスは <think>…</think> タグで囲まれて出力されることがあります(実装による)。
- 非思考モード (enable_thinking=False): 簡単な質問に対し、推論ステップを経ずに迅速に回答を生成します。
この柔軟性により、ユーザーは計算コストと応答品質のバランスを最適化できます。思考モードでは、割り当てられた計算(思考)予算に応じて性能がスケーラブルに向上することが示されています。
マルチリンガル能力とコンテキスト長
Qwen3は119言語と方言をサポートしており、国際的なアプリケーションのための新たな可能性を開きます。これにより、世界中のユーザーがこれらのモデルのパワーを活用できるようになります。
コンテキスト長に関しては、Qwen3は標準で32,768トークン、YaRNを使用すると131,072トークンまでサポートしています。これにより、長文の処理や複雑な対話が可能になります。
エージェント機能
Qwen3はエージェント機能に優れており、思考モードと非思考モードの両方で外部ツールとの正確な統合を可能にし、複雑なエージェントベースのタスクでオープンソースモデルの中でトップクラスのパフォーマンスを達成しています。
特にQwen-Agentを使用することで、Qwen3のエージェント能力を最大限に活用することができます。Qwen-Agentはツール呼び出しテンプレートとツール呼び出しパーサーを内部にカプセル化し、コーディングの複雑さを大幅に軽減します。
推論フレームワーク
また、推論フレームワークとして、Qwen3は以下をサポートしています:
- Hugging Face Transformers
- VLLM
- llama.cpp
- mlx-lm(Apple Silicon向け)
- Ollama
- LMStudio
モデルのベンチマーク性能
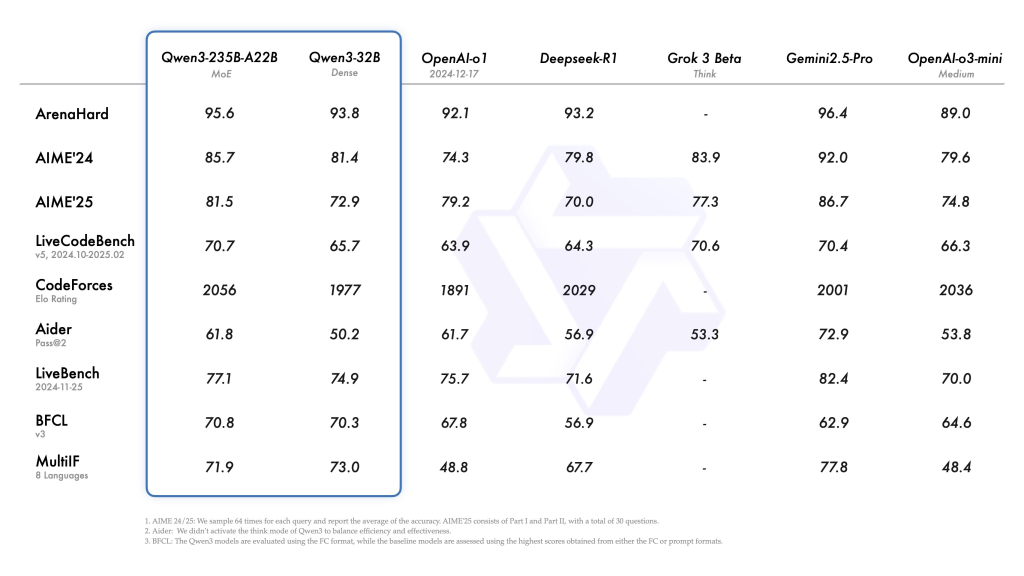
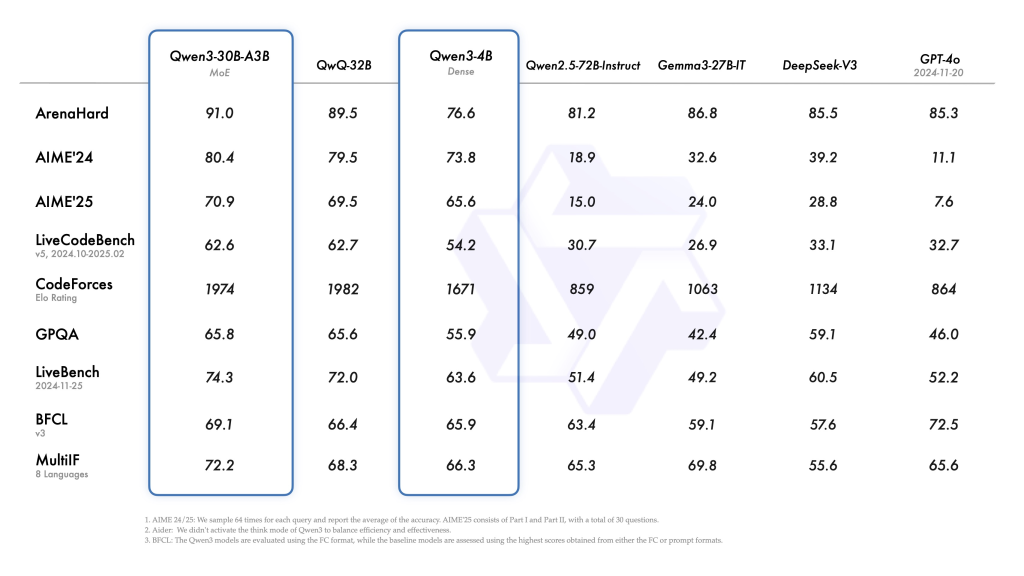
Qwen3シリーズは多くのベンチマークテストで優れた性能を示しています。特に注目すべきは、4Bの密なモデルがGPT-4やDeepSeek V3などの大規模モデルと同じテーブルで競争力を持つことです。
Alibaba Cloudによって引用されたベンチマークテストによれば、Qwen3-235BやQwen3-4Bなどのモデルは、OpenAIのo1、GoogleのGemini、DeepSeekのR1などの国内外の競合他社の高度なモデルに匹敵するか、それを上回るパフォーマンスを発揮しています。特に指示に従う能力、コーディング支援、テキスト生成、数学的スキル、複雑な問題解決の分野で優れた成績を示しています。
実装例 (Hugging Face Transformers)
以下に、Hugging Faceのtransformersライブラリを使用してQwen3モデル(例: Qwen3-30B-A3B)を利用する基本的なコードを示します。
※GoogleColab: https://colab.research.google.com/drive/1V68faX3SaCNihzxS2Yu7Xa5ZZySErjma?usp=sharing
# -*- coding: utf-8 -*-
# 必要なライブラリをインストールします
# 'accelerate' は 'device_map="auto"' を使う際に推奨されます
!pip install transformers torch accelerate sentencepiece -q
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# --- 設定 ---
