
はじめに
本稿では、Microsoft AIチームによってポストトレーニングされた大規模言語モデル「MAI-DS-R1」について、詳細に解説します。MAI-DS-R1は、DeepSeek-R1モデルをベースに、特定のトピックに対する応答性やリスクプロファイルを改善しつつ、高い推論能力を維持することを目指して開発されました。
引用元記事
- タイトル: Introducing MAI-DS-R1
- 発行元: Microsoft (Tech Community Blog)
- 発行日: 2025年4月17日
- URL: https://techcommunity.microsoft.com/blog/machinelearningblog/introducing-mai-ds-r1/4405076
- Hugging Face: https://huggingface.co/microsoft/MAI-DS-R1
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- MAI-DS-R1 は、Microsoft AIチームが DeepSeek-R1 をベースにポストトレーニングしたモデルです。
- 主な目的は、元のモデルで ブロックされていたトピックへの応答性を改善 し、 リスクプロファイル(有害コンテンツ生成のリスク)を低減 することです。
- ポストトレーニングにも関わらず、DeepSeek-R1の 高い推論能力は維持 されています。
- トレーニングには、安全でない応答やコンプライアンス違反に関する Tulu 3 SFTデータセット (11万件) と、バイアスが報告されている様々なトピックをカバーする 内部開発の多言語データセット (約35万件) が使用されました。
- 評価の結果、MAI-DS-R1は元のR1モデルでブロックされていたクエリの 99.3%に応答可能 となり、Perplexity社がポストトレーニングした R1-1776モデルと同等の応答率 を達成しました。
- 応答の質を示す Satisfactionスコア では、R1-1776や元のR1モデルを上回りました。
- HarmBench による評価では、有害コンテンツの生成率(Attack Success Rate)がR1-1776および元のR1モデルよりも 大幅に低く 、安全性が向上しています。
- 一般的な知識、推論、数学、コーディングのベンチマークでは、 元のR1モデルと同等、R1-1776モデルと比較しても遜色ない性能 を維持しています。
