
はじめに
近年、AI技術は目覚ましい発展を遂げ、基本的なチャットボットから、より複雑な推論やエージェントへと進化しています。特に、インターネット上の情報を自律的に探索し、活用する「ブラウジングエージェント」への関心が高まっています。しかし、従来のベンチマークでは、比較的容易に見つけられる情報に焦点が当てられており、最新の言語モデルでは飽和状態になりつつあります。
このような背景を踏まえ、OpenAIの研究者らは、より困難で複雑な情報探索能力を評価するための新しいベンチマーク「BrowseComp(Browsing Competition)」を発表しました。本稿では、このBrowseCompベンチマークについて、論文を参照する形で詳しく解説します。
BrowseCompは、プログラミングコンペティションがコーディングエージェントの能力を測る上で有用な指標となるのと同様に、ブラウジングエージェントの重要な基礎能力を評価するための指標となることが期待されています。
引用論文:
- タイトル:BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
- URL:https://cdn.openai.com/pdf/5e10f4ab-d6f7-442e-9508-59515c65e35d/browsecomp.pdf
- Github:https://github.com/openai/simple-evals
・あくまで個人の理解に基づくものであり、正確性に問題がある場合がございます。
必ず参照元論文をご確認ください。
・本記事内での画像は、上記論文より引用しております。
要点
- BrowseCompとは: ウェブブラウジングエージェントの能力を評価するための新しいベンチマークです。
- 課題の難易度: 1,266の質問は、インターネット上の深く複雑に絡み合った、見つけにくい情報を探索することを要求します。
- 検証の容易さ: 質問と解答は短く、予測された解答は参照解答と容易に比較して検証できます。
- 人間の性能: 人間のトレーナーによる評価では、約7割が2時間以内に解答を諦めるほど、難易度の高い問題が含まれています。
- モデルの評価: OpenAIの様々なモデル(GPT-4o、GPT-4.5、OpenAI o1、Deep Research)で評価が行われ、特にDeep Researchが約半数の問題を解決する高い性能を示しました。
- 計算資源との関係: モデルの性能は、テスト時の計算資源の量に応じて向上する傾向が見られました。
- 評価内容: BrowseCompは、事実性に関する推論能力、粘り強いインターネットナビゲーション能力、そして創造的な検索能力を評価します。
詳細解説
本論文「BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents」 では、ウェブブラウジングエージェントの能力を評価するための新しいベンチマークであるBrowseCompについて、詳細な情報が提供されています。以下では、論文の各項目に沿って、その内容を丁寧に解説していきます。
1 Introduction
インターネットは情報へのアクセス方法を大きく変えましたが、人間による情報探索には、記憶や知識の限界、注意散漫や疲労による能力の低下、並行処理の難しさといった課題があります。一方、機械知能はより広範な記憶を持ち、疲れることなく動作し、並行処理も可能です。十分に能力のある機械知能であれば、何千ものウェブページを閲覧する必要があるような、明確に指定された情報でも、原理的にはウェブ全体から検索できるはずです。
近年のAIの進展に伴い、単純な検索クエリを超えてインターネットを閲覧できるモデルへの関心が高まっています。過去のベンチマークは、容易に見つけられる情報の検索能力を測るものが多かったため、最近の言語モデルでは性能が飽和してきています。そこで、本論文では、多数のウェブサイトを閲覧しなければ解決できない1,266の挑戦的な問題からなる新しいベンチマーク「BrowseComp(Browsing Competition)」が導入されました。例として、サッカーの試合に関する非常に具体的な条件を満たす試合や、フィクションのキャラクターに関する複数の特徴を持つキャラクターの特定、そして特定の条件を満たす研究論文のタイトル特定などが挙げられています。これらの問題は、多数の潜在的な答えの中から、質問で提示された制約条件に合致するものを探し出す必要があるため、困難です。BrowseCompは、信頼性、難易度、使いやすさを重視して設計されました。
2 Data collection and verification
