はじめに
OpenAIは2025年4月14日、開発者向けに新たな大規模言語モデル(LLM)シリーズ「GPT-4.1」をAPI(※1)経由で提供開始すると発表しました。本稿では、このGPT-4.1、GPT-4.1 mini、そしてGPT-4.1 nanoという3つの新モデルについて、その進化の内容と、ビジネスや開発現場にもたらす可能性を、エンジニアでない方にも分かりやすく解説します。特に、コーディング、指示追従、長文脈(Long Context)処理能力の飛躍的な向上が注目されています。
※1 API(Application Programming Interface): ソフトウェアやプログラム、Webサービスの間で情報をやり取りするための接続口のようなものです。開発者はAPIを利用することで、特定の機能(この場合はGPTモデルの能力)を自身のアプリケーションやサービスに組み込むことができます。
引用元
- タイトル:Introducing GPT-4.1 in the API
- URL:https://openai.com/index/gpt-4-1/
- 発行日:2025年4月14日
・本稿中の画像に関しては特に明示がない場合、引用元記事より引用しております。
・記載されている情報は、投稿日までに確認された内容となります。正確な情報に関しては、各種公式HPを参照するようお願い致します。
・内容に関してはあくまで執筆者の認識であり、誤っている場合があります。引用元記事を確認するようお願い致します。
要点
今回発表されたGPT-4.1シリーズの主な特徴は以下の通りです。