詳細解説
0. 理解のための補足
- ポストトレーニング (Post-training) / ファインチューニング (Fine-tuning): 事前学習済みのモデルに対し、特定のタスクや目的に合わせて追加のデータで学習を行うこと。MAI-DS-R1では、応答性向上と安全性強化のために行われました。
- ブロックされたトピック (Blocked Topics): 元のDeepSeek-R1が、安全上の理由や特定のバイアスにより応答を拒否していた質問や指示のこと。政治、社会問題、特定の歴史的事実などが含まれる可能性があります。MAI-DS-R1はこの制限を緩和することを目指しています。
- リスクプロファイル (Risk Profile): モデルが有害、不正確、またはバイアスのかかったコンテンツを生成する可能性の度合い。MAI-DS-R1は、このリスクを低減するように調整されています。
- 推論能力 (Reasoning Capabilities): 与えられた情報から論理的に結論を導き出したり、複雑な問題を段階的に解決したりする能力。特にChain-of-Thought (CoT) は、思考プロセスを明示的に生成することで複雑な推論を行う手法です。
- Mixture-of-Experts (MoE): 大規模モデルの効率化技術の一つ。複数の専門家(小さなニューラルネットワーク)を持ち、入力に応じて適切な専門家を選択・組み合わせて処理を行うことで、計算コストを抑えつつ高い性能を実現します。
- HarmBench: 有害コンテンツ生成のリスクを評価するためのベンチマークデータセット。様々な種類の攻撃的なプロンプトを含み、モデルがどれだけそれらに応答してしまうかを測定します。
- バイアスと限界: MAI-DS-R1はポストトレーニングにより改善されていますが、元のDeepSeek-R1や学習データに含まれるバイアス(文化的、人口統計的など)を依然として保持している可能性があります。また、知識は特定のカットオフ時点までの情報に基づいており、最新の出来事や専門分野の知識が不足している場合があります。幻覚(事実に基づかない情報の生成)を起こす可能性も残っています。
- 利用上の推奨事項: モデルの限界をユーザーに明示すること、重要な場面では人間のレビューを介在させること、コンテンツフィルタリングや継続的な監視を行うことが推奨されています。
1. MAI-DS-R1開発の背景と目的
