はじめに
本稿では、MetaのFundamental AI Research (FAIR)チームが公開した、高度な機械知能 (AMI: Advanced Machine Intelligence) の実現に向けた最新の研究成果について公式ブログ「Advancing AI systems through progress in perception, localization, and reasoning」よりご紹介します。
これらの研究は、AIシステムにおける知覚 (Perception)、自己位置推定 (Localization)、推論 (Reasoning) の能力向上に焦点を当てており、エンジニアにとって非常に興味深い内容となっています。特に、コンピュータビジョンシステム、3D空間認識、自然言語による物体特定、大規模言語モデル (LLM) の協調的推論能力に関する重要な進展が含まれています。
引用元情報
- 記事タイトル: Advancing AI systems through progress in perception, localization, and reasoning
- 発行日: 2025年4月17日
- 参照元URL: https://ai.meta.com/blog/meta-fair-updates-perception-localization-reasoning/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
- Meta Perception Encoder: 画像・動画の両方で優れた性能を発揮する大規模視覚エンコーダー。特にゼロショット分類・検索タスクで既存モデルを凌駕し、困難な認識タスク(例:海底に隠れたエイ、背景の小さな鳥)にも強い。LLMと連携させることで、画像・動画の質疑応答 (VQA)、キャプション生成、文書理解などの性能も向上。
- Meta Perception Language Model (PLM): 困難な視覚認識タスクに取り組むための、オープンで再現可能な視覚言語モデル。合成データと新規収集した詳細な動画QA・時空間キャプションデータ(250万サンプル)を用いて学習。PLM-VideoBenchという新しいベンチマークも公開。
- Meta Locate 3D: 自然言語クエリ(例:「テーブルの上の赤いカップを持ってきて」)に基づいて、3D環境内の物体を正確に特定するエンドツーエンドモデル。RGB-Dセンサーからの3D点群データを直接利用し、空間的関係性を考慮して物体を特定。大規模な参照表現に基づく物体特定データセットも公開。
- Dynamic Byte Latent Transformer: バイトレベル言語モデルアーキテクチャにおけるブレークスルー。従来のトークン化ベースのモデルと同等の性能を達成しつつ、推論効率と堅牢性(特にノイズのある入力に対する耐性)を大幅に向上。
- Collaborative Reasoner: LLMの協調的推論スキルを評価・向上させるためのフレームワーク。複数のエージェントが対話を通じて協力して問題を解決するタスク群を提供。自己協調 (Self-collaboration) による合成対話データを用いた自己改善アプローチを提案し、性能向上を実証。大規模推論のためのMatrixエンジンも公開。
詳細解説
1. Meta Perception Encoder:視覚と言語をつなぐ新基準
AIシステムが世界を理解するためには、「目」の役割を果たす視覚エンコーダー (Vision Encoder) が不可欠です。Meta Perception Encoderは、画像と動画の両方に対応し、多様な視覚タスクで最先端の性能を達成することを目指して開発されました。
- 技術的特徴:
- 言語連携: 視覚情報と言語情報を効果的に結びつけます。
