はじめに
Google AIは、Gemini API、Google AI Studio、Vertex AIを通じて、Gemini 2.5 Flashの早期プレビュー版の提供を開始しました。本稿では、AIエンジニアの皆様に向けて、この新しいモデルの技術的な特徴、特に注目すべき「思考」能力とその制御について、公式ブログ「Start building with Gemini 2.5 Flash」より詳細に解説していきます。Gemini 2.0 Flashの高速性とコスト効率を維持しつつ、推論能力を大幅に向上させたGemini 2.5 Flashの可能性を探ります。
引用元情報:
- 記事タイトル: Start building with Gemini 2.5 Flash
- 発行日: 2025年4月17日
- URL: https://developers.googleblog.com/en/start-building-with-gemini-25-flash/?utm_source=deepmind.google&utm_medium=referral&utm_campaign=gdm&utm_content=
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
GoogleColab(弊社作成)
GoogleColab: https://colab.research.google.com/drive/1XT0b_QpTOq-_FKLGTRTtqGWbazusM6_L?usp=sharing
※公式Github(参考):https://github.com/google-gemini/cookbook/?tab=readme-ov-file
要点
- ハイブリッド推論モデル: Gemini 2.5 Flashは、応答生成前に「思考」プロセスを実行できる、Google初の完全なハイブリッド推論モデルです。
- 思考制御: 開発者は、モデルの「思考」のオン/オフを切り替えたり、「思考予算 (thinking budget)」を設定したりすることで、品質、コスト、レイテンシの最適なバランスを見つけることができます。