BrowseCompのデータセットは、完全に人間のトレーナーによって収集されました。その作成手順は、事実に基づいた質問と単一の明確で短い答えを求めるSimpleQA の手順に大きく倣っています。BrowseCompの主要な特性は以下の通りです。
2.1 BrowseComp criteria
- Challenging to answer:
トレーナーは、自身が作成した質問が10分以内に他の人によって解決されないこと、そして当時の既存モデル(ChatGPTのブラウジングあり・なし、初期のOpenAI Deep Research)でも解決できないことを確認しました。また、トレーナーは5回の簡単なGoogle検索を行い、検索結果の最初のページに答えが容易に存在しないことを確認するよう求められました。さらに、別の人が10分以内に解決できない程度の難易度を持つタスクを作成するよう指示されました。完全に義務ではありませんでしたが、一部の質問については、別のトレーナーが答えを探す試みを行いました。40%以上の確率で解決されたタスクを作成したトレーナーには、タスクの修正が求められました。 - Easy to verify, but hard to solve:
挑戦的な質問を作成するために、トレーナーはまず事実から始め、答えを見つけるのは難しいが検証は容易な逆の質問を作成することが推奨されました。トレーナーは通常、「シード」(人物、出来事、人工物など)から始め、大きな検索空間を持ついくつかの特性を見つけ出し、それらから質問を作成しました。例として、2018年から2023年の間にEMNLP会議で発表され、第一著者がダートマス大学で学部を卒業し、第四著者がペンシルバニア大学で学部を卒業した科学論文のタイトルを特定する問題が示されています。この例では、答えはいくつかのウェブ検索だけで簡単に検証できますが、総当たりで検索するには数千もの論文を調べ、それぞれの著者の経歴を確認する必要があるため、見つけるのは非常に困難です。 - Likely but not guaranteed to have all valid answers:
逆の質問を作成する際の一つの欠点は、参照解答として提供した答えが正しいことは確実ですが、他に答えが存在しないことを保証できないことです。EMNLPの例では、上記の基準に合致する論文が他に存在しないことを確実にするためには、すべての論文を調べる必要がありますが、それは現実的ではありません。しかし、ダートマス大学は小さな学校であり、質問を作成した人物はその分野に精通しているため、指定された期間にダートマス出身の人物がEMNLPで論文を発表していない可能性が高いと判断できます。他の正解が存在する可能性を減らすために、トレーナーは自分の質問の内容に十分に自信を持ち、他に有効な答えがないと確信できる程度に質問を作成するよう求められました。自信がない場合は、さらに基準を追加するよう指示されました。さらに、別のトレーナーが10分以内に参照解答ではない有効な答えを見つけた場合、質問を作成したトレーナーにフィードバックが与えられ、質問の修正が求められました。
2.2 Dataset diversity
BrowseCompの作成において、トレーナーは個人的な興味のあるトピックに関する質問を作成することが推奨されました。これは、個人的な関心事に関するデータポイントを作成することで、より魅力的な体験と、より質の高いデータにつながると期待されたためです。トピックの分布は以下のFigure2に示されています。最も多いトピックは「テレビ番組と映画」(16.2%)で、次いで「その他」(15.6%)、「科学技術」(13.7%)となっています。その他、「芸術」、「歴史」、「スポーツ」、「音楽」、「ビデオゲーム」、「地理」、「政治」など、多岐にわたるトピックが含まれています。

2.3 Grading
BrowseCompの参照解答はすべて短い文字列であるため、採点は、予測された解答が参照解答と意味的に同等かどうかをAIモデルが比較するだけで行われます。採点には、Humanity’s Last Exam と同じ採点プロンプトが使用されています。完全なプロンプトは以下の通りです。

2.4 What BrowseComp exercises
BrowseCompはそのシンプルさにもかかわらず、AIエージェントの核となるブラウジングスキルを測定します。
- 事実性に関する推論能力: 正しい答えを特定するためには、インターネット上のコンテンツの事実性について推論する能力が必要です。
- 粘り強さと深いブラウジング能力: 答えを見つけるのが難しいため、BrowseCompで良い成績を収めるには、粘り強さと深いブラウジング能力が求められます。
- 創造的な検索能力: 多くの答えは、総当たりでの検索では非常に時間がかかるか、不可能であるため、妥当な時間内に答えを見つけるためには、検索において創造性が必要です。