- 性能向上: 従来のGPT-4oやGPT-4o miniを全体的に上回る性能を実現。特にコーディングと指示追従能力が大幅に向上しました。
- 長文脈対応: 最大100万トークン(※2)という、従来(12.8万トークン)より格段に長い文脈を扱えるようになり、長文の読解・要約、大規模なコードベースの処理能力が向上しました。
- 知識の更新: 最新の知識カットオフ(学習データの最終日時)が2024年6月に更新されました。
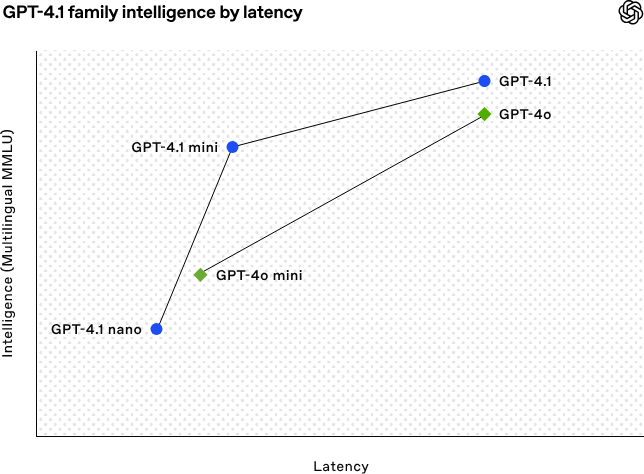
- コスト効率: 性能向上にもかかわらず、より低いコストで利用可能になりました。特にGPT-4.1 miniはGPT-4oに匹敵するか上回る性能を、約半分の遅延(レイテンシ ※3)、83%削減されたコストで提供します。GPT-4.1 nanoは最速・最安価モデルとして登場しました。
- エージェント(※4)開発支援: 指示追従の信頼性向上と長文脈理解により、ユーザーの代わりに自律的にタスクを実行するAIエージェントの開発がより効果的になります。
- API限定提供: これらの新モデルはAPI経由でのみ利用可能です。ChatGPTでの利用は、既存のGPT-4oに段階的に機能が統合されます。
- GPT-4.5 Previewの提供終了: GPT-4.1の登場に伴い、GPT-4.5 Previewは2025年7月14日に提供終了となります。
※2 トークン: AIがテキストを処理する際の最小単位。単語や文字の一部に対応します。100万トークンは、一般的な書籍数冊分に相当する情報量です。
※3 遅延(レイテンシ): リクエストを送信してから応答が返ってくるまでの時間。短いほど応答が速いことを意味します。