# Google Colab無料版で動作する可能性のある比較的小さなモデルを選択します
# より高性能なGPUが割り当てられた場合、'Qwen/Qwen3-4B' や 'Qwen/Qwen3-8B' も試せる可能性がありますが、
# メモリ不足になるリスクがあります。
# model_name = "Qwen/Qwen3-0.6B" # 最も軽量なモデル
model_name = "Qwen/Qwen3-1.7B"
# model_name = "Qwen/Qwen3-4B" # Colab ProやGPUによっては動作可能
# model_name = "Qwen/Qwen3-8B" # Colab Proや高性能GPUが必要な可能性が高い
# --- モデルとトークナイザのロード ---
print(f"'{model_name}' のモデルとトークナイザをロードしています...")
# トークナイザをロード
tokenizer = AutoTokenizer.from_pretrained(model_name)
# モデルをロード
# torch_dtype="auto" : モデルに適したデータ型 (例: bfloat16) を自動選択し、メモリ使用量を削減
# device_map="auto" : 利用可能なデバイス (GPUがあればGPU、なければCPU) にモデルを自動で配置
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
print("モデルとトークナイザのロードが完了しました。")
print(f"モデルは {model.device} で実行されます。") # モデルがどのデバイスで実行されるか確認
# --- 推論の実行 ---
# プロンプト (質問や指示) を設定
prompt = "大規模言語モデルについて簡単に紹介してください。"
# prompt = "日本の首都はどこですか?"
# prompt = "簡単なPythonコードを書いてください。内容はリスト内の数字を合計するものです。"
# チャット形式の入力を作成
messages = [
{"role": "user", "content": prompt}
]
# チャットテンプレートを適用
# enable_thinking=True (デフォルト): モデルは応答前に内部的な思考プロセスを実行する可能性があります (複雑なタスク向け)
# enable_thinking=False : モデルは思考プロセスを実行せず、より迅速に応答します (簡単なタスク向け)
# add_generation_prompt=True : モデルが応答を生成しやすいように、テンプレートに特別なトークンを追加します
use_thinking_mode = True # True または False に設定
print(f"思考モード: {'有効' if use_thinking_mode else '無効'}")
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=use_thinking_mode
)
# 入力テキストをトークン化し、モデルと同じデバイスに送信
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# テキスト生成を実行
# max_new_tokens: 生成する最大トークン数。長くすると応答も長くなるが、時間とメモリも消費する
# その他のパラメータ (temperature, top_k, top_p など) で生成の多様性を調整可能
print("テキスト生成を開始します...")