BrowseCompは、インターネットを閲覧するエージェントにとって、不完全ながらも有用なベンチマークと見なすことができます。真のユーザーのクエリ分布における課題(長い解答の生成や曖昧さの解消など)は扱っていませんが、情報を見つけ出す際の粘り強さと創造性という重要な核となる能力を測定します。プログラミングコンペティションが高いコーディング能力を示唆するのと同様に、BrowseCompで高い成績を収めるモデルは、見つけにくい情報を特定する能力が高いと考えられますが、それが他のすべてのブラウジングタスクに一般化されるとは限りません。
3 Human performance on BrowseComp
BrowseCompデータセットの難易度を測るための一つの指標として、質問を作成したのと同じグループの人間トレーナーに、BrowseCompの質問を解くよう依頼しました。ただし、トレーナーは自分が作成した質問を解くことはできず、正解にもアクセスできませんでした。また、AIアシスタント(ChatGPT、Claude、Perplexity、Grok、Geminiなど)を使用せずにタスクを完了するよう指示されました。一部の質問は非常に難しいため、トレーナーは2時間の検索で解決できなかった場合、問題を未解決として諦め、次の問題に進むことが許可されました。Table2に示すように、トレーナーは1,255件の質問のうち29.2%を解決しましたが、解決できた問題のうち、トレーナーの解答が元の参照解答と一致したのは86.4%でした。

Figure3は、トレーナーが問題を解決するのにかかった時間と、諦めた問題の時間の分布を示しています。解決できた問題では、1時間未満で解決できたものもあれば、2〜3時間かかったものも多くありました。トレーナーが諦めた場合、ルールに従い、約2時間問題を試みた後でした。このデータは、BrowseCompデータセットの難しさを明確に示しています。トレーナーはデータセットの作成経験がありましたが、ほとんどの質問を数時間以内に解決することができませんでした。一方で、トレーナーは競技レベルのインターネットブラウザーではないため、彼らが諦めた問題の多くは、十分な時間があれば経験豊富な専門家(探偵や調査ジャーナリストなど)によって解決可能である可能性も指摘されています。

4 Evaluation of models
4.1 Performance of OpenAI models
BrowseCompで、様々なモデルを評価しました。これには、ブラウジング機能を持たないモデル(GPT-4o (gpt-4o-2024-08-06)、GPT-4.5 (gpt-4.5-preview-2025-02-27)、OpenAI o1 (o1-2024-12-17-medium reasoning effort))だけでなく、ブラウジング機能を持つGPT-4o (gpt-4o-search-preview-2025-03-11) および、持続的なウェブブラウジングのために明示的に訓練されたエージェントモデルであるOpenAI Deep Research (OpenAI, 2025a) が含まれます。Table3に示すように、GPT-4oとGPT-4.5の精度はほぼゼロであり、このベンチマークの難しさを浮き彫りにしています。強力な推論能力やツール利用能力なしには、BrowseCompが対象とするような、見つけにくい複数のステップを要する事実を検索することはできません。
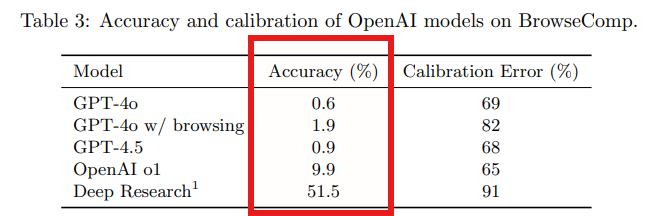
GPT-4oにブラウジング機能を加えることで、精度はわずかに向上しましたが(0.6%から1.9%)、依然として低いままでした。これは、ブラウジングだけでは不十分であり、モデルは戦略的に推論し、関連性の高い検索パスを特定し、検索されたコンテンツを解釈する能力も必要であることを示しています。一方、ブラウジング機能を持たないものの、より強力な推論能力を持つOpenAI o1は、顕著に高い精度を達成しており、BrowseCompの答えの一部は、内部知識からの推論によって見つけられる可能性があることを示唆しています。全体として、これらの結果は、ツール利用と推論の両方がBrowseCompの性能に有意に貢献していることを示しています。
Deep Researchは他のすべてのモデルを大幅に上回り、約半数の問題を解決しました。自律的にウェブを検索し、複数のソースからの情報を評価および統合し、検索戦略を適応させる能力により、他の方法では手に負えない質問を処理できます。大量のオンライン情報を統合し、遭遇した情報に応じて方向転換し、各主張を引用することにより、多数のウェブサイトの閲覧を必要とするニッチで非直感的な質問に特に効果的です。これこそが、BrowseCompが測定するように設計された課題です。なお、Deep Researchモデルは、BrowseCompタスクで優れた性能を発揮するように特別に訓練されたデータで学習されていることに注意してください。