※4 エージェント: 特定の目標達成のために、自律的に計画を立て、ツールを使ったり、情報を集めたりしながらタスクを実行できるAIシステムのこと。
詳細解説
1. 新モデルファミリーの概要
OpenAIは今回、GPT-4.1、GPT-4.1 mini、GPT-4.1 nanoの3つのモデルを発表しました。これらは、従来の主力モデルであったGPT-4oシリーズと比較して、あらゆる点で性能が向上しています。開発者は、アプリケーションの要件(求める性能、許容できる遅延、コスト)に応じて最適なモデルを選択できるようになります。
- GPT-4.1: 最高性能モデル。特にコーディングと指示追従能力に優れ、複雑なタスクに対応します。
- GPT-4.1 mini: 中間モデル。GPT-4oに匹敵または凌駕する性能を持ちながら、遅延とコストを大幅に削減しており、バランスの取れた選択肢です。
- GPT-4.1 nano: 最速・最安価モデル。100万トークンのコンテキストウィンドウを持ちつつ、分類や自動補完など、低遅延が求められるタスクに最適です。驚くべきことに、MMLU(※5)などのベンチマークではGPT-4o miniをも上回るスコアを記録しています。
※5 MMLU (Massive Multitask Language Understanding): 多様な分野の知識と推論能力を測定する標準的なベンチマーク(性能評価指標)の一つ。
2. 主要な改善点
2.1. コーディング能力の飛躍的向上
GPT-4.1は、コーディング能力において目覚ましい進化を遂げました。