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512 # 必要に応じて調整してください
# temperature=0.7, # 例: 少し多様性を加える場合
# top_k=50,
# top_p=0.95,
)
print("テキスト生成が完了しました。")
# 入力部分を除いた、生成されたトークンIDを取得
# generated_ids[0] はバッチの最初の要素 (今回はバッチサイズ1)
# len(model_inputs.input_ids[0]) は入力トークンの長さ
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# --- 結果の表示 ---
# 生成されたトークンIDをデコードしてテキストに戻す
# skip_special_tokens=True で特殊トークン (例: <|endoftext|>) を除去
# 思考モードが有効な場合、思考コンテンツと最終応答を分離する試み
# </think> トークンのIDはモデルやバージョンによって異なる可能性があるため注意 (Qwen3では 151668 とドキュメントに記載あり)
think_token_id = 151668
thinking_content = ""
final_content = ""
if use_thinking_mode:
try:
# 応答トークンリストの末尾から </think> トークンを探す
think_end_index_from_end = output_ids[::-1].index(think_token_id)
# 応答トークンリストの先頭からの </think> トークンのインデックス
think_end_index = len(output_ids) - 1 - think_end_index_from_end
# 思考コンテンツ部分をデコード
thinking_content = tokenizer.decode(output_ids[:think_end_index], skip_special_tokens=True).strip()
# 最終応答部分をデコード (</think> の次のトークンから)
final_content = tokenizer.decode(output_ids[think_end_index + 1:], skip_special_tokens=True).strip()
# <think> タグ自体も除去したい場合 (より確実な方法)
# full_response_with_tags = tokenizer.decode(output_ids, skip_special_tokens=False)
# think_tag_start = "<think>"
# think_tag_end = "</think>"
# start_idx = full_response_with_tags.find(think_tag_start)
# end_idx = full_response_with_tags.find(think_tag_end)
# if start_idx != -1 and end_idx != -1:
# thinking_content = full_response_with_tags[start_idx + len(think_tag_start):end_idx].strip()
# final_content = full_response_with_tags[end_idx + len(think_tag_end):].strip()
# else: # タグが見つからない場合は、全体を最終応答とする
# final_content = tokenizer.decode(output_ids, skip_special_tokens=True).strip()
except ValueError:
# </think> トークンが見つからなかった場合 (思考しなかったか、形式が異なる場合)
print("</think> タグが見つかりませんでした。応答全体を表示します。")
final_content = tokenizer.decode(output_ids, skip_special_tokens=True).strip()
else:
# 非思考モードの場合は、全体が最終応答
final_content = tokenizer.decode(output_ids, skip_special_tokens=True).strip()
# 結果を出力
print("\n--- 生成結果 ---")
if thinking_content:
print("\n[思考プロセス]:")
print(thinking_content)
print("\n[最終応答]:")
print(final_content)
# --- (オプション) メモリの解放 ---
# del model
# del tokenizer
# torch.cuda.empty_cache() # GPUメモリをクリアする場合
# print("モデルとトークナイザをメモリから解放しました。")
最適なパフォーマンスを得るためには、以下の設定が推奨されています:
- 思考モード(enable_thinking=True)では、Temperature=0.6、TopP=0.95、TopK=20、MinP=0を使用します。Greedy decodingは使用しないでください。パフォーマンスの低下や無限の繰り返しにつながる可能性があります。
- 非思考モード(enable_thinking=False)では、Temperature=0.7、TopP=0.8、TopK=20、MinP=0を使用することをお勧めします
まとめ
本稿では、最新の大規模言語モデルQwen3について、その技術的な特徴と進化点を解説しました。大規模かつ高品質な多言語データセットによる事前学習、DenseモデルとMoEモデルの提供、3段階の事前学習と4段階のポストトレーニング、そしてハイブリッド思考モードの実装など、多くの技術的進歩が見られます。特に、MoEモデルによる効率的な性能向上や、思考モードによる高度な推論能力と制御可能性は、今後のLLM開発における重要な方向性を示唆しています。
Qwen3は、Hugging Face、ModelScope、GitHubなどを通じて広く公開されており、Apache 2.0ライセンスの下で利用可能です。transformersライブラリやvLLM, SGLang, Ollamaなどのフレームワークを用いることで、比較的容易に導入・評価・応用が可能です。AIエンジニアの皆様にとって、Qwen3は研究開発やサービス構築において強力なツールとなるでしょう。今後のさらなる発展にも期待が高まります。