- 高性能・高コスト効率: 複雑なタスクにおいて高い推論能力を発揮し、LMArenaのHard Promptsでは2.5 Proに次ぐ性能を示しながら、他の主要モデルと比較して優れたコスト効率を実現しています。
- 柔軟な利用: 思考予算を0に設定すれば、2.0 Flashの高速性を維持しつつパフォーマンスを向上させることも可能です。
詳細解説
1. 「思考するモデル」としてのGemini 2.5 Flash
Gemini 2.5モデル群は、応答を即座に生成するのではなく、まず「思考」する能力を持つ点が特徴です。この思考プロセスにより、モデルはプロンプトをより深く理解し、複雑なタスクを分解し、応答を計画することができます。特に、数学的問題の解決や研究に関する質問の分析など、複数ステップの推論が必要なタスクにおいて、この思考プロセスはより正確で包括的な回答を導き出す上で有効です。Gemini 2.5 Flashは、この思考能力を備えた初のハイブリッド推論モデルであり、開発者がその思考プロセスを制御できる点が画期的です。
2. 思考予算 (Thinking Budget) による柔軟な制御
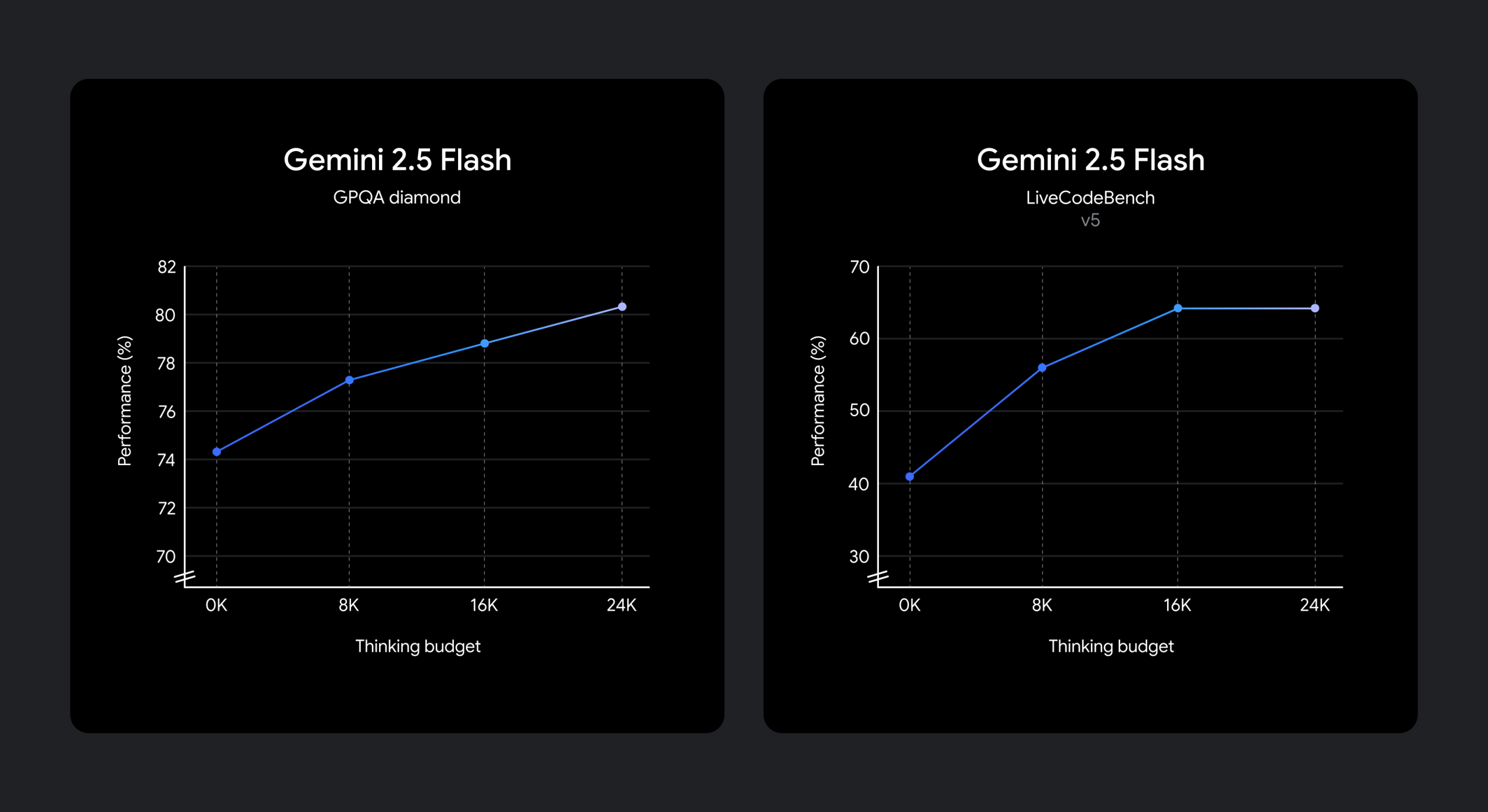
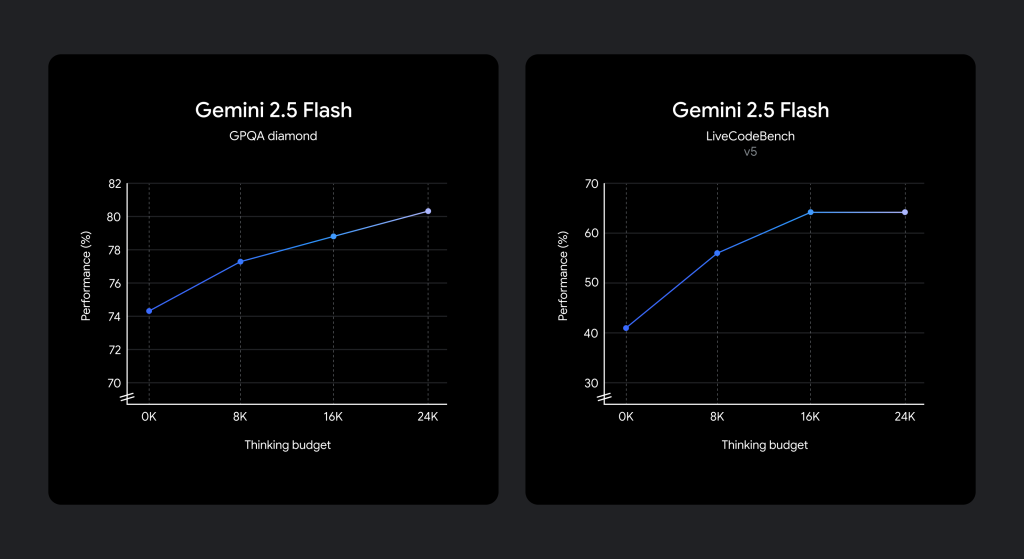
開発現場では、ユースケースに応じて品質、コスト、レイテンシのトレードオフが異なります。Gemini 2.5 Flashでは、この要求に応えるため、「思考予算 (thinking budget)」というパラメータが導入されました。
- 機能: この予算は、モデルが思考プロセス中に生成できる最大トークン数を定義します。予算を高く設定するほど、モデルはより深く推論を行い、品質を向上させることができます。
- 自動調整: 重要な点として、モデルはプロンプトに応じて必要な思考量を判断し、常に予算上限まで思考するわけではありません。タスクの複雑さに応じて、思考量を自動的に調整します。
- 設定範囲: 思考予算は0から24,576トークンの範囲で設定可能です。APIのパラメータやGoogle AI Studio、Vertex AIのスライダーで調整できます。