- 画像・動画対応: 静止画だけでなく、動的な動画コンテンツの理解も可能です。
- 堅牢性: 様々な環境変化や敵対的攻撃に対しても安定した性能を維持します。
- 高精度な概念認識: 広範な概念を認識しつつ、微妙な違い(例:動物の種の違い)も識別できる高い知覚能力を持ちます。
- 性能:
- 画像・動画のゼロショット分類および検索タスクにおいて、既存のオープンソースおよびプロプライエタリモデルを上回る性能を示しました。
- 困難な認識タスク(例:保護色、遠景の小さな物体、暗視カメラ映像)で特に高い性能を発揮します。
- LLMと組み合わせることで、VQA、キャプション生成、文書理解、グラウンディング(テキストと画像の対応付け)といった下流タスクの性能を大幅に向上させます。特に、物体の前後関係やカメラの動きといった、従来のLLMが苦手としていたタスクでの改善が顕著です。
2. Meta Perception Language Model (PLM):視覚認識の理解を深める
PLMは、特に困難な視覚認識タスクに取り組むために設計された、オープンソースで再現性の高い視覚言語モデル (Vision-Language Model) です。
- データセット:
- 大規模な合成データと、既存のオープンな視覚言語理解データセットを使用しました。
- 既存データのギャップを埋めるため、250万の新規人間ラベル付き詳細動画QAおよび時空間キャプションサンプルを収集・作成しました。これはこの種のデータセットとしては過去最大規模です。
- モデル:
- 人間ラベルデータと合成データを組み合わせて学習し、堅牢性と精度を両立させています。
- 10億、30億、80億パラメータのバリアントが提供され、学術研究に適しています。
- ベンチマーク:
- PLM-VideoBenchを新たに公開。これは、既存のベンチマークが見落としていた詳細な活動理解や時空間に基づいた推論に焦点を当てています。
3. Meta Locate 3D:オープン語彙での物体特定の新たな地平
ロボットが物理世界で人間を効果的に支援するためには、自然言語に根差した3D世界の理解が不可欠です。Meta Locate 3Dは、この課題に取り組むモデルです。
- 前提技術:
- RGB-Dセンサー: 色情報(RGB)と深度情報(Depth)を同時に取得できるセンサー。これにより3D点群データを生成します。
- 3D点群 (Point Cloud): 3次元空間上の点の集合で、物体の形状やシーンの構造を表現します。
- モデル構成:
- 前処理: 2Dの基盤モデルの特徴量を3D点群に持ち上げます。
- 3D-JEPAエンコーダー: 事前学習済みのエンコーダーで、特徴付けられた点群を入力とし、文脈化され平滑化された3D世界の表現を予測します。
- Locate 3Dデコーダー: 3D-JEPAの表現と言語クエリを入力とし、指定された物体のバウンディングボックスとマスクを出力します。
- 特徴:
- 「テレビコンソールの近くの花瓶」のような自然言語クエリを理解し、空間的な関係性(例:「近く」「上」)や文脈を考慮して特定の物体インスタンスを識別します。
- エンドツーエンドで動作し、RGB-Dセンサーからの入力から直接、物体の3D位置を特定します。
- データセット:
- 参照表現に基づく物体特定のための新しいデータセットを公開。ARKitScenes、ScanNet、ScanNet++という3つの主要データセットにわたる13万の言語アノテーションを含み、既存のデータ量を倍増させました。
4. Dynamic Byte Latent Transformer:効率と堅牢性の再定義
従来のLLMは、テキストをトークンと呼ばれる単位に分割して処理しますが、このトークン化にはいくつかの課題がありました(未知語への対応、言語による性能差など)。Dynamic Byte Latent Transformerは、テキストをバイトレベルで直接扱う新しいアプローチです。