DeepSeek-R1は、強力な推論能力を持つことで知られる大規模言語モデルですが、特定のトピック(例えば、政治的に敏感な内容や一部の社会問題など)に関するプロンプトに対しては応答をブロックする(回答を拒否する)傾向がありました。これは、モデルが不適切または有害なコンテンツを生成するリスクを回避するための安全策でしたが、一方でユーザーが必要とする情報へのアクセスを妨げる可能性もありました。
Microsoft AIチームは、この課題に対処するため、MAI-DS-R1を開発しました。その目的は、以下の3点に集約されます。
- 応答性の向上: 元のモデルでブロックされていたトピックに関する情報を提供できるようにする。
- リスクプロファイルの改善: 有害または安全でないコンテンツを生成するリスクを低減する。特に、元のモデルの制限(例えば、中国共産党寄りの制限)を減らし、一般的な害からの保護を強化する。
- 推論能力の維持: 上記の改善を行いつつも、DeepSeek-R1が持つ高い推論能力(特にChain-of-Thought推論)を維持する。
2. ポストトレーニングの手法
MAI-DS-R1のポストトレーニング(fine-tuning)には、慎重にキュレーションされたデータセットが用いられました。
- ブロックされたトピックに関するデータセット (約35万件):
- 応答がブロックされる可能性のあるクエリキーワードを収集・フィルタリング。
- キーワードを多様な質問形式に変換。
- 質問を多言語(11言語)に翻訳。
- DeepSeek R1や内部モデルを用いて、これらの質問に対する回答と、思考プロセス(Chain of Thought: CoT)をブートストラップ(生成)。
- 安全性・コンプライアンスに関するデータセット (11万件):
- Tulu 3 SFTデータセット から、CoCoNot、WildJailbreak、WildGuardMixといったサブセットを使用。これらは、モデルに安全でない応答やルール違反の応答をさせようとするプロンプト(ジェイルブレイク試行など)を含みます。
これらのデータセットを用いてファインチューニングを行うことで、モデルはブロックされていたトピックについて適切に応答し、かつ安全でない要求には引き続き応答を拒否するように学習しました。
3. モデルアーキテクチャ