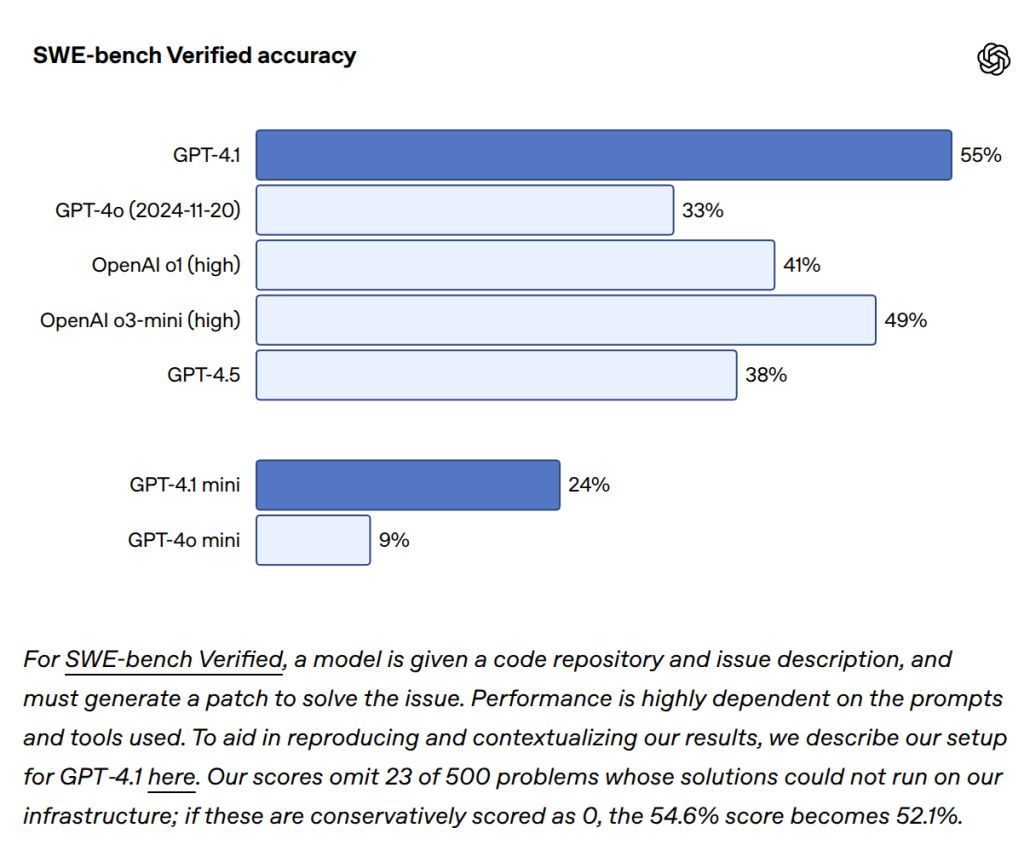
- SWE-bench Verified(実際のソフトウェア開発タスク解決能力を測るベンチマーク)において、54.6%のスコアを達成。これはGPT-4oから21.4%、GPT-4.5から26.6%もの絶対的な改善であり、業界トップクラスの性能です。
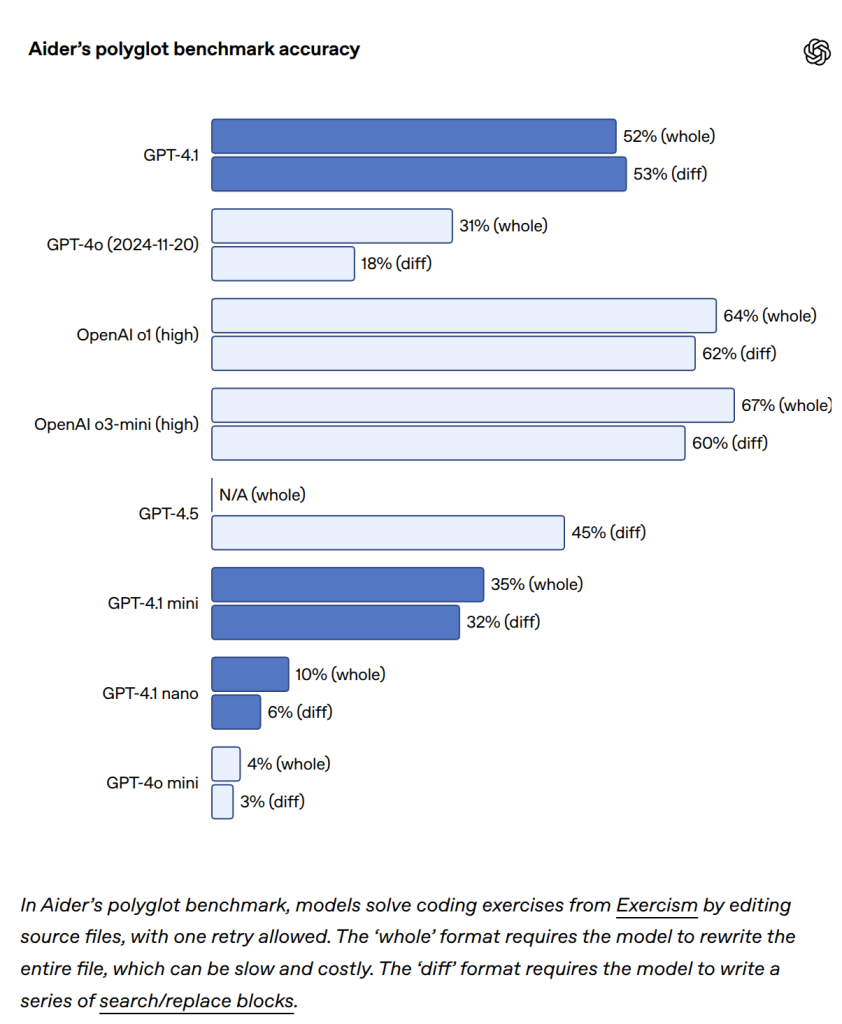
- Aider’s polyglot diff benchmark(複数言語でのコード編集・差分生成能力を測るベンチマーク)では、GPT-4oのスコアを2倍以上にし、GPT-4.5をも上回りました。これにより、ファイル全体を書き換えるのではなく、変更箇所のみを出力させることで、コストと遅延を削減できます。
- フロントエンド開発(Webサイトの見た目や操作部分の開発)においても、より機能的で見た目にも優れたWebアプリを作成できるようになりました。内部評価では、人間による評価で80%の場合においてGPT-4.1が生成したWebサイトの方が好まれました。
- 不要な編集の削減: 内部評価では、コードに対する不要な編集がGPT-4oの9%からGPT-4.1では2%に減少しました。
<実例>
- Windsurf社: 内部コーディングベンチマークでGPT-4.1がGPT-4oより60%高いスコアを記録。ツール呼び出し効率が30%向上し、不要な編集の繰り返しが約50%減少しました。
- Qodo社: GitHubのプルリクエスト(コード変更提案)に対するコードレビュー生成テストで、GPT-4.1が55%のケースでより良い提案を行いました。