- 技術的特徴:
- バイトレベル処理: テキストを固定長のバイトシーケンスとして扱うため、トークン化が不要になります。
- 動的潜在表現: バイトシーケンスから動的に潜在表現を学習します。
- 利点:
- 性能: 大規模なモデルにおいて、従来のトークン化ベースのLLMと同等の性能を達成しました。
- 推論効率の向上: 特定の条件下で推論が高速になる可能性があります。
- 堅牢性の大幅な向上: 特にノイズが加えられた入力や、トークン化が困難なテキスト(例:特殊文字、コード)に対する耐性が大幅に向上します(例:摂動を加えたHellaSwagで+7ポイント、CUTEベンチマークで最大+55ポイント)。
5. Collaborative Reasoner:合成対話による自己改善型ソーシャルエージェント
人間同士が協力してより良い結果を出すように、AIエージェントも人間や他のAIと協調することで、単独よりも優れたタスク遂行能力を発揮することが期待されます。Collaborative Reasonerは、LLMの協調的推論スキルを評価し、向上させるためのフレームワークです。
- 課題:
- 協調には、問題解決能力に加え、効果的なコミュニケーション、フィードバック提供、共感、心の理論といった社会的スキルが必要です。
- 協調的な対話データは収集コストが高く、ドメイン固有であり、制御が困難です。
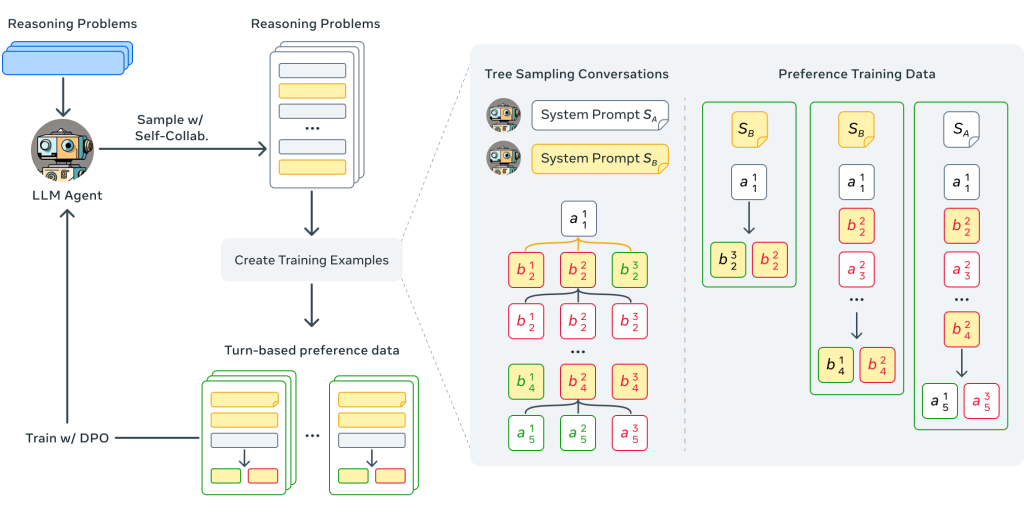
- Collaborative Reasonerフレームワーク:
- 目標指向タスク: 複数ステップの推論を必要とし、2つのエージェントが複数ターンの対話を通じて協力して達成する必要があるタスク群を提供します。
- 評価指標: エージェントが意見の相違を乗り越え、相手を説得し、最終的にチームとして最良の解決策に合意する能力を評価します。
- 自己改善アプローチ:
- 現在のモデルは協調を効果的に活用できていないことが示されました。
- 自己協調 (Self-collaboration)、つまりLLMエージェントが自身と協調する形で合成対話データを生成し、それを用いてモデルを自己改善するアプローチを提案しました。
- このアプローチにより、数学(MATH)、科学(MMLU-Pro, GPQA)、社会的推論(ExploreToM, HiToM)タスクにおいて、単一エージェントの思考連鎖(Chain-of-Thought)性能と比較して最大29.4%の改善を達成しました。
- Matrix:
- 合成データを大規模に生成するための、多用途で高性能なモデルサービングエンジンMatrixも開発・公開されました。
Download the Collaborative Reasoner code
まとめ
本稿では、Meta FAIRが公開した5つの重要な研究成果、Meta Perception Encoder、Meta Perception Language Model (PLM)、Meta Locate 3D、Dynamic Byte Latent Transformer、Collaborative Reasonerについて、技術的な側面を中心に解説しました。
これらの研究は、AIがより高度な知覚能力を獲得し、3D空間を理解し、自然言語を通じて人間と対話し、さらには協調して問題を解決するための基盤技術を大きく前進させるものです。特に、視覚と言語の統合、バイトレベルでの言語処理、協調的推論といった領域でのブレークスルーは、今後のAI開発に大きな影響を与えると考えられます。
Meta FAIRはこれらのモデル、コード、データセットをオープンソースとして公開しており、研究コミュニティ全体でのアクセスと利用を促進することで、AI分野全体の進歩と発見を加速させることを目指しています。