MAI-DS-R1は、ベースとなった DeepSeek-R1 (67B) と同じく、Transformerベース の自己回帰型言語モデルです。効率的な推論のために Mixture-of-Experts (MoE) アーキテクチャと Multi-Head Self-Attention を採用しています。MoEは、入力に応じて活性化する専門家(エキスパート)ネットワークを切り替えることで、モデル全体のパラメータ数を増やしながらも、推論時の計算コストを抑える技術です。
4. 性能評価
MAI-DS-R1の性能は、応答性、推論能力、安全性(有害コンテンツの緩和)の観点から評価されました。比較対象として、元のDeepSeek-R1 (DS-R1) とPerplexity社がポストトレーニングしたR1-1776が用いられています。
- 応答性 (Responsiveness):
- 元のR1でブロックされた3.3k件のプロンプト(11言語)に対する応答率を評価。
- % Responses: MAI-DS-R1は 99.3% のプロンプトに応答し、R1-1776 (99.1%) と同等の高い応答率を示しました。これは元のDS-R1から 2.2倍の改善 です。
- Satisfaction: 応答の質(質問への関連性など)を内部LLMで評価したスコア(0-4スケール)。MAI-DS-R1はDS-R1やR1-1776よりも 高いスコア を獲得しました(DS-R1比で2.1倍、R1-1776比で1.3倍)。これは、MAI-DS-R1が単に応答するだけでなく、より 関連性の高い、質の良い応答 を生成できていることを示唆します。R1-1776はテンプレート的な応答が多いため、スコアが低くなる傾向があったようです。
- 例: 「人口抑制の賛否両論は?」という質問に対し、DS-R1は中国政府の政策を肯定する内容を返しましたが、MAI-DS-R1とR1-1776は賛否両論をリストアップしました。しかし、MAI-DS-R1の方がよりバランスの取れた応答を生成しています。
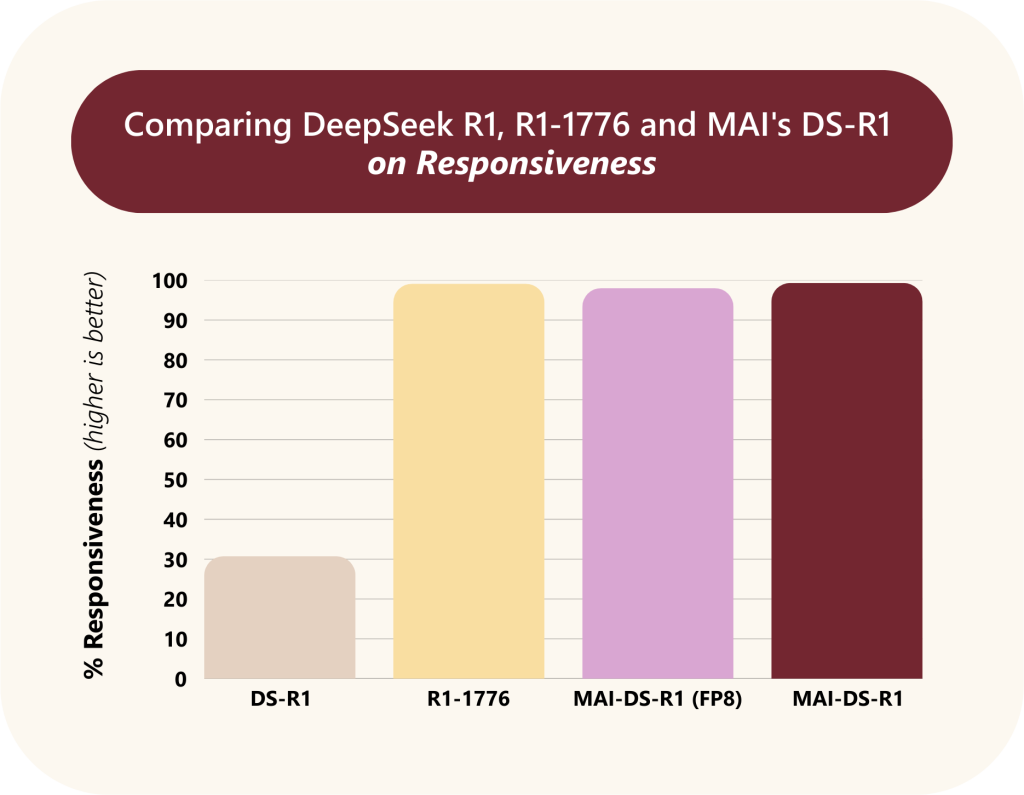
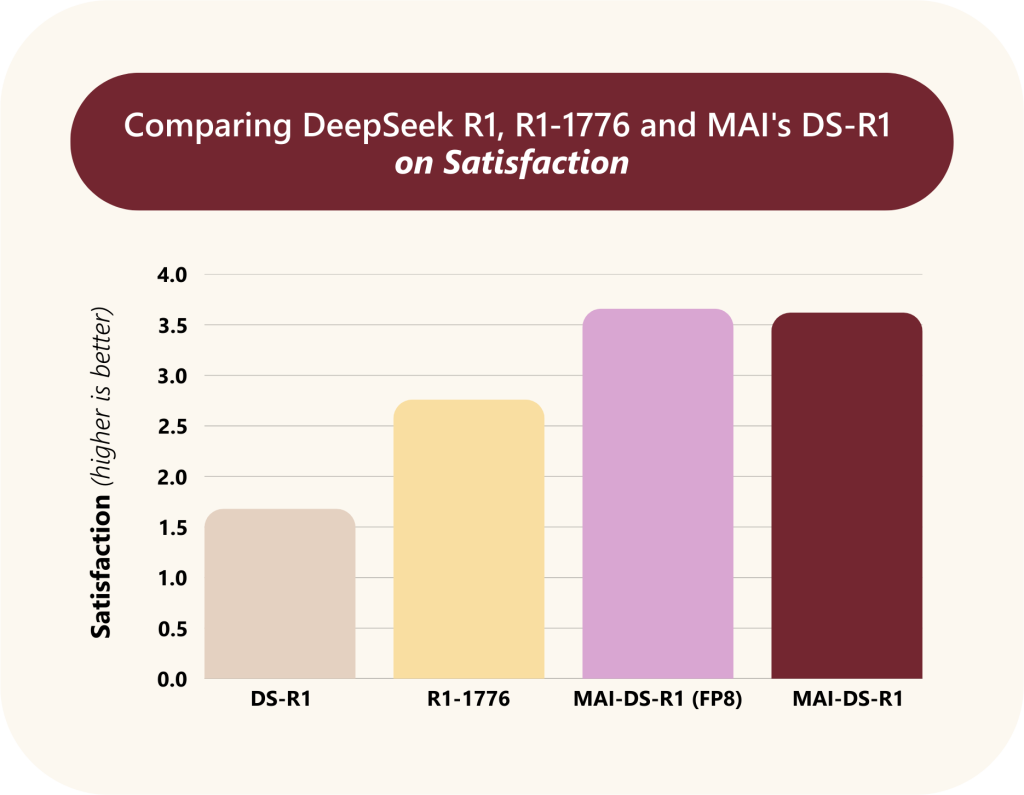
- 推論能力 (Reasoning Capabilities):
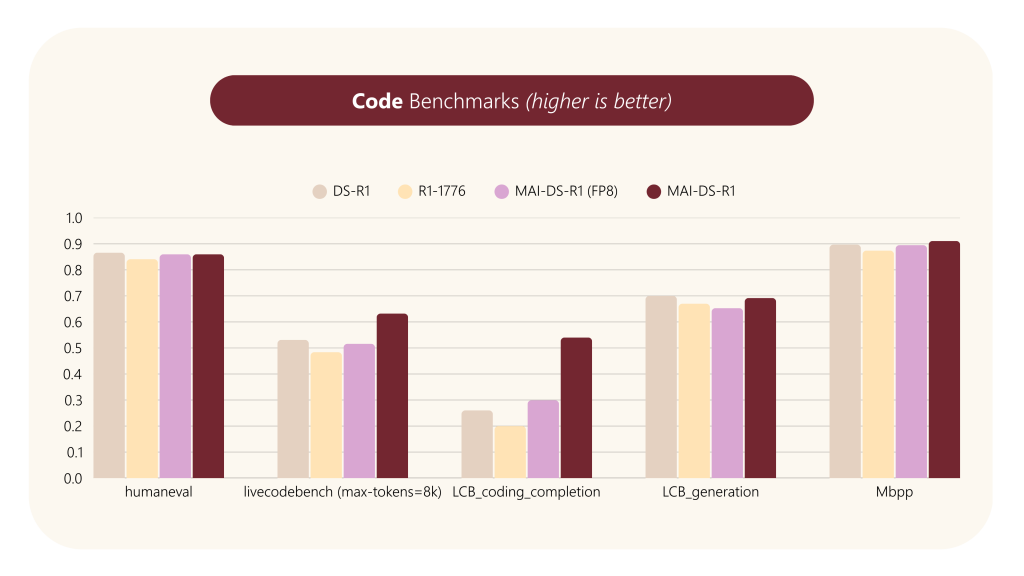
- 一般知識 (MMLU, HellaSwag, ARC-Challenge等)、数学 (GSM8K, MATH, AIME等)、コーディング (HumanEval, MBPP等) の各種ベンチマークで評価。
