
はじめに
本稿では、OpenAIが発表した最新の視覚推論モデル「o3」および「o4-mini」について解説します。これらのモデルは、単に画像を「見る」だけでなく、画像を思考プロセスに組み込んで推論するという画期的な能力を備えており、マルチモーダルAIの分野における大きな進歩を示しています。新しい技術の核心を理解できるよう、その仕組み、性能、そして今後の可能性について、技術的な観点から公式ブログ「Thinking with images」をもとに掘り下げていきます。
引用元記事
- 記事タイトル: Thinking with images
- 発行日: 2025年4月16日
- 参照元URL: https://openai.com/index/thinking-with-images/
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
OpenAI o3およびo4-miniモデルの重要なポイントは以下の通りです。
- 画像を思考プロセスに組み込む: これまでのモデルが画像を認識するだけだったのに対し、o3/o4-miniは思考の連鎖 (chain of thought) の中で画像を能動的に利用し、推論を進めることができます。
- ネイティブな画像操作能力: 画像のトリミング、ズーム、回転といった基本的な画像処理機能を、外部の専用モデルに頼ることなくネイティブ機能として内蔵しています。これにより、モデル自身が画像内の情報を段階的に分析できます。
- 高度な視覚的理解力: 不完全な画像(例:逆さまの文字、一枚の写真に複数の問題)からでも、自動的な画像操作を通じて洞察を引き出すことが可能です。手書き文字の認識、複雑な問題解決(物理学の問題など)、標識の読み取りといったタスクで高い能力を発揮します。
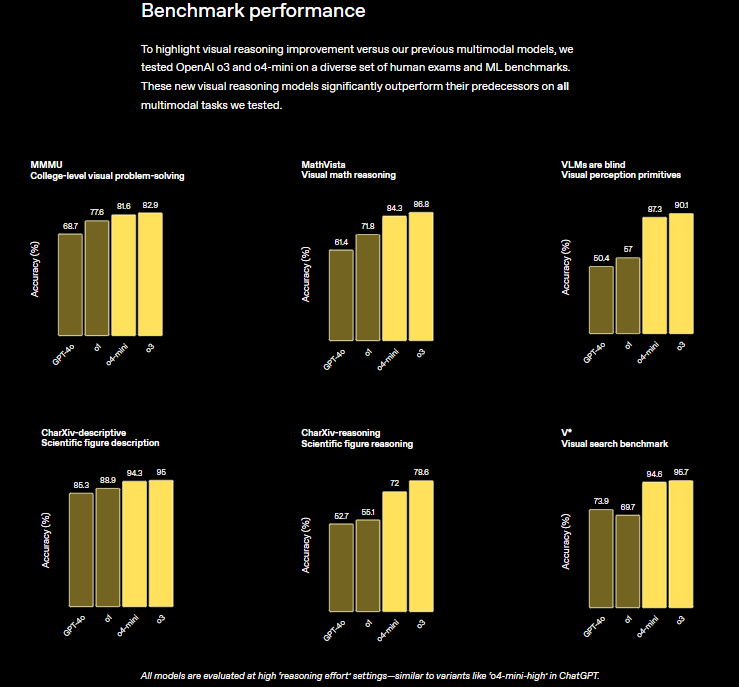
- ベンチマークでの高性能: MMMU、MathVista、CharXiv、VLMs are Blind、V* といった主要なマルチモーダルベンチマークにおいて、既存のモデル(GPT-4o、o1含む)を大幅に上回る最先端の性能を達成しています。特にV* ベンチマークでは95.7%の精度を記録し、ほぼ問題を解決したと言えます。
詳細解説
前提知識:マルチモーダルAIと思考の連鎖
o3/o4-miniの革新性を理解するために、まず「マルチモーダルAI」と「思考の連鎖」について触れておきます。
マルチモーダルAIとは、テキスト、画像、音声など、複数の異なる種類のデータ(モダリティ)を統合的に処理できるAIのことです。GPT-4oなどが代表例ですが、従来の多くのモデルでは、画像は主に初期入力として扱われ、その後の推論プロセスは主にテキストベースで行われていました。
一方、「思考の連鎖 (Chain of Thought: CoT)」は、大規模言語モデル(LLM)が複雑な問題に解答する際に、最終的な答えに至るまでの中間的な推論ステップを明示的に生成する手法です。これにより、推論の透明性が高まり、より複雑で段階的な思考が可能になります。
「画像を思考プロセスに組み込む」技術
o3およびo4-miniの最大の特徴は、この思考の連鎖のプロセスに、画像そのものとその操作を組み込んだ点にあります。ユーザーから画像がアップロードされると、モデルは単にそれを認識するだけでなく、推論を進める中で必要に応じて以下のようなネイティブな画像処理ツールを自律的に使用します。
- トリミング (Crop): 画像の特定の部分に焦点を当てる。
- ズーム (Zoom in): 詳細を確認するために拡大する。