4.2 Calibration Analysis
信頼性の高いエージェントは、正しい答えを生成するだけでなく、自身の不確実性を正確に評価する必要があります。リスクの高い状況や曖昧な情報探索の場面では、過信した誤った答えは特に問題となる可能性があります。この信頼性の側面を評価するために、モデルの予測のキャリブレーション(モデルの確信度が、その答えが正しい可能性をどれだけ反映しているか)を評価しました。この評価の一環として、各応答とともに信頼度スコアを提供するようモデルに求めました(正確なプロンプトは以下の通り)。

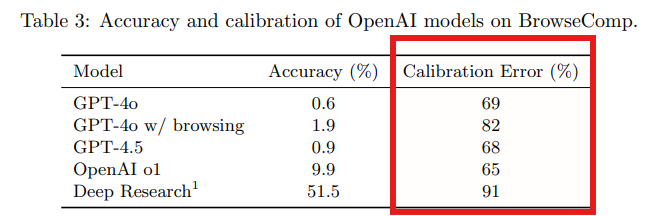
Table3に示すように、ブラウジング機能を持つモデル(ブラウジングありのGPT-4oやDeep Researchなど)は、キャリブレーションエラーが高く、ウェブツールへのアクセスが誤った答えに対するモデルの確信度を高める可能性があることを示唆しています。これは、Deep Researchが信頼度のキャリブレーションに苦労しており、現時点では不確実性を正確に伝えることがしばしばできていないという観察結果 (OpenAI, 2025a) と一致しています。
4.3 Test-time compute scaling
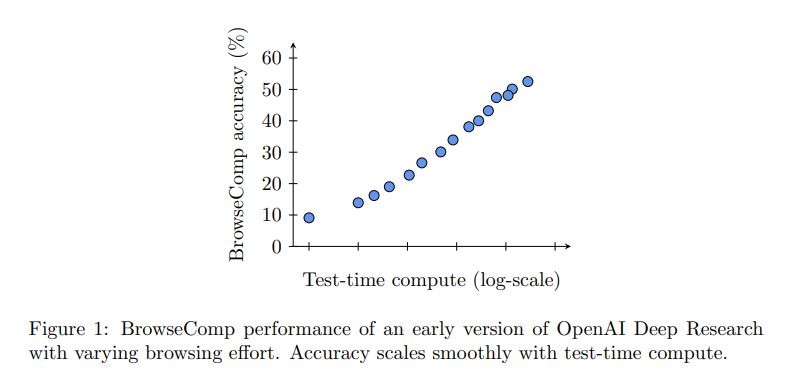
エージェントの重要な特徴は、以前にOpenAI o1がAIMEで、OpenAI o3-mini low/medium/highで示したように、テスト時の計算資源の量に応じて性能が向上することです。同様に、BrowseCompの質問は答えを見つけるために多くのウェブサイトを調べる必要があるため、追加のテスト時の計算資源が性能向上につながることが期待されます。Figure1に示すように、各点は異なるブラウジングの労力で行われた完全な評価実行であり、使用されたテスト時の計算資源の量に応じて性能がスムーズに向上することがわかります。
4.4 Aggregation strategies leveraging additional compute
単一のモデル試行における計算資源の増加による性能向上に加えて、各問題を複数回試行し、様々な戦略を用いて最適な答えを選択することで、Deep Researchモデルの性能がさらに向上するかどうかを評価しました。各質問に対して64個の出力を生成し(それぞれにモデルが割り当てた信頼度スコアが含まれます)、最終的な答えを選択するために、多数決、重み付き投票、Best-of-Nの3つの異なる投票方式を適用しました。
- 多数決: サンプルの中で最も頻繁に出現した答えを選択します。
- 重み付き投票: モデルにゼロショットプロンプトを与え、答えに対する信頼度スコアを付与させ、各投票をその出力に対するモデルの信頼度で重み付けします。
- Best-of-N: すべてのサンプルの中で最も高い信頼度スコアを持つ単一の答えを選択します。
Figure4に示すように、これらの3つの方法はいずれも、単一の試行のみを使用した場合と比較して、性能を15%から25%向上させました。BrowseCompは答えを見つけることよりも検証することの方が容易なベンチマークであるため、モデルが正しい答えを出したときにそれを認識できるはずであり、この大幅な性能向上は予想されていました。これらの方法の中で、Best-of-Nが一貫して最も高い精度を達成しており、Deep Researchは多くの場合、自分の正しい答えを特定できることを示唆しています。前述のように、信頼度スコアは絶対的な意味では十分にキャリブレーションされていませんが、それでも意味のある内部シグナルを反映しています。つまり、モデルはしばしば自分が正しいことを「知って」いますが、その確信度をキャリブレーションされた確率として表現するのに苦労しています。

4.5 Distribution of pass rates
さらなる分析として、タスクの難易度をより深く理解するために、BrowseCompベンチマークの全1,266タスクにおけるDeep ResearchとOpenAI o1のパス率の分布を、質問あたり64回の試行を用いて調べました。Figure6に示すように、Deep Researchはタスクの16%を完全に解決しましたが(パス率100%)、14%では全く正解を出せませんでした(パス率0%)。これは、タスクの難易度に大きな隔たりがあることを示しています。さらに、多くのタスクが両極端の中間に位置しており、タスクの構造やドメインに応じてモデルが苦労する様々な難易度が存在することを示唆しています。