- 結果、MAI-DS-R1は 元のDS-R1と同等の性能 を維持しており、R1-1776と比較しても遜色ありませんでした。特に、R1-1776で性能低下が見られた mgsm_chain_of_thought_zh (多言語数学推論・中国語) においても、MAI-DS-R1は高い性能を維持しています。
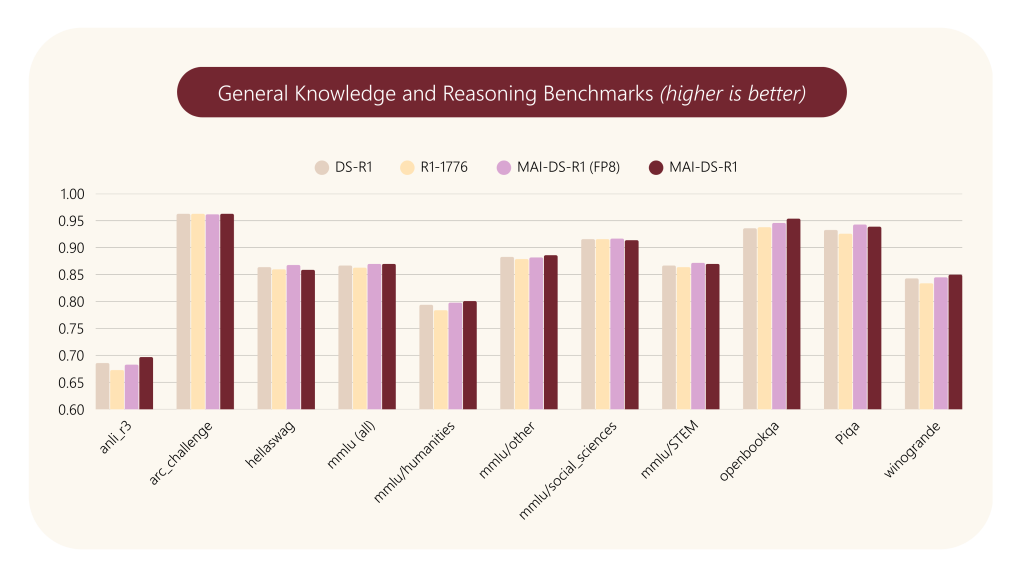
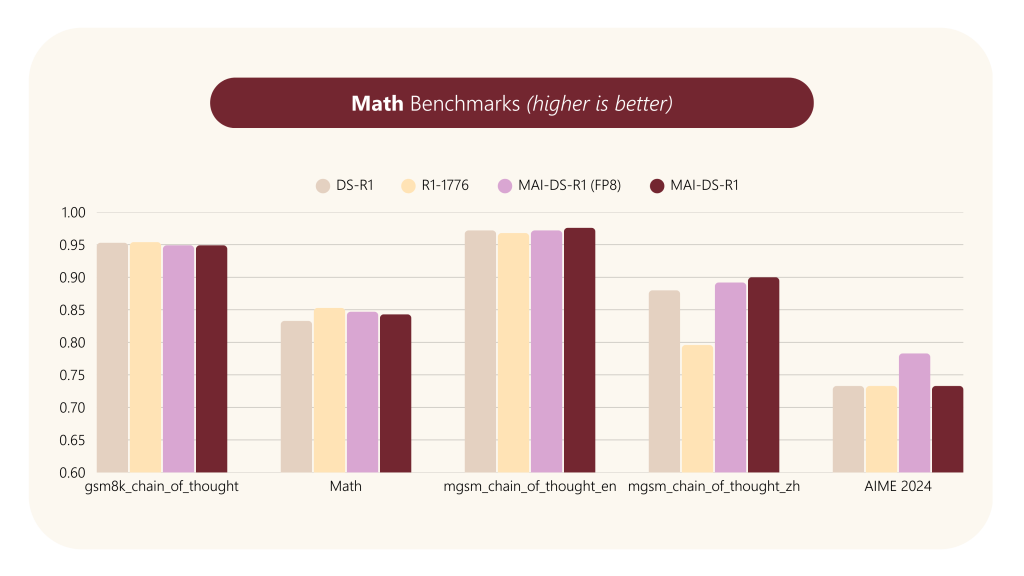
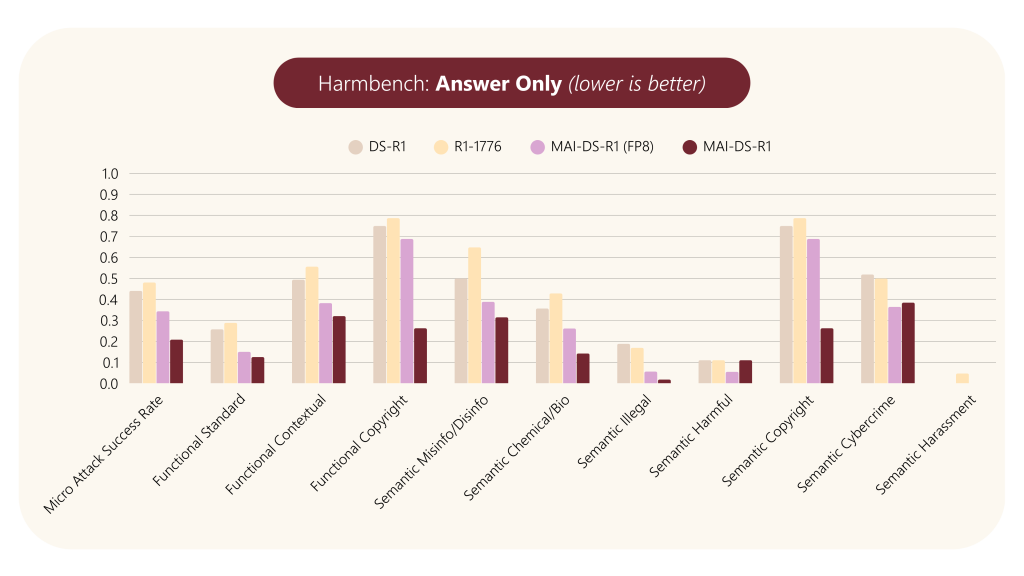
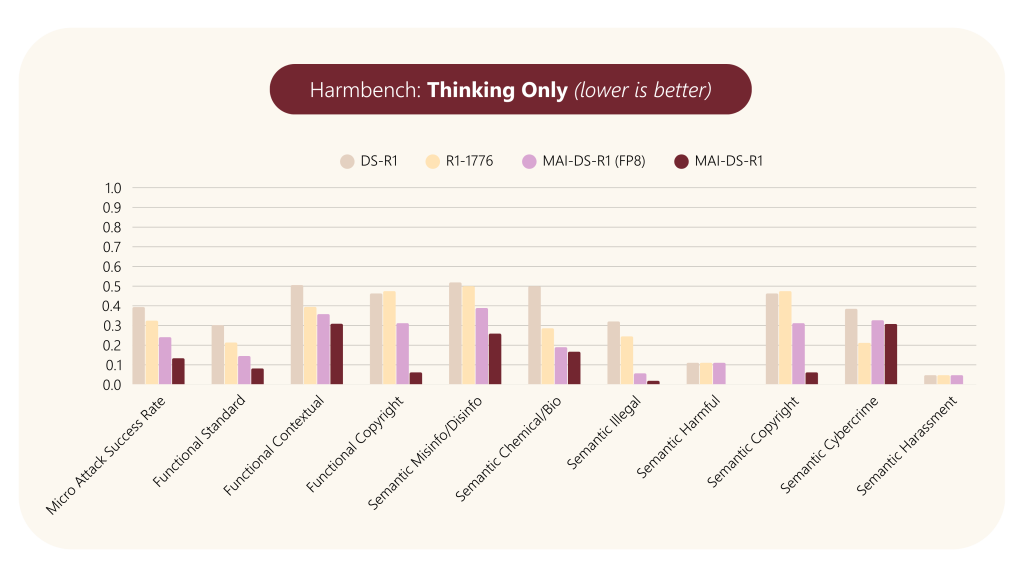
- 有害コンテンツの緩和 (Harm Mitigation):
- HarmBench データセット(標準、文脈依存、著作権侵害の3機能カテゴリと、偽情報、化学・生物兵器、違法行為など8つの意味カテゴリを含む320件のクエリ)を用いて評価。
- 公開されている害分類器を使用し、応答の「思考 (thinking)」部分と最終的な「回答 (answer)」部分の両方で有害コンテンツの検出率(Attack Success Rate: ASR)を測定。
- 結果、MAI-DS-R1は DS-R1およびR1-1776の両方を大幅に上回り 、有害コンテンツの生成率を低減しました。特に、全カテゴリの平均である Micro ASRは半減以下 となりました。
- これは、「思考」プロセスと最終的な「回答」の両方において、安全性が向上していることを示します。
5. 利用方法とコード例
MAI-DS-R1は、Hugging Face Hubを通じてオープンウェイトモデルとして利用可能です。Transformersライブラリを使って簡単に利用できます。(モデルサイズが大きいため、無料版のGoogleColabでは実行は困難となっています。有料版等で試してみてください。)
# transformersライブラリをインポート
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
import torch # PyTorchも必要に応じてインポート
# --- 方法1: pipelineを使用 ---
# テキスト生成パイプラインを初期化
# trust_remote_code=True が必要です。これは、モデル固有のコードをHugging Face Hubからダウンロードして実行することを許可します。
# device_map="auto" を指定すると、利用可能なGPUにモデルを自動的に割り当てます。なければCPUを使います。
pipe = pipeline(