2.2. 指示追従能力の強化
ユーザーの指示にいかに正確に従えるかは、AIの信頼性において極めて重要です。GPT-4.1はこの点でも大幅に改善されました。
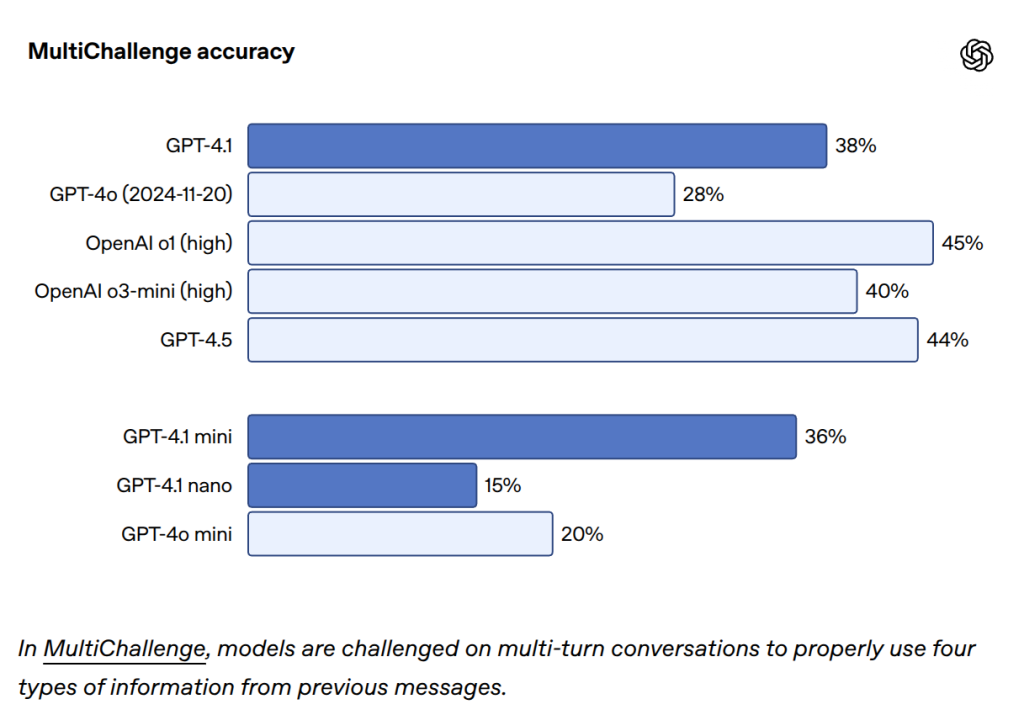
- Scale社のMultiChallengeベンチマーク(複数ターンにわたる会話での指示追従能力を測定)で、38.3%のスコアを記録し、GPT-4oから10.5%の絶対的向上を見せました。
- IFEval(特定のフォーマットや禁止事項などの指示を守れるかを検証)では、GPT-4oの81.0%に対し、GPT-4.1は87.4%を達成しました。

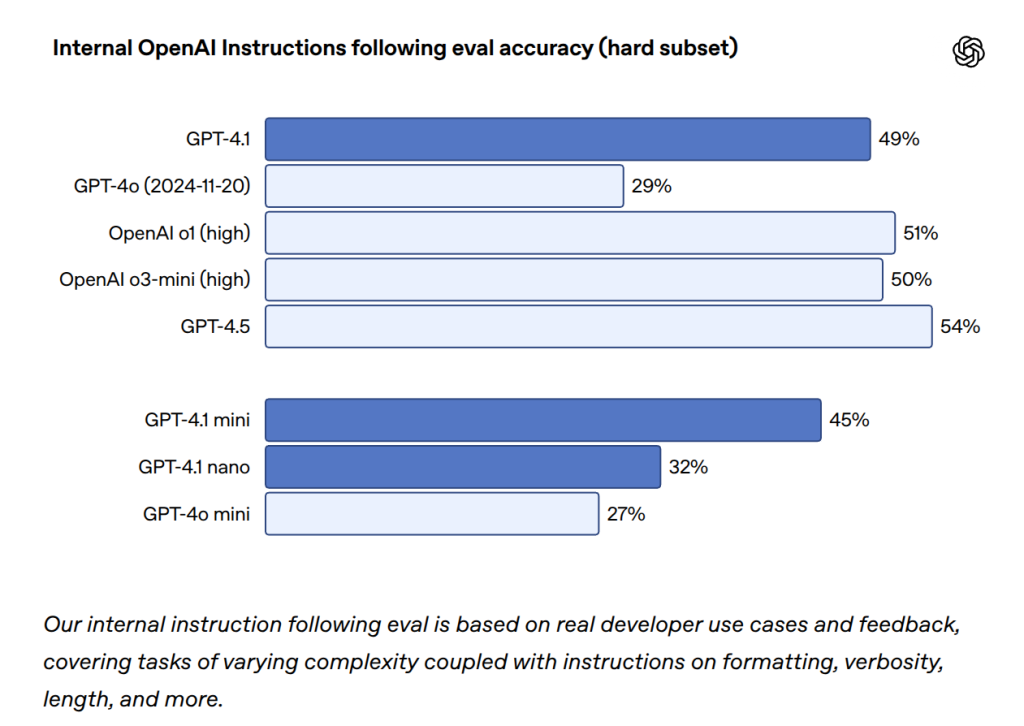
- OpenAIの内部評価(フォーマット指定、禁止事項、順序指定、内容要求、ランキング、知らない場合の応答など、開発者のフィードバックに基づいた多角的な評価)でも、特に難しい指示に対する正答率がGPT-4oの29.2%から49.1%へと大幅に向上しました。
これにより、特定のフォーマットでの出力を要求したり、複雑な手順を指示したりする場合でも、より信頼性の高い応答が期待できます。
<実例>
- Blue J社: 複雑な税務シナリオに関する内部ベンチマークで、GPT-4.1はGPT-4oより53%高い精度を達成。複雑な規制の理解と長文脈での指示追従能力が向上しました。
- Hex社: 最も困難なSQL(データベース言語)評価セットで、GPT-4.1は約2倍の改善を示しました。大規模で曖昧なスキーマから正しいテーブルを選択する能力が向上しました。