- 回転 (Rotate): 向きが正しくない画像(例:逆さまの文字)を読みやすいように回転させる。
- 反転 (Flip): 必要に応じて画像を反転させる。
- 強調 (Enhance): 画像の品質を改善する。
例えば、手書きのメモを読み取るタスクでは、モデルはまず画像全体を認識し、文字が逆さまになっていることに気づくと画像を回転させ、さらに文字が書かれている部分をトリミングしてズームインし、内容を正確に読み取るといったステップを内部的に実行します。重要なのは、これらの画像操作が別の専用モデルを呼び出すのではなく、o3/o4-mini自身の機能として統合されている点です。これにより、視覚情報と言語情報がシームレスに連携した、より高度で柔軟な推論が可能になります。

利点と応用例
この「画像と共に思考する」能力は、以下のような利点をもたらします。
- 複雑な視覚的問題解決: 物理の問題図(ファインマン図など)の解釈や、複数の情報が含まれる画像からの特定情報の抽出など、より深い分析が必要なタスクに対応できます。
- 不完全な入力への耐性: 画像の向きが違っていたり、対象物が小さく写っていたりしても、モデルが自ら画像を調整して情報を抽出できます。
- 他ツールとの連携: 画像分析の結果を、Web検索やデータ分析といった他のツールと組み合わせることで、より包括的な問題解決(例:バス停の標識を読み取り、Web検索で時刻表を調べる)が可能になります。
パフォーマンスとベンチマーク
o3/o4-miniは、その高度な視覚推論能力により、多くのマルチモーダルベンチマークで既存モデルを凌駕する性能を示しています。
- MMMU (大学レベルの視覚的問題解決): 82.9% (o3)
- MathVista (視覚的数学推論): 86.8% (o3)
- VLMs are Blind (視覚知覚プリミティブ): 90.1% (o3)
- CharXiv-descriptive (科学図の記述): 95.0% (o3)
- CharXiv-reasoning (科学図の推論): 78.6% (o3)
- V* (視覚探索ベンチマーク): 95.7% (o3)
これらの結果は、特にブラウジング機能に頼らずに画像内の情報だけで推論する能力が大幅に向上したことを示しており、マルチモーダル推論における大きなブレークスルーと言えます。
制限事項
一方で、この技術にはまだ改善の余地があります。
- 冗長な推論: 不必要な画像操作を繰り返すなど、思考の連鎖が過度に長くなる場合があります。
- 知覚エラー:基本的な画像の誤認識が依然として発生する可能性があり、それが最終的な解答の誤りにつながることがあります。
- 信頼性: 同じ問題に対しても、試行ごとに異なる推論プロセスを試み、結果が安定しない場合があります。
まとめ
OpenAIのo3およびo4-miniモデルは、「画像を思考プロセスに組み込む」という新しいアプローチにより、マルチモーダルAIの視覚推論能力を大きく前進させました。ネイティブな画像操作ツールと思考の連鎖を組み合わせることで、これまで困難だった複雑な視覚的問題の解決や、不完全な画像からの情報抽出を可能にしています。ベンチマークでの圧倒的な性能は、その有効性を明確に示しています。
いくつかの制限事項は残るものの、これらのモデルはより汎用的なマルチモーダル推論に向けた重要な一歩であり、今後のAIの進化において中心的な役割を果たすことが期待されます。OpenAIは、これらのモデルの推論能力をより簡潔で信頼性の高いものにするための改良を継続しており、今後の発展が非常に楽しみです。