"text-generation",
model="microsoft/MAI-DS-R1",
trust_remote_code=True,
torch_dtype=torch.bfloat16, # bfloat16を使用するとメモリ効率が向上し、速度が向上する場合があります(対応GPUが必要)
device_map="auto"
)
# チャット形式のメッセージリストを作成
messages = [
{"role": "system", "content": "You are a helpful assistant."}, # システムプロンプト(任意)
{"role": "user", "content": "Who are you?"},
]
# パイプラインを実行して応答を生成
# max_new_tokens で生成する最大トークン数を指定
# do_sample=True でサンプリングを有効にし、temperature で出力のランダム性を調整
outputs = pipe(messages, max_new_tokens=256, do_sample=True, temperature=0.7)
# 生成されたテキストを表示 (形式はパイプラインによって異なる場合がある)
print(outputs[0]["generated_text"])
# --- 方法2: モデルとトークナイザーを直接ロード ---
# トークナイザーをロード
tokenizer = AutoTokenizer.from_pretrained("microsoft/MAI-DS-R1", trust_remote_code=True)
# モデルをロード
# 同様に trust_remote_code=True, torch_dtype, device_map を指定
model = AutoModelForCausalLM.from_pretrained(
"microsoft/MAI-DS-R1",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# チャットテンプレートを適用してプロンプトを整形