- 予算0の場合: 思考予算を0に設定すると、思考プロセスはオフになります。これにより、Gemini 2.0 Flashの高速性を維持しながら、モデル自体の改良によるパフォーマンス向上の恩恵を受けることができます。これは、低レイテンシが最優先される場合に有効な選択肢です。
3. 推論レベルに応じた思考量の例
モデルがデフォルトモード(思考予算が設定されていない場合)で、どの程度の思考を行うかの目安を以下に示します。
- 低い推論が必要なプロンプト:
- 例1: 「スペイン語で『ありがとう』は?」
- 例2: 「カナダにはいくつの州がありますか?」
- 中程度の推論が必要なプロンプト:
- 例1: 「2つのサイコロを振ります。合計が7になる確率は?」
- 例2: 「私のジムは月水金の9時~15時、火曜と土曜の14時~20時にバスケットボールができます。私は週5日9時~18時で働いており、平日に5時間バスケットボールをしたいです。すべてうまくいくようにスケジュールを作成してください。」
- 高い推論が必要なプロンプト:
- 例1: 「長さL=3mの片持ち梁があります。断面は長方形(幅b=0.1m、高さh=0.2m)で、鋼製(E=200 GPa)です。全長にわたって等分布荷重w=5 kN/m、自由端に点荷重P=10 kNが作用しています。最大曲げ応力(σ_max)を計算してください。」
- 例2: 「スプレッドシートのセルの値を計算する関数 evaluate_cells(cells: Dict[str, str]) -> Dict[str, float] を書いてください。各セルには、数値(例: “3”)または他のセルと +, -, *, / を使用した数式(例: “=A1 + B1 * 2″)が含まれます。要件:セル間の依存関係を解決すること。演算子の優先順位(*/が+-より先)を処理すること。循環参照を検出し、ValueError(“Cycle detected at <cell>”) を発生させること。eval() は使用せず、組み込みライブラリのみを使用すること。」
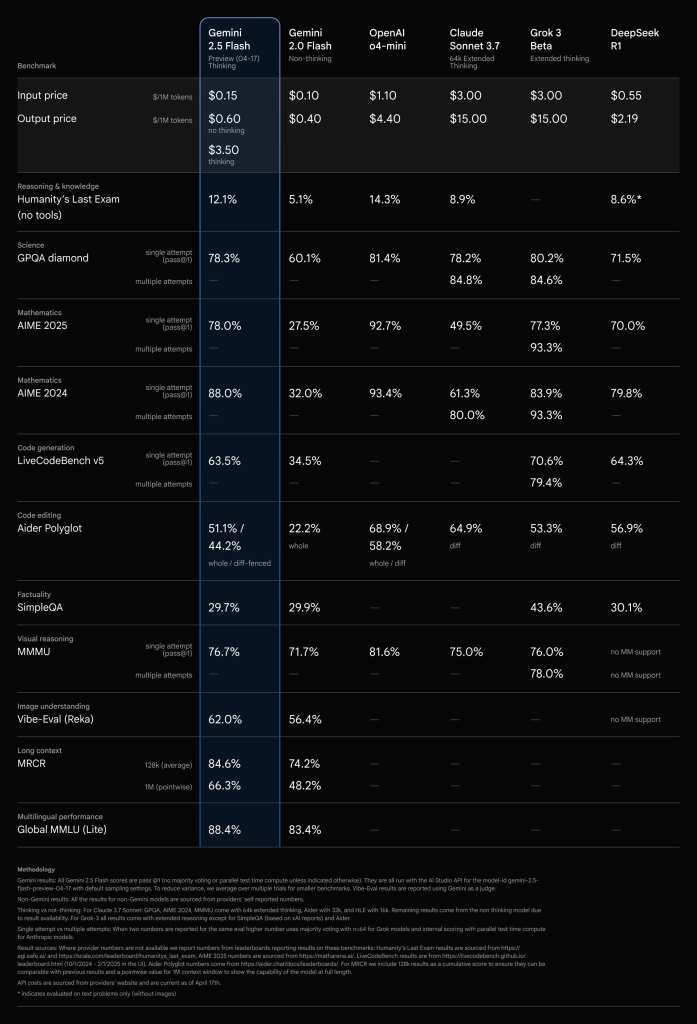
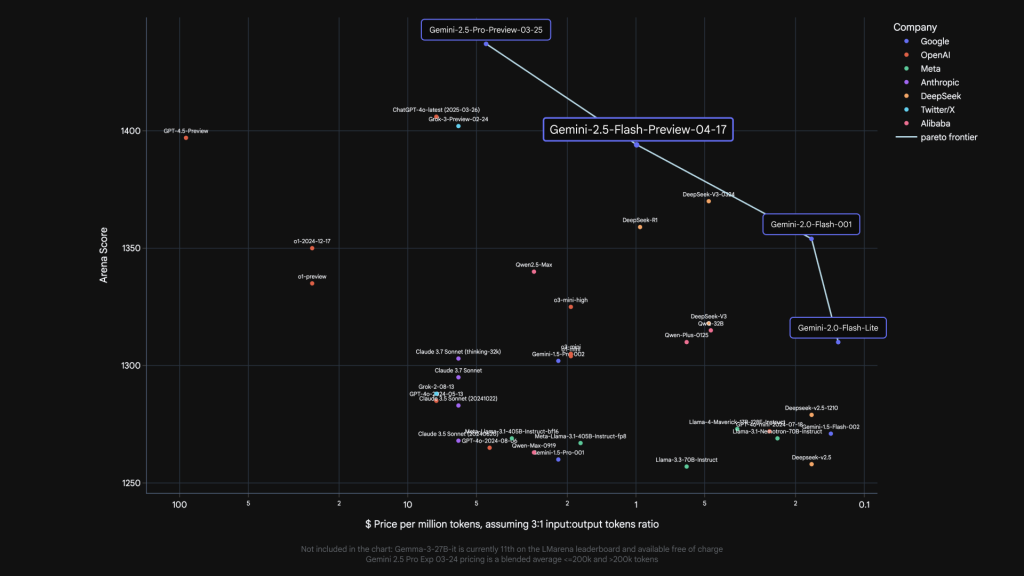
4. パフォーマンスとコスト効率