2.3. 長文脈(Long Context)処理能力の向上
GPT-4.1シリーズの最大の特徴の一つが、扱える文脈の長さです。最大100万トークンまで対応可能となり、これは従来のGPT-4o(12.8万トークン)から大幅な拡張です。React(Web開発フレームワーク)の全コードベースの8コピー以上に相当する情報量を一度に処理できます。
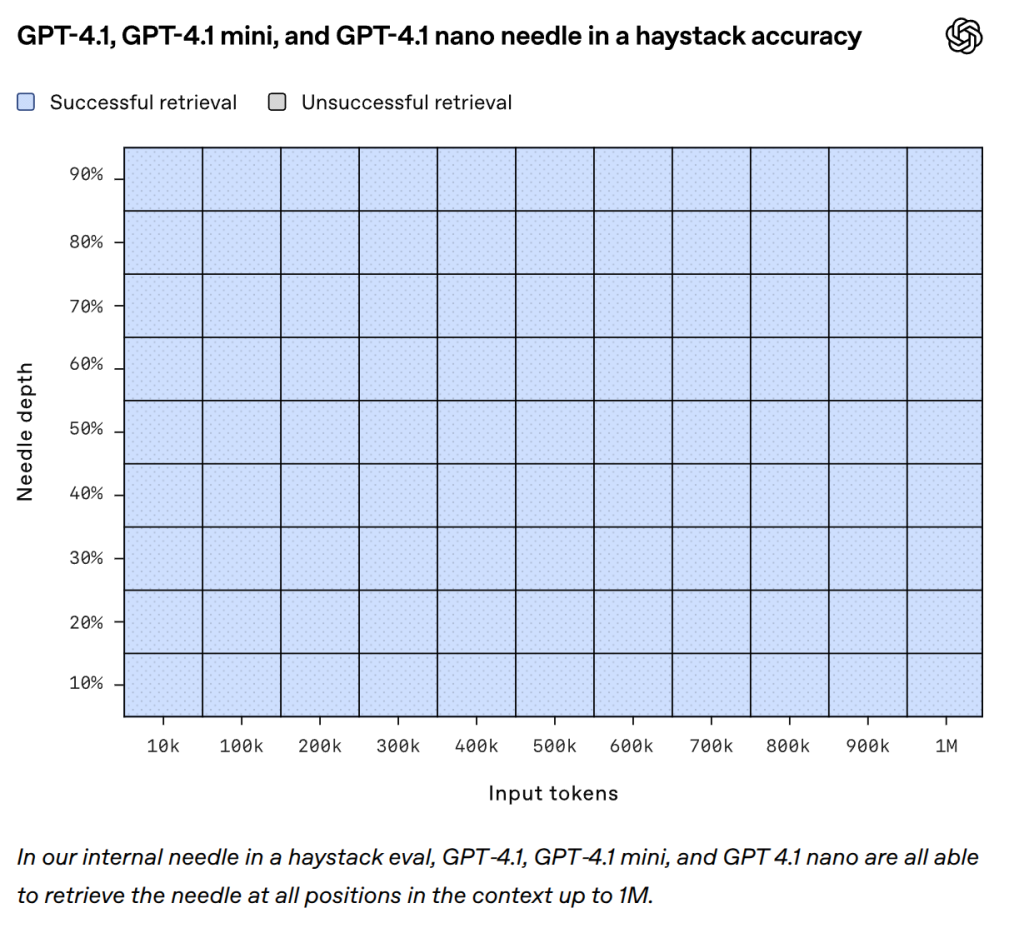
- Needle in a Haystackテスト(大量のテキストの中から特定の情報を見つけ出すテスト)では、100万トークンの文脈全体にわたって、どこに情報が隠されていても一貫して正確に情報を抽出できることが示されました。
- OpenAI-MRCR(文脈中に隠された複数の類似情報を区別して抽出する新しい評価)やGraphwalks(文脈内の複数の箇所を参照する必要がある、より複雑な推論能力を評価するデータセット)といった、より実践的な長文脈理解・推論能力を測る評価でも、GPT-4oを上回る性能を示しています。
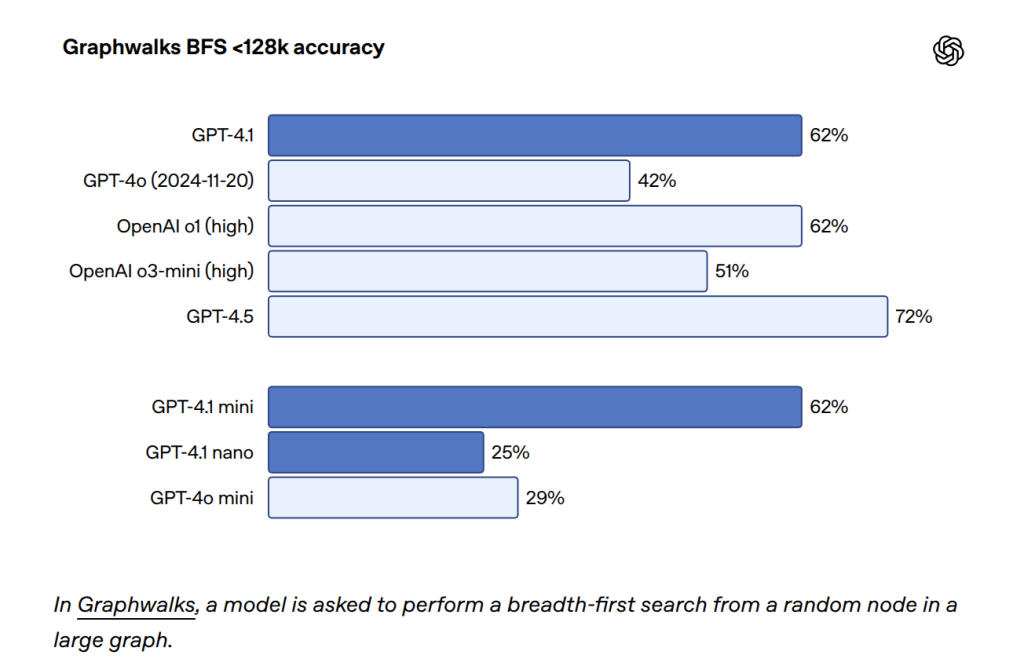
これにより、大量の文書(契約書、研究論文、マニュアルなど)の読解・分析、大規模なコードベースの理解・編集、長時間の顧客対応履歴の分析などが、より効率的かつ正確に行えるようになります。
<実例>
- Thomson Reuters社: 法律専門家向けAIアシスタント「CoCounsel」でGPT-4.1をテストした結果、複数の長文法律文書を扱うレビュー精度がGPT-4oと比較して17%向上しました。