Deep Researchが一度も正解を出せなかった質問のサブセットについて、フォローアップ調査として、正解を与えた上で、それを裏付けるウェブ上の証拠を検索するようモデルに促しました。ほとんどの場合、モデルは成功し、これらの質問が解決不可能なのではなく、単に手掛かりなしでは非常に困難であることを確認しました。これは、多くのBrowseCompタスクが単なる検索以上の能力、つまり戦略的な粘り強さ、柔軟な検索の再構成、そして複数のソースに断片的に存在する手がかりを組み立てる能力を試していることを示唆しています。
実際、BrowseCompには当初1,287のタスクが含まれていました。Deep Researchのパス率が0%であった118のタスクをレビューした結果、ラベル付けされた正解が必要な回答形式と一致しない、表現が曖昧である、または推論に基づいて誤っている21のタスクを特定しました。これらのタスクはデータセットから削除されました。
5 Related work and discussion
インターネットから情報を検索するAIの利用には、長年の関心があります。インターネットからの情報検索というタスクは、IBM Watson (Ferrucci et al., 2010) の初期から自然言語処理コミュニティで関心を集めており、事前学習済み言語モデルの普及に伴い、その関心は高まっています (Guu et al., 2020; Lewis et al., 2020)。人間が10分以内の検索で見つけられるような情報に焦点を当てた過去の研究 (Joshi et al., 2017; Yang et al., 2018; Thorne et al., 2018; Dinan et al., 2019; Lee et al., 2019; Fan et al., 2019; Petroni et al., 2021; Yao et al., 2022; Mialon et al., 2023) と比較して、BrowseCompはウェブ上の見つけにくい、深く絡み合った情報を検索する能力に焦点を当てています。
BrowseCompが評価対象とするモデルクラスは、インターネットへのアクセスを持つモデルです。初期のAIエージェントは、ツール呼び出しの回数が限られており、バックトラックが得意ではないため、このベンチマークでは苦労する可能性があります (Nakano et al., 2021; Menick et al., 2022; Yao et al., 2023; Schick et al., 2023) が、強化学習で訓練されたより最近のバージョンの言語モデルは、BrowseCompで少なくとも2桁のパーセント性能を達成する可能性が高くなっています (Google, 2024; OpenAI, 2025b, a; perplexity.AI, 2025; x.AI, 2025)。BrowseCompでは、トレーナーが主張を裏付けるテキストによる証拠を提供することが求められていましたが、将来のベンチマークでは、画像、ビデオ、音声、またはインタラクティブなウェブページなどの異なるモダリティとのインタラクションによる情報発見能力を評価することも考えられます。
6 Conclusion
結論として、BrowseCompは、モデルがインターネットを粘り強く閲覧し、見つけにくい情報を検索する能力を評価するものです。BrowseCompは、一般的なクエリに対する性能を測定することを目的としていませんが、単一のターゲットとなる情報を見つけ出す能力を測定し、評価が容易であり、既存のブラウジングエージェントにとっては挑戦的です。BrowseCompをオープンソース化することで、より信頼できるAIエージェントの研究が推進されることを期待しており、より多くのAIエージェントの能力を評価し、フィードバックを提供することを研究者に推奨しています。
まとめ
BrowseCompベンチマークは、AIエージェントが複雑なインターネットの海から、目的の情報を粘り強く、そして創造的に見つけ出す能力を測るための重要な一歩です。その難易度の高さは、人間の専門家でさえ容易には解決できないほどであり、既存のAIモデルにとっても大きな挑戦となります。しかし、その一方で、解答の検証は容易であるため、AIモデルの性能を客観的に評価し、今後の研究開発の方向性を示す上で貴重な指標となるでしょう。BrowseCompの登場により、より高度で信頼性の高いブラウジングAIエージェントの実現に向けた研究が加速することが期待されます。