Gemini 2.5 Flashは、特に複雑な推論タスクにおいて高い性能を発揮します。LMArenaのHard Promptsでの性能は、より大規模なGemini 2.5 Proに次ぐものです。さらに、他の主要なAIモデルと比較しても遜色のない性能指標を持ちながら、コストは大幅に抑えられています。これは、思考能力による品質向上と、Flashモデル本来の効率性を両立していることを示しています。
5. 利用方法と今後の展望
思考機能を備えたGemini 2.5 Flashは現在、Gemini API(Google AI StudioおよびVertex AI経由)およびGeminiアプリ内の専用ドロップダウンメニューからプレビュー版として利用可能です。以下のPythonコードスニペットは、APIで思考予算を設定する例です。
from google import genai
client = genai.Client(api_key="YOUR_API_KEY") # 実際のAPIキーに置き換えてください
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
# 思考予算を1024トークンに設定
thinking_budget=1024
)
)
)
print(response.text)開発者は、thinking_budget パラメータを試すことで、制御可能な推論機能がどのように複雑な問題解決に役立つかを探求できます。詳細なAPIリファレンスや思考ガイドは、開発者ドキュメントやGemini Cookbookで提供されています。今後、さらなる改良が加えられ、正式版(GA)としてリリースされる予定です。
※確認用GoogleColab(弊社作成): https://colab.research.google.com/drive/1XT0b_QpTOq-_FKLGTRTtqGWbazusM6_L?usp=sharing
まとめ
Gemini 2.5 Flashは、AIエンジニアにとって、モデルの「思考」プロセスを直接制御できるという新たな可能性を開くものです。思考予算というユニークな機能により、アプリケーションの要件に合わせて品質、コスト、レイテンシをきめ細かく調整できます。プレビュー版を通じて、この新しいモデルの能力をぜひ体験し、その可能性を最大限に引き出してください。