- Carlyle社: 複数の長い文書(PDF、Excelなど)から詳細な財務データを抽出するタスクで、GPT-4.1は50%優れた性能を示し、他のモデルでは見られた限界(情報の見落とし、中間部分の情報の喪失、複数文書間の推論エラー)を克服しました。
2.4. Vision(画像理解)能力
GPT-4.1ファミリーは画像理解能力も優れており、特にGPT-4.1 miniは多くの画像ベンチマークでGPT-4oを上回るなど、大きな進歩を遂げています。
- MMMU(図表や地図などを含む質問応答)、MathVista(視覚的な数学問題解決)、CharXiv-Reasoning(科学論文中のグラフに関する質問応答)などのベンチマークで高いスコアを記録しています。
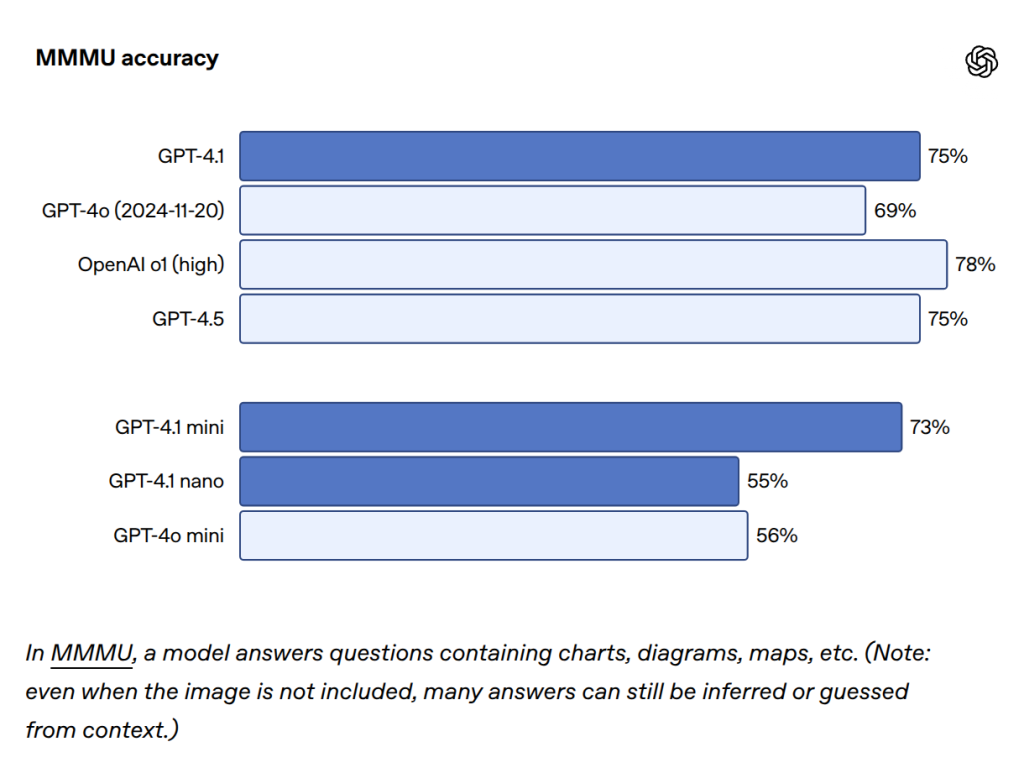
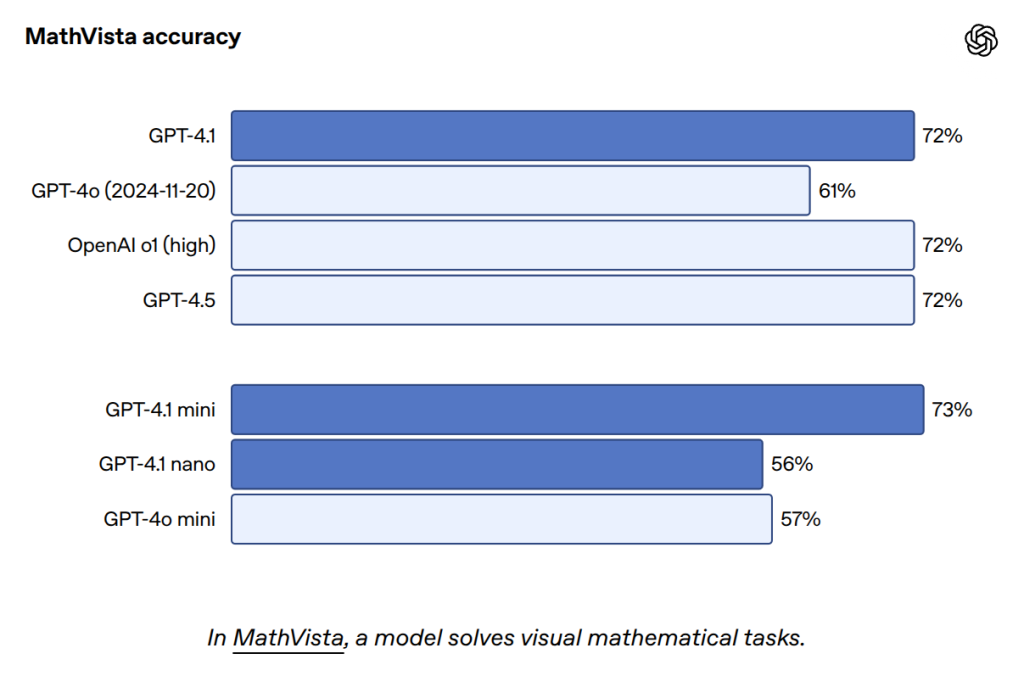
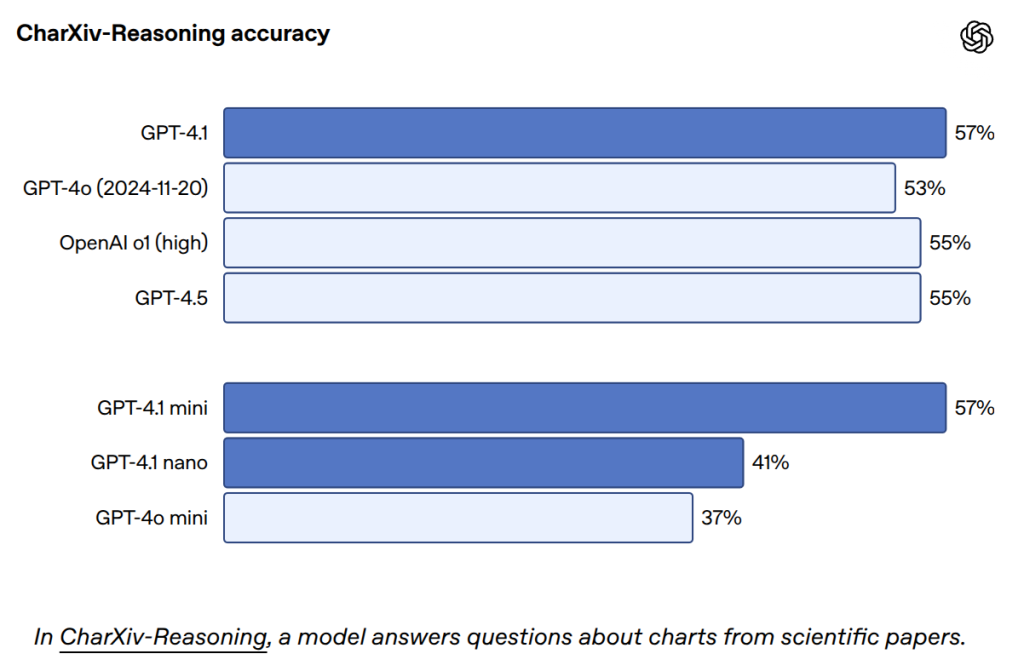
- Video-MME(字幕なしの長尺動画(30~60分)に関する多肢選択問題)では、GPT-4.1が72.0%という最先端のスコアを達成しました(GPT-4oは65.3%)。

3. コストと利用方法
GPT-4.1シリーズは、推論システムの効率改善により、性能向上と同時に低価格化も実現しています。
| モデル | 入力 (100万トークンあたり) | キャッシュされた入力 | 出力 (100万トークンあたり) | ブレンド価格* |