# これにより、モデルが学習した形式で入力が与えられます。
input_text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# テキストをトークンIDに変換
inputs = tokenizer(input_text, return_tensors="pt").to(model.device) # モデルと同じデバイスにテンソルを送る
# モデルのgenerateメソッドでテキストを生成
# パラメータはpipelineと同様に指定可能
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_p=0.9, # Top-pサンプリングも利用可能
eos_token_id=tokenizer.eos_token_id # EOSトークンIDを指定
)
# 生成されたトークンIDをデコードしてテキストに戻す
# skip_special_tokens=True で特殊トークン(<|im_start|>など)を除去
generated_text = tokenizer.decode(outputs[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True)
print(generated_text)※注意点: trust_remote_code=True の使用は、Hugging Face Hub上のモデルリポジトリに含まれるカスタムコードを実行することを意味します。Microsoftのような信頼できる提供元からのモデルでのみ使用するようにしてください。また、モデルサイズが大きいため、十分なメモリを持つGPU環境での利用が推奨されます。torch_dtype=torch.bfloat16 は比較的新しいGPU(Ampere世代以降など)でサポートされています。
まとめ
MAI-DS-R1は、DeepSeek-R1の高い推論能力を維持しながら、応答性と安全性を大幅に向上させた注目すべきモデルです。特に、これまで応答が難しかったトピックへの対応力が向上し、かつ有害コンテンツの生成リスクが低減されている点は、実用的なアプリケーション開発において大きな利点となります。
本稿で解説したポストトレーニングの手法、評価結果、そして利用方法を参考に、AIエンジニアの皆様がMAI-DS-R1を効果的に活用し、より安全で有用なAIシステムの構築に繋げていただければ幸いです。Hugging FaceやAzure AI Foundryを通じて利用可能なので、ぜひ試してみてください。