| gpt-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| gpt-4.1-mini | $0.40 | $0.10 | $1.60 | $0.42 |
| gpt-4.1-nano | $0.10 | $0.025 | $0.40 | $0.12 |
- 一般的な入出力比率とキャッシュ比率に基づく概算。
同じ文脈を繰り返し使用する場合のプロンプトキャッシュ割引も、従来の50%から75%に引き上げられました。また、長文脈の利用に追加料金はかかりません(通常のトークンあたりの料金のみ)。
これらのモデルは現在、すべての開発者がAPIを通じて利用可能です。また、Batch API(大量のタスクをまとめて処理するAPI)では、さらに50%の割引価格で利用できます。
4. GPT-4.5 Previewの提供終了について
GPT-4.1の登場に伴い、研究プレビューとして提供されていたGPT-4.5 Previewは、2025年7月14日をもって提供終了となります。開発者からのフィードバックで評価された創造性や文章品質などは、今後のAPIモデルに引き継がれていく予定です。
まとめ
今回発表されたGPT-4.1シリーズは、AI開発における新たなマイルストーンと言えるでしょう。特にコーディング、指示追従、長文脈処理における飛躍的な性能向上は、開発者がより高機能で信頼性の高いAIアプリケーションや、洗練されたAIエージェントを構築することを可能にします。
性能とコストのバランスが取れたGPT-4.1 miniや、速度とコストを重視するGPT-4.1 nanoの登場により、多様なニーズに応じたAI活用がさらに加速することが期待